basecount
Count nucleotides in sequence
Description
Examples
Count Nucleotides in Sequence
Count the bases in a DNA sequence and return the results in a structure.
bases = basecount('TAGCTGGCCAAGCGAGCTTG')bases = struct with fields:
A: 4
C: 5
G: 7
T: 4
Get the number of adenosine (A) bases.
bases.A
ans = 4
Create a bar graph comparing the number of each nucleotide.
basecount('TAGCTGGCCAAGCGAGCTTG',Chart="bar")
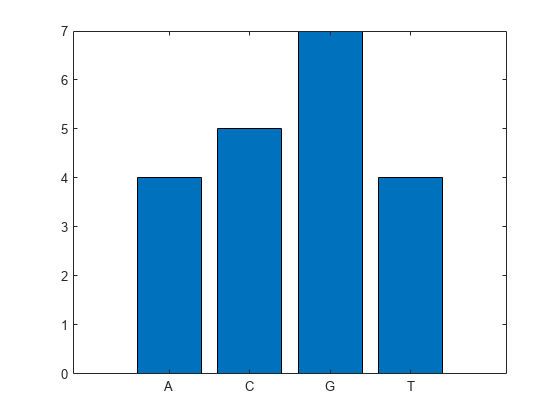
ans = struct with fields:
A: 4
C: 5
G: 7
T: 4
Count the bases in a DNA sequence containing ambiguous characters (R, Y, K, M, S, W, B, D, H, V, or N), listing each of them in a separate field.
basecount('ABCDGGCCAAGCGAGCTTG',Ambiguous="individual")
ans = struct with fields:
A: 4
C: 5
G: 6
T: 2
R: 0
Y: 0
K: 0
M: 0
S: 0
W: 0
B: 1
D: 1
H: 0
V: 0
N: 0
Input Arguments
Output Arguments
Version History
Introduced before R2006a
See Also
aacount | baselookup | codoncount | cpgisland | dimercount | nmercount | ntdensity | seqviewer
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)