collintest
Belsley collinearity diagnostics
Syntax
Description
[ displays, at the command window, Belsley collinearity diagnostics
for assessing the strength and sources of collinearity among variables in the input matrix
of time series data. The function also returns the singular
values in decreasing order, condition indices, and variance decomposition
proportions.sValue,condIdx,VarDecomp]
= collintest(X)
VarDecompTbl = collintest(Tbl)
To select a subset of variables, for which to compute collinearity diagnostics, use
the DataVariables name-value argument.
[___] = collintest(___,
specifies options using one or more name-value arguments in
addition to any of the input argument combinations in previous syntaxes.
Name=Value)collintest returns the output argument combination for the
corresponding input arguments. For example,
collintest(Tbl,Plot="on",Display="off",DataVariables=1:5) plots the
Belslely collinearity diagnostics for the first 5 variables of the table
Tbl to a figure instead of the command window.
collintest(
plots on the axes specified by ax,Plot="on",___)ax instead of
the current axes (gca). ax can precede any of the input
argument combinations in the previous syntaxes.
[___,
plots the diagnostics of the input series and additionally returns handles to plotted
graphics objects h]
= collintest(___,Plot="on")h. Use elements of h to modify
properties of the plot after you create it.
Examples
Compute Belsley Collinearity Diagnostics on Matrix of Data
Display collinearity diagnostics for multiple time series using the default options of collintest. Input the time series data as a numeric matrix.
Load data of Canadian inflation and interest rates Data_Canada.mat, which contains the series in the matrix Data.
load Data_CanadaDisplay the Belsley collinearity diagnostics at the command window. Return the singular values, condition indices, and variance decomposition proportions.
series'
ans = 5x1 cell
{'(INF_C) Inflation rate (CPI-based)' }
{'(INF_G) Inflation rate (GDP deflator-based)'}
{'(INT_S) Interest rate (short-term)' }
{'(INT_M) Interest rate (medium-term)' }
{'(INT_L) Interest rate (long-term)' }
[sValue,condIdx,VarDecomp] = collintest(Data);
Variance Decomposition sValue condIdx Var1 Var2 Var3 Var4 Var5 --------------------------------------------------------- 2.1748 1 0.0012 0.0018 0.0003 0.0000 0.0001 0.4789 4.5413 0.0261 0.0806 0.0035 0.0006 0.0012 0.1602 13.5795 0.3386 0.3802 0.0811 0.0011 0.0137 0.1211 17.9617 0.6138 0.5276 0.1918 0.0004 0.0193 0.0248 87.8245 0.0202 0.0099 0.7233 0.9979 0.9658
Only the last row in the display has a condition index larger than the default tolerance, 30. In this row, the last three variables (in the last three columns) have variance-decomposition proportions exceeding the default tolerance, 0.5. These results suggest that the short-, medium-, and long-term interest rates exhibit multicollinearity.
collintest organizes the outputs in the display table.
sValue
sValue = 5×1
2.1748
0.4789
0.1602
0.1211
0.0248
condIdx
condIdx = 5×1
1.0000
4.5413
13.5795
17.9617
87.8245
VarDecomp
VarDecomp = 5×5
0.0012 0.0018 0.0003 0.0000 0.0001
0.0261 0.0806 0.0035 0.0006 0.0012
0.3386 0.3802 0.0811 0.0011 0.0137
0.6138 0.5276 0.1918 0.0004 0.0193
0.0202 0.0099 0.7233 0.9979 0.9658
Compute Belsley Collinearity Diagnostics on Table Variables
Display and return collinearity diagnostics for multiple time series, which are variables in a table, using default options.
Load data of Canadian inflation and interest rates Data_Canada.mat. Convert the table DataTable to a timetable.
load Data_Canada dates = datetime(dates,ConvertFrom="datenum"); TT = table2timetable(DataTable,RowTimes=dates); TT.Observations = [];
Display the Belsley collinearity diagnostics, using all default options.
VarDecompTbl = collintest(TT)
Variance Decomposition sValue condIdx INF_C INF_G INT_S INT_M INT_L --------------------------------------------------------- 2.1748 1 0.0012 0.0018 0.0003 0.0000 0.0001 0.4789 4.5413 0.0261 0.0806 0.0035 0.0006 0.0012 0.1602 13.5795 0.3386 0.3802 0.0811 0.0011 0.0137 0.1211 17.9617 0.6138 0.5276 0.1918 0.0004 0.0193 0.0248 87.8245 0.0202 0.0099 0.7233 0.9979 0.9658
VarDecompTbl=5×7 table
sValue condIdx INF_C INF_G INT_S INT_M INT_L
________ _______ _________ _________ __________ __________ __________
2.1748 1 0.0012446 0.0017784 0.00033202 4.2326e-05 8.0328e-05
0.47889 4.5413 0.0261 0.080594 0.0034869 0.00057749 0.001159
0.16015 13.579 0.33864 0.38021 0.081126 0.0011166 0.013662
0.12108 17.962 0.61384 0.52756 0.19176 0.00035545 0.019308
0.024763 87.825 0.020173 0.0098575 0.72329 0.99791 0.96579
collintest returns collinearity diagnostics in the table VarDecompTbl, where variables correspond to the singular values, condition indices, and variance-decomposition proportions of each variable in the data (sValue, condIdx, and VarDecomp). The command window display and output table have a similar form.
By default, collintest computes collinearity diagnostics for all variables in the input table. To select a subset of variables from an input table, set the DataVariables option.
Extract the variance-decomposition proportions from the output table.
varnames = DataTable.Properties.VariableNames; VarDecomp = VarDecompTbl(:,varnames)
VarDecomp=5×5 table
INF_C INF_G INT_S INT_M INT_L
_________ _________ __________ __________ __________
0.0012446 0.0017784 0.00033202 4.2326e-05 8.0328e-05
0.0261 0.080594 0.0034869 0.00057749 0.001159
0.33864 0.38021 0.081126 0.0011166 0.013662
0.61384 0.52756 0.19176 0.00035545 0.019308
0.020173 0.0098575 0.72329 0.99791 0.96579
Plot Belsley Collinearity Diagnostics
Plot collinearity diagnostics for all time series in a table.
Load data of Canadian inflation and interest rates Data_Canada.mat.
load Data_CanadaPlot the Belsley collinearity diagnostics for all series.
collintest(DataTable,Plot="on");Variance Decomposition sValue condIdx INF_C INF_G INT_S INT_M INT_L --------------------------------------------------------- 2.1748 1 0.0012 0.0018 0.0003 0.0000 0.0001 0.4789 4.5413 0.0261 0.0806 0.0035 0.0006 0.0012 0.1602 13.5795 0.3386 0.3802 0.0811 0.0011 0.0137 0.1211 17.9617 0.6138 0.5276 0.1918 0.0004 0.0193 0.0248 87.8245 0.0202 0.0099 0.7233 0.9979 0.9658
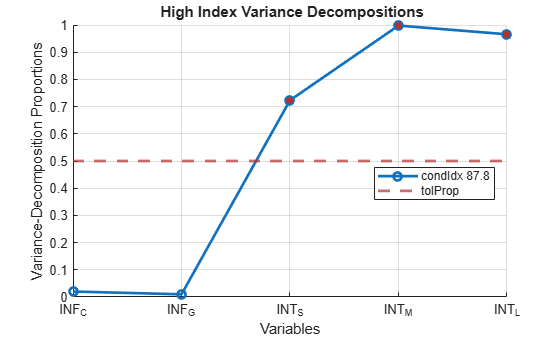
The plot corresponds to the values in the last row of the variance-decomposition proportions, which are the only proportions with a condition index larger than the default tolerance of 30. The interest rate series have variance-decomposition proportions exceeding the default tolerance of 0.5 (red markers in the plot).
Plot Belsley Collinearity Diagnostics for Selected Variables and Intercept
Compute collinearity diagnostics for selected time series and an intercept.
Load the credit default data set Data_CreditDefaults.mat. The table DataTable contains the default rate of investment-grade corporate bonds series (IGD, the response variable) and several predictor variables.
load Data_CreditDefaultsConsider a multiple regression model for the default rate that includes an intercept term.
Include a variable in the table of data that represents the intercept in the design matrix (that is, a column of ones). Place the intercept variable at the beginning of the table.
Const = ones(height(DataTable),1); DataTable = addvars(DataTable,Const,Before=1);
Create a variable that contains all predictor variable names.
varnames = DataTable.Properties.VariableNames;
prednames = varnames(varnames ~= "IGD");Graph a correlation plot of all predictor variables except for the intercept dummy variable.
figure corrplot(DataTable,DataVariables=prednames(2:end), ... TestR="on");
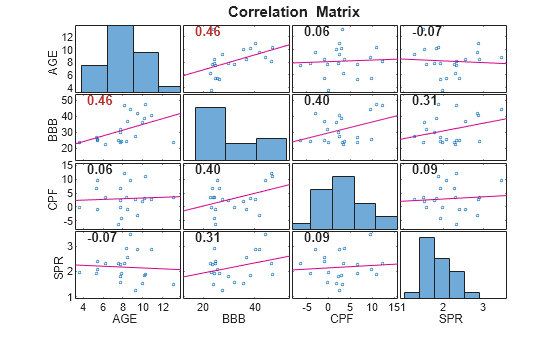
The predictor BBB is moderately linearly associated with the other predictors, while all other predictors appear unassociated with each other.
Plot the Belsley collinearity diagnostics of the predictor variables. Adjust the following options for the collinearity diagnostics:
Set the condition index tolerance to 10.
Set the variance-decomposition proportion tolerance to 0.5.
figure collintest(DataTable,Plot="on",DataVariables=prednames, ... TolIdx=10,TolProp=0.5);
Variance Decomposition sValue condIdx Const AGE BBB CPF SPR --------------------------------------------------------- 2.0605 1 0.0015 0.0024 0.0020 0.0140 0.0025 0.8008 2.5730 0.0016 0.0025 0.0004 0.8220 0.0023 0.2563 8.0400 0.0037 0.3208 0.0105 0.0004 0.3781 0.1710 12.0464 0.2596 0.0950 0.8287 0.1463 0.0001 0.1343 15.3405 0.7335 0.5793 0.1585 0.0173 0.6170
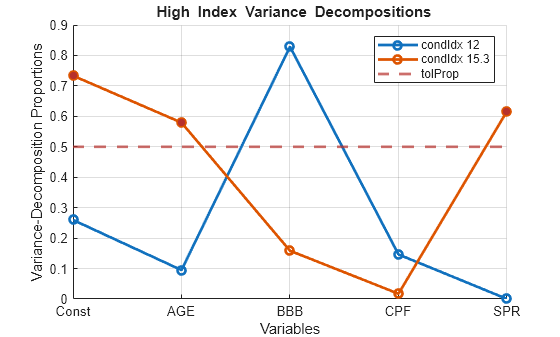
The row associated with condition index 12 (row 4) has one predictor (BBB) with a proportion above the tolerance 0.5, but collinearity requires two or more predictors for a dependency.
The row associated with condition index 15.3 (row 5) shows a weak dependence involving AGE, SPR, and the intercept, which the correlation plot does not expose.
Input Arguments
Output Arguments
More About
Tips
For purposes of collinearity diagnostics, Belsley [1] shows that column scaling of the design matrix composed of the input time series data is always desirable. However, he also shows that centering the data in
Xis undesirable. For models with an intercept, if you center the data inX, the role of the constant term in any near dependency is hidden, and yields misleading diagnostics.Tolerances for identifying large condition indices and variance-decomposition proportions are comparable to critical values in standard hypothesis tests. Experience determines the most useful tolerance, but experiments suggest the
collintestdefaults are good starting points [1].
References
[1] Belsley, D. A., E. Kuh, and R. E. Welsh. Regression Diagnostics. New York, NY: John Wiley & Sons, Inc., 1980.
[2] Judge, G. G., W. E. Griffiths, R. C. Hill, H. Lϋtkepohl, and T. C. Lee. The Theory and Practice of Econometrics. New York, NY: John Wiley & Sons, Inc., 1985.
Version History
Introduced in R2012aYou can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)