centrality
Measure node importance
Description
C = centrality(___,Name,Value)centrality(G,'closeness','Cost',c) specifies the cost of
traversing each edge.
Examples
Page Rank of 6 Websites
Create and plot a graph containing six fictitious websites.
s = [1 1 2 2 3 3 3 4 5];
t = [2 5 3 4 4 5 6 1 1];
names = {'http://www.example.com/alpha', 'http://www.example.com/beta', ...
'http://www.example.com/gamma', 'http://www.example.com/delta', ...
'http://www.example.com/epsilon', 'http://www.example.com/zeta'};
G = digraph(s,t,[],names);
plot(G,'NodeLabel',{'alpha','beta','gamma','delta','epsilon','zeta'})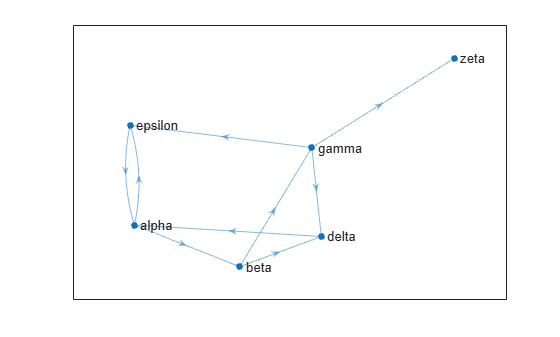
Calculate the page rank of each website using the centrality function. Append this information to the Nodes table of the graph as an attribute of the graph nodes.
pg_ranks = centrality(G,'pagerank')pg_ranks = 6×1
0.3210
0.1706
0.1066
0.1368
0.2008
0.0643
G.Nodes.PageRank = pg_ranks; G.Nodes
ans=6×2 table
Name PageRank
__________________________________ ________
{'http://www.example.com/alpha' } 0.32098
{'http://www.example.com/beta' } 0.17057
{'http://www.example.com/gamma' } 0.10657
{'http://www.example.com/delta' } 0.13678
{'http://www.example.com/epsilon'} 0.20078
{'http://www.example.com/zeta' } 0.06432
Also determine which nodes are hubs and authorities using centrality and append the scores to the Nodes table.
hub_ranks = centrality(G,'hubs'); auth_ranks = centrality(G,'authorities'); G.Nodes.Hubs = hub_ranks; G.Nodes.Authorities = auth_ranks;
G.Nodes
ans=6×4 table
Name PageRank Hubs Authorities
__________________________________ ________ __________ ___________
{'http://www.example.com/alpha' } 0.32098 0.24995 7.3237e-05
{'http://www.example.com/beta' } 0.17057 0.24995 0.099993
{'http://www.example.com/gamma' } 0.10657 0.49991 0.099993
{'http://www.example.com/delta' } 0.13678 9.1536e-05 0.29998
{'http://www.example.com/epsilon'} 0.20078 9.1536e-05 0.29998
{'http://www.example.com/zeta' } 0.06432 0 0.19999
Degree Centrality of Random Graph
Create and plot a weighted graph using a random sparse adjacency matrix. Since there are a lot of edges, use a very small value for EdgeAlpha to make the edges mostly transparent.
A = sprand(1000,1000,0.15); A = A + A'; G = graph(A,'omitselfloops'); p = plot(G,'Layout','force','EdgeAlpha',0.005,'NodeColor','r');

Calculate the degree centrality of each node. Specify the importance of each edge using the edge weights.
deg_ranks = centrality(G,'degree','Importance',G.Edges.Weight);
Use discretize to place the nodes into 7 equally-spaced bins based on their centrality scores.
edges = linspace(min(deg_ranks),max(deg_ranks),7); bins = discretize(deg_ranks,edges);
Make the size of each node in the plot proportional to its centrality score. The marker size of each node is equal to the bin number (1-7).
p.MarkerSize = bins;

Closeness and Betweenness of Minnesota Roads
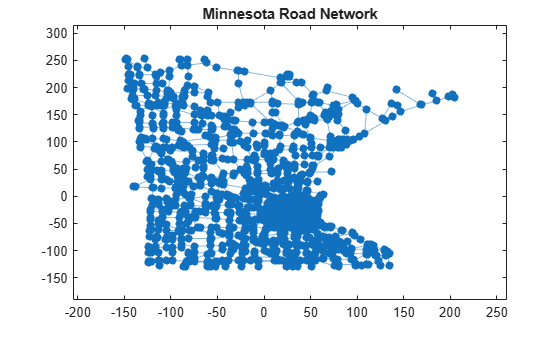
Load the data in minnesota.mat, which contains a graph object G representing the network of roads in Minnesota. The graph nodes have xy coordinates contained in the XCoord and YCoord variables of the G.Nodes table.
load minnesota.mat
xy = [G.Nodes.XCoord G.Nodes.YCoord];Add edge weights to the graph that roughly correspond to the length of the roads, calculated using the Euclidean distance between the xy coordinates of the end nodes of each edge.
[s,t] = findedge(G); G.Edges.Weight = hypot(xy(s,1)-xy(t,1), xy(s,2)-xy(t,2));
Plot the graph using the xy coordinates for the nodes.
p = plot(G,'XData',xy(:,1),'YData',xy(:,2),'MarkerSize',5); title('Minnesota Road Network')
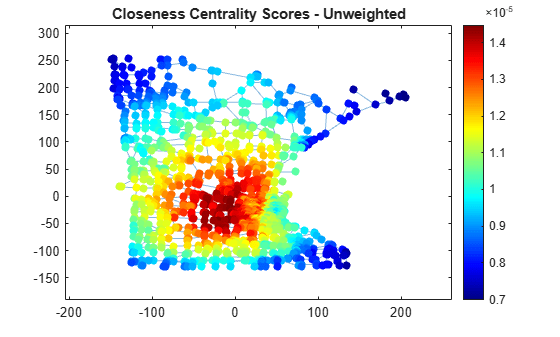
Compute the closeness centrality of each node. Scale the node color NodeCData to be proportional to the centrality score.
ucc = centrality(G,'closeness'); p.NodeCData = ucc; colormap jet colorbar title('Closeness Centrality Scores - Unweighted')
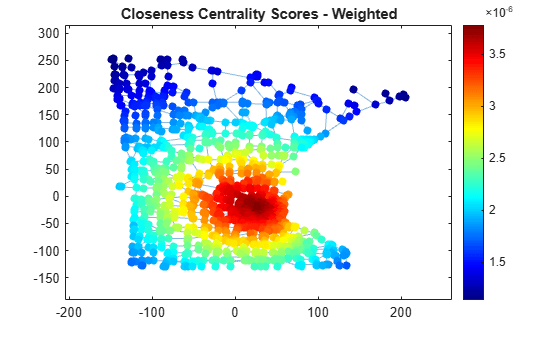
Also compute the weighted closeness centrality score, using the edge weights as the cost of traversing each edge. Using the road lengths as edge weights improves the score quality, since distances are now measured as the sum of the lengths of all traveled edges, rather than the number of edges traveled.
wcc = centrality(G,'closeness','Cost',G.Edges.Weight); p.NodeCData = wcc; title('Closeness Centrality Scores - Weighted')
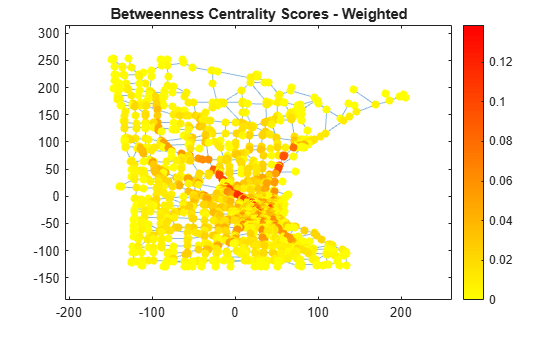
Compute the weighted betweenness centrality scores for the graph to determine the roads most often found on the shortest path between two nodes. Normalize the centrality scores with the factor so that the score represents the probability that a traveler along a shortest path between two random nodes will travel through a given node. The plot indicates that there are a few very important roads leading into and out of the city.
wbc = centrality(G,'betweenness','Cost',G.Edges.Weight); n = numnodes(G); p.NodeCData = 2*wbc./((n-2)*(n-1)); colormap(flip(autumn,1)); title('Betweenness Centrality Scores - Weighted')
Input Arguments
Output Arguments
Extended Capabilities
Version History
Introduced in R2016a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)