sim
Simulate neural network
Syntax
[Y,Xf,Af] = sim(net,X,Xi,Ai,T)
[Y,Xf,Af] = sim(net,{Q TS},Xi,Ai)
[Y,...] = sim(net,...,'useParallel',...)
[Y,...]
= sim(net,...,'useGPU',...)
[Y,...] = sim(net,...,'showResources',...)
[Ycomposite,...] = sim(net,Xcomposite,...)
[Ygpu,...] = sim(net,Xgpu,...)
To Get Help
Type help network/sim.
Description
sim simulates neural networks.
[Y,Xf,Af] = sim(net,X,Xi,Ai,T) takes
net | Network |
X | Network inputs |
Xi | Initial input delay conditions (default = zeros) |
Ai | Initial layer delay conditions (default = zeros) |
T | Network targets (default = zeros) |
and returns
Y | Network outputs |
Xf | Final input delay conditions |
Af | Final layer delay conditions |
sim is usually called implicitly by calling the neural network as a
function. For instance, these two expressions return the same result:
y = sim(net,x,xi,ai) y = net(x,xi,ai)
Note that arguments Xi, Ai, Xf,
and Af are optional and need only be used for networks that have input or
layer delays.
The signal arguments can have two formats: cell array or matrix.
The cell array format is easiest to describe. It is most convenient for networks with multiple inputs and outputs, and allows sequences of inputs to be presented:
X |
| Each element |
Xi |
| Each element |
Ai |
| Each element |
T |
| Each element |
Y |
| Each element |
Xf |
| Each element |
Af |
| Each element |
where
Ni | = | net.numInputs |
Nl | = | net.numLayers |
No | = | net.numOutputs |
ID | = | net.numInputDelays |
LD | = | net.numLayerDelays |
TS | = | Number of time steps |
Q | = | Batch size |
Ri | = | net.inputs{i}.size |
Si | = | net.layers{i}.size |
Ui | = | net.outputs{i}.size |
The columns of Xi, Ai, Xf, and
Af are ordered from oldest delay condition to most recent:
Xi{i,k} | = | Input |
Xf{i,k} | = | Input |
Ai{i,k} | = | Layer output |
Af{i,k} | = | Layer output |
The matrix format can be used if only one time step is to be simulated (TS
= 1). It is convenient for networks with only one input and output, but can also
be used with networks that have more.
Each matrix argument is found by storing the elements of the corresponding cell array argument in a single matrix:
X |
|
Xi |
|
Ai |
|
T |
|
Y |
|
Xf |
|
Af |
|
[Y,Xf,Af] = sim(net,{Q TS},Xi,Ai) is used for networks that do not
have an input when cell array notation is used.
[Y,...] = sim(net,...,'useParallel',...),
[Y,...]
= sim(net,...,'useGPU',...), or
[Y,...] = sim(net,...,'showResources',...) (or the network called as a
function) accepts optional name/value pair arguments to control how calculations are performed.
Two of these options allow training to happen faster or on larger datasets using parallel
workers or GPU devices if Parallel Computing Toolbox is available. These are the optional
name/value pairs:
'useParallel','no' | Calculations occur on normal MATLAB thread. This is the default
|
'useParallel','yes' | Calculations occur on parallel workers if a parallel pool is open. Otherwise calculations occur on the normal MATLAB thread. |
'useGPU','no' | Calculations occur on the CPU. This is the default 'useGPU' setting. |
'useGPU','yes' | Calculations occur on the current gpuDevice if it is a supported GPU (See
Parallel Computing Toolbox for GPU requirements.) If the current gpuDevice is not
supported, calculations remain on the CPU. If |
'useGPU','only' | If no parallel pool is open, then this setting is the same as
|
'showResources','no' | Do not display computing resources used at the command line. This is the default setting. |
'showResources','yes' | Show at the command line a summary of the computing resources actually used. The actual resources may differ from the requested resources, if parallel or GPU computing is requested but a parallel pool is not open or a supported GPU is not available. When parallel workers are used, each worker’s computation mode is described, including workers in the pool that are not used. |
[Ycomposite,...] = sim(net,Xcomposite,...) takes Composite data and
returns Composite results. If Composite data is used, then 'useParallel' is
automatically set to 'yes'.
[Ygpu,...] = sim(net,Xgpu,...) takes gpuArray data and returns
gpuArray results. If gpuArray data is used, then 'useGPU' is automatically
set to 'yes'.
Examples
In the following examples, the sim function is called implicitly by
calling the neural network object (net) as a function.
Simulate Feedforward Networks
This example loads a dataset that maps anatomical measurements x to body fat percentages t. A feedforward network with 10 neurons is created and trained on that data, then simulated.
[x,t] = bodyfat_dataset; net = feedforwardnet(10); net = train(net,x,t);
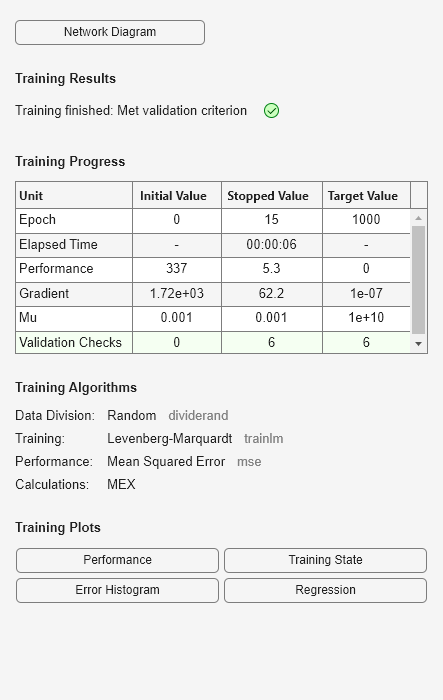
y = net(x);
Simulate NARX Time Series Networks
This example trains an open-loop nonlinear-autoregressive network with external input, to
model a levitated magnet system defined by a control current x and the
magnet’s vertical position response t, then simulates the network. The
function preparets prepares the data before training and
simulation. It creates the open-loop network’s combined inputs xo, which
contains both the external input x and previous values of position
t. It also prepares the delay states xi.
[x,t] = maglev_dataset;
net = narxnet(10);
[xo,xi,~,to] = preparets(net,x,{},t);
net = train(net,xo,to,xi);
y = net(xo,xi)This same system can also be simulated in closed-loop form.
netc = closeloop(net);
view(netc)
[xc,xi,ai,tc] = preparets(netc,x,{},t);
yc = netc(xc,xi,ai);Simulate in Parallel on a Parallel Pool
With Parallel Computing Toolbox you can simulate and train networks faster and on larger datasets than can fit on one PC. Here training and simulation happens across parallel MATLAB workers.
parpool [X,T] = vinyl_dataset; net = feedforwardnet(10); net = train(net,X,T,'useParallel','yes','showResources','yes'); Y = net(X,'useParallel','yes');
Simulate on GPUs
Use Composite values to distribute the data manually, and get back the results as a Composite value. If the data is loaded as it is distributed, then while each piece of the dataset must fit in RAM, the entire dataset is limited only by the total RAM of all the workers.
Xc = Composite;
for i=1:numel(Xc)
Xc{i} = X+rand(size(X))*0.1; % Use real data instead of random
end
Yc = net(Xc,'showResources','yes');Networks can be simulated using the current GPU device, if it is supported by Parallel Computing Toolbox.
gpuDevice % Check if there is a supported GPU Y = net(X,'useGPU','yes','showResources','yes');
To put the data on a GPU manually, and get the results on the GPU:
Xgpu = gpuArray(X); Ygpu = net(Xgpu,'showResources','yes'); Y = gather(Ygpu);
To run in parallel, with workers associated with unique GPUs taking advantage of that hardware, while the rest of the workers use CPUs:
Y = net(X,'useParallel','yes','useGPU','yes','showResources','yes');
Using only workers with unique GPUs might result in higher speeds, as CPU workers might not keep up.
Y = net(X,'useParallel','yes','useGPU','only','showResources','yes');
Algorithms
sim uses these properties to simulate a network
net.
net.numInputs, net.numLayers net.outputConnect, net.biasConnect net.inputConnect, net.layerConnect
These properties determine the network’s weight and bias values and the number of delays associated with each weight:
net.IW{i,j}
net.LW{i,j}
net.b{i}
net.inputWeights{i,j}.delays
net.layerWeights{i,j}.delays
These function properties indicate how sim applies weight and bias
values to inputs to get each layer’s output:
net.inputWeights{i,j}.weightFcn
net.layerWeights{i,j}.weightFcn
net.layers{i}.netInputFcn
net.layers{i}.transferFcn
Version History
Introduced before R2006a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)