solvepdeeig
Solve PDE eigenvalue problem specified in a PDEModel
Description
result = solvepdeeig(model,evr)model for eigenvalues in
the range evr. If the range does not contain any eigenvalues,
solvepdeeig returns an EigenResults object with the empty EigenVectors,
EigenValues, and Mesh properties.
Examples
Solve an Eigenvalue Problem With 3-D Geometry
Solve for several vibrational modes of the BracketTwoHoles geometry.
The equations of elasticity have three components. Therefore, create a PDE model that has three components. Import and view the BracketTwoHoles geometry.
model = createpde(3); importGeometry(model,"BracketTwoHoles.stl"); pdegplot(model,"FaceLabels","on","FaceAlpha",0.4)
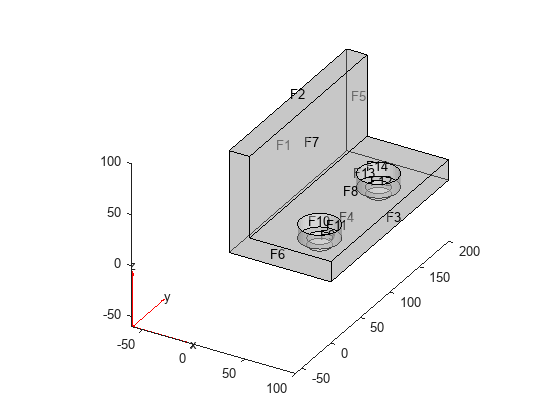
Set F1, the rear face, to have zero deflection.
applyBoundaryCondition(model,"dirichlet","Face",1,"u",[0;0;0]);
Set the model coefficients to represent a steel bracket. For details, see Linear Elasticity Equations. When specifying the f-coefficient, assume that all body forces are zero.
E = 200e9; % elastic modulus of steel in Pascals nu = 0.3; % Poisson's ratio specifyCoefficients(model,"m",0,... "d",1,... "c",elasticityC3D(E,nu),... "a",0,... "f",[0;0;0]);
Find the eigenvalues up to 1e7.
evr = [-Inf,1e7];
Mesh the model and solve the eigenvalue problem.
generateMesh(model); results = solvepdeeig(model,evr);
How many results did solvepdeeig return?
length(results.Eigenvalues)
ans = 3
Plot the solution on the geometry boundary for the lowest eigenvalue.
V = results.Eigenvectors; subplot(2,2,1) pdeplot3D(model,"ColorMapData",V(:,1,1)) title("x Deflection, Mode 1") subplot(2,2,2) pdeplot3D(model,"ColorMapData",V(:,2,1)) title("y Deflection, Mode 1") subplot(2,2,3) pdeplot3D(model,"ColorMapData",V(:,3,1)) title("z Deflection, Mode 1")
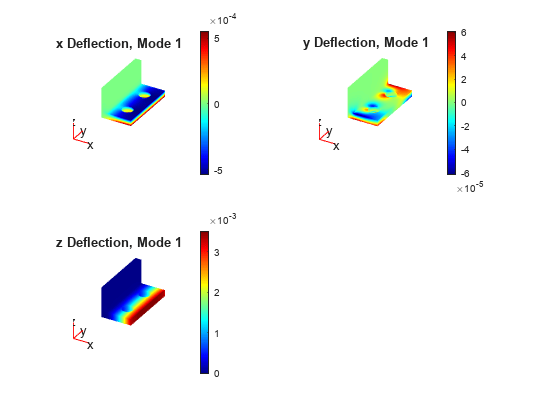
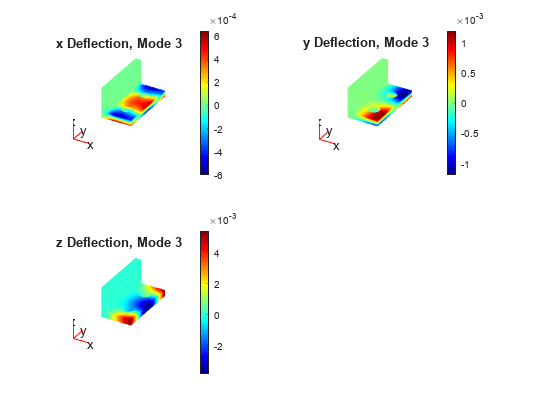
Plot the solution for the highest eigenvalue.
figure subplot(2,2,1) pdeplot3D(model,"ColorMapData",V(:,1,3)) title("x Deflection, Mode 3") subplot(2,2,2) pdeplot3D(model,"ColorMapData",V(:,2,3)) title("y Deflection, Mode 3") subplot(2,2,3) pdeplot3D(model,"ColorMapData",V(:,3,3)) title("z Deflection, Mode 3")
Input Arguments
Output Arguments
Tips
The equation coefficients cannot depend on the solution
uor its gradient.
Version History
Introduced in R2016a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)