ecdf
Empirical cumulative distribution function
Description
[
specifies additional options using one or more name-value arguments. For example,
f,x]
= ecdf(y,Name,Value)'Function','survivor'f as a survivor function.
ecdf(___) produces a stairstep graph of
the evaluated function. The function visualizes interval estimates for interval-censored
data using shaded rectangles. You can specify
'Bounds','on'
Examples
Compute Empirical cdf
Compute the Kaplan-Meier estimate of the empirical cumulative distribution function (cdf) for simulated survival data.
Generate survival data from a Weibull distribution with parameters 3 and 1.
rng('default') % For reproducibility failuretime = random('wbl',3,1,15,1);
Compute the Kaplan-Meier estimate of the empirical cdf for survival data.
[f,x] = ecdf(failuretime); [f,x]
ans = 16×2
0 0.0895
0.0667 0.0895
0.1333 0.1072
0.2000 0.1303
0.2667 0.1313
0.3333 0.2718
0.4000 0.2968
0.4667 0.6147
0.5333 0.6684
0.6000 1.3749
⋮
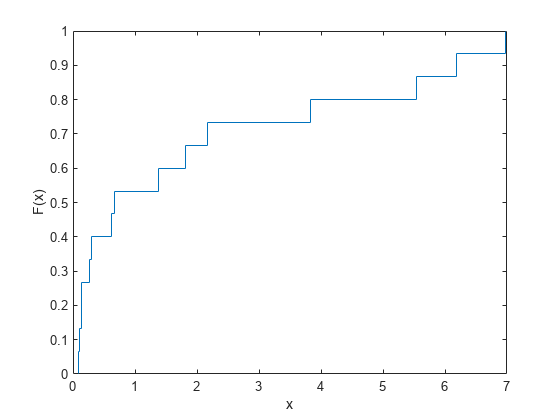
Plot the estimated empirical cdf.
ecdf(failuretime)
Compare Empirical cdf with Known cdf
Generate right-censored survival data and compare the empirical cumulative distribution function (cdf) with the known cdf.
Generate failure times from an exponential distribution with a mean failure time of 15.
rng('default') % For reproducibility y = exprnd(15,75,1);
Generate drop-out times from an exponential distribution with a mean failure time of 30.
d = exprnd(30,75,1);
Generate the observed failure times, that is, the minimum of the generated failure times and the drop-out times.
t = min(y,d);
Create a logical array containing generated failure times that are larger than the drop-out times. The data for which this condition is true is censored.
censored = (y>d);
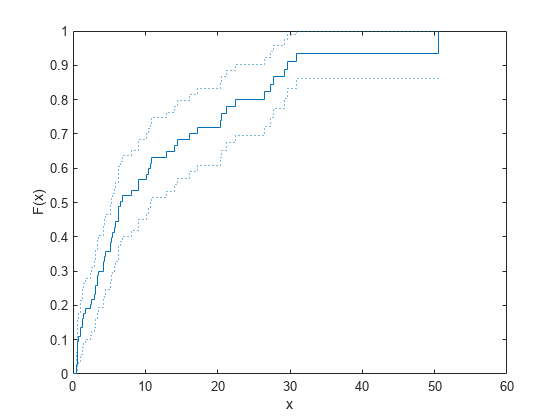
Compute the empirical cdf and confidence bounds.
[f,x,flo,fup] = ecdf(t,'Censoring',censored);Plot the empirical cdf and confidence bounds.
ecdf(t,'Censoring',censored,'Bounds','on') hold on
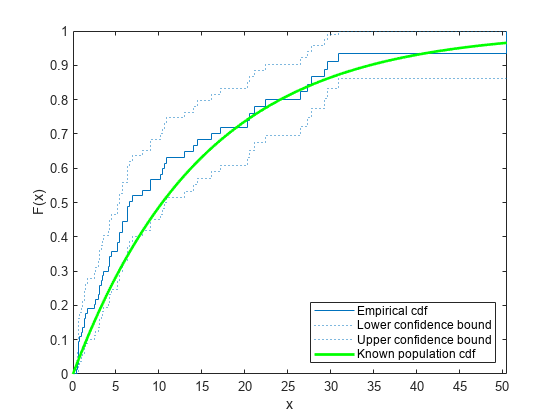
Superimpose a plot of the known population cdf.
xx = 0:.1:max(t); yy = 1-exp(-xx/15); plot(xx,yy,'g-','LineWidth',2) axis([0 max(t) 0 1]) legend('Empirical cdf','Lower confidence bound', ... 'Upper confidence bound','Known population cdf', ... 'Location','southeast') hold off
Plot Empirical Survivor Function with Confidence Bounds
Generate survival data and plot the empirical survivor function with 99% confidence bounds.
Generate lifetime data from a Weibull distribution with parameters 100 and 2.
rng('default') % For reproducibility R = wblrnd(100,2,100,1);
Plot the empirical survivor function for the data with 99% confidence bounds.
ecdf(R,'Function','survivor','Alpha',0.01,'Bounds','on') hold on
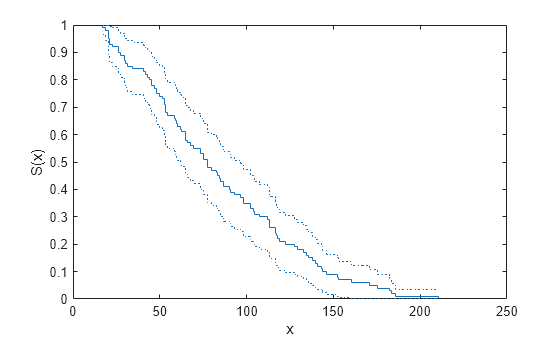
Superimpose a plot of the Weibull survivor function.
x = 1:1:250; wblsurv = 1-cdf('weibull',x,100,2); plot(x,wblsurv,'g-','LineWidth',2) legend('Empirical survivor function','Lower confidence bound', ... 'Upper confidence bound','Weibull survivor function', ... 'Location','northeast')
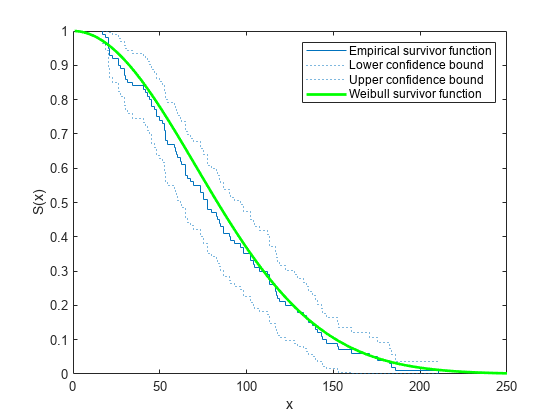
The Weibull survivor function based on the actual distribution is within the confidence bounds.
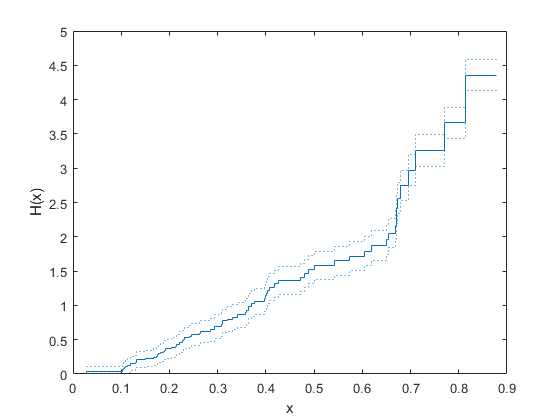
Empirical Cumulative Hazard Function of Double-Censored Data
Compute and plot the cumulative hazard function of simulated double-censored survival data.
Generate failure times from a Birnbaum-Saunders distribution.
rng('default') % For reproducibility failuretime = random('BirnbaumSaunders',0.3,1,[100,1]);
Assume that the study starts at time 0.1 and the ends at time 0.9. The assumption implies that failure times less than 0.1 are left censored, and failure times greater than 0.9 are right censored.
Create a vector in which each element indicates the censorship status of the corresponding observation in failuretime. Use –1, 1, and 0 to indicate left-censored, right-censored, and fully observed observations, respectively.
L = 0.1; U = 0.9; left_censored = (failuretime<L); right_censored = (failuretime>U); c = right_censored - left_censored;
Plot the empirical cumulative hazard function for the data with 95% confidence bounds.
ecdf(failuretime,'Function','cumulative hazard', ... 'Censoring',c,'Bounds','on')
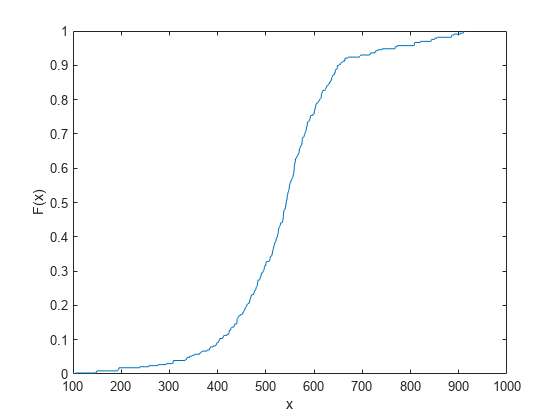
Empirical cdf of Interval-Censored Data
Compute and plot the empirical cdf of interval-censored data.
Load the cities data set. The data includes ratings for nine different indicators of the quality of life in 329 US cities: climate, housing, health, crime, transportation, education, arts, recreation, and economics. For each indicator, a higher rating is better.
load citiesSelect the first indicator (climate) as sample data.
Y = ratings(:,1);
Assume that the indicators in Y are the values rounded to the nearest integer. Then, you can treat values in Y as interval-censored observations. An observation y in Y indicates that the actual rating is between y–0.5 and y+0.5.
Create a matrix in which each row represents the interval surrounding each integer in Y.
intervalY = [Y-0.5, Y+0.5];
Compute the empirical cdf values.
[f,x] = ecdf(intervalY);
Plot the empirical cdf values.
figure ecdf(intervalY)
Zoom into a smaller region to see the interval estimates.
idx_roi = 21:30; xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
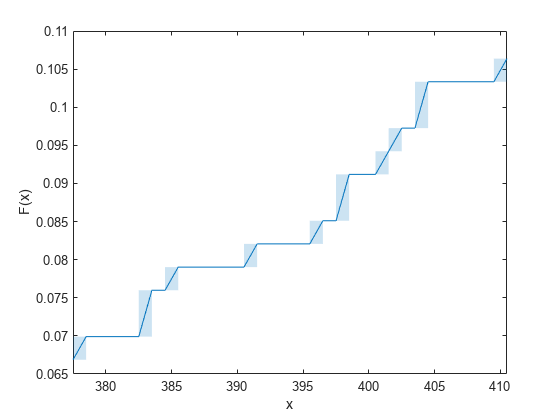
Display the corresponding x and f values.
table(idx_roi',x(idx_roi,:),f(idx_roi,:), ... 'VariableNames',{'Index','x','Empirical cdf F(x)'})
ans=10×3 table
Index x Empirical cdf F(x)
_____ ______________ __________________
21 377.5 378.5 0.069909
22 382.5 383.5 0.075988
23 384.5 385.5 0.079027
24 390.5 391.5 0.082067
25 395.5 396.5 0.085106
26 397.5 398.5 0.091185
27 400.5 401.5 0.094225
28 401.5 402.5 0.097264
29 403.5 404.5 0.10334
30 409.5 410.5 0.10638
The shaded rectangles indicate the change of empirical cdf values F(x) within the corresponding intervals. For example, the second shaded rectangle from the left in the zoomed plot corresponds to the interval (382.5,383.5]. F(382.5) is 0.075988, F(383.5) is 0.079027, and the change from 0.075988 to 0.079027 occurs in the interval (382.5,383.5]. The exact timing of the change is uncertain.
You can plot the interval estimates in different ways. If you assume that the probability change occurs at the start of each interval, you can plot the F(x) values using the first column of x.
figure stairs(x(:,1),f) title('Probability changes at the start') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
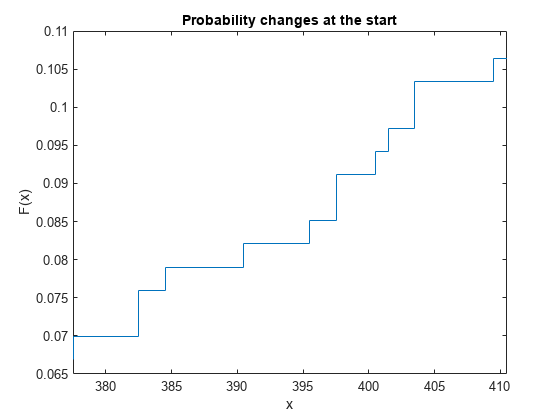
Alternatively, you can plot the F(x) values using the second column of x with the assumption that the probability change occurs at the end of each interval.
figure stairs(x(:,2),f) title('Probability changes at the end') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
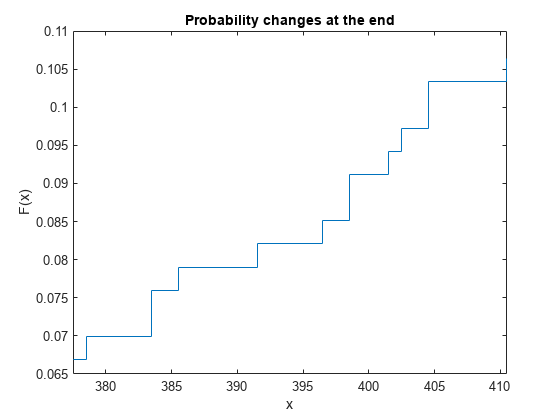
Combine the previous two plots to visualize the intervals.
figure stairs(x(:,1),f) hold on stairs(x(:,2),f) title('Probability changes in the interval') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)]) hold off
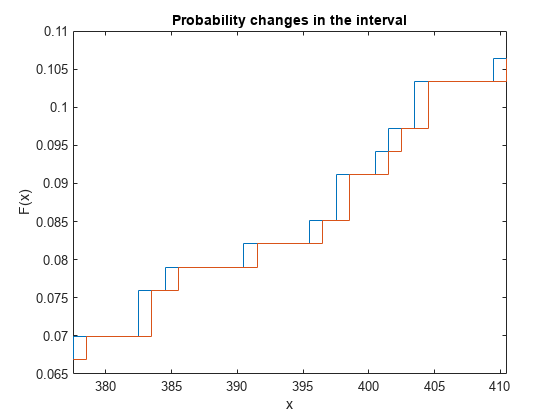
Create Piecewise Linear Distribution Object from Empirical cdf
Compute the empirical cumulative distribution function (cdf) for data, and create a piecewise linear distribution object using an approximation to the empirical cdf.
Load the sample data. Visualize the patient weight data using a histogram.
load patients histogram(Weight(strcmp(Gender,'Female'))) hold on histogram(Weight(strcmp(Gender,'Male'))) legend('Female','Male')
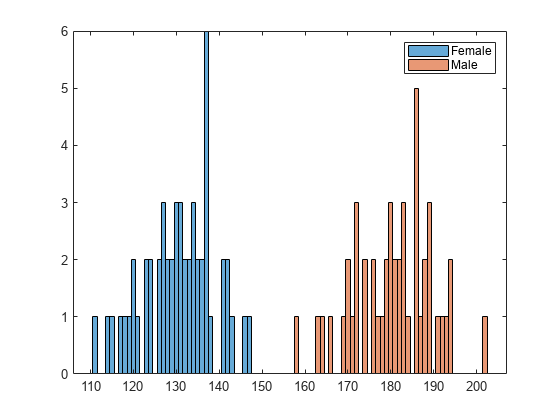
The histogram shows that the data has two modes, one for female patients and one for male patients.
Compute the empirical cdf for the data.
[f,x] = ecdf(Weight);
Construct a piecewise linear approximation to the empirical cdf by taking a value every five points.
f = f(1:5:end); x = x(1:5:end);
Plot the empirical cdf and the approximation.
figure ecdf(Weight) hold on plot(x,f,'ko-','MarkerFace','r') legend('Empirical cdf','Piecewise linear approximation', ... 'Location','best')
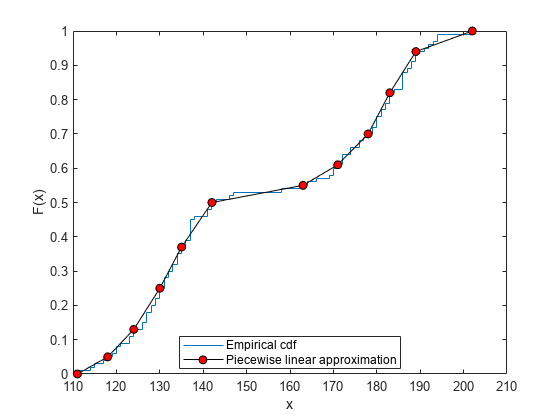
Create a piecewise linear probability distribution object using the piecewise approximation of the empirical cdf.
pd = makedist('PiecewiseLinear','x',x,'Fx',f)
pd = PiecewiseLinearDistribution F(111) = 0 F(118) = 0.05 F(124) = 0.13 F(130) = 0.25 F(135) = 0.37 F(142) = 0.5 F(163) = 0.55 F(171) = 0.61 F(178) = 0.7 F(183) = 0.82 F(189) = 0.94 F(202) = 1
Generate 100 random numbers from the distribution.
rng('default') % For reproducibility rw = random(pd,[100,1]);
Plot the random numbers to visually compare their distribution to the original data.
figure histogram(Weight) hold on histogram(rw) legend('Original data','Generated data')
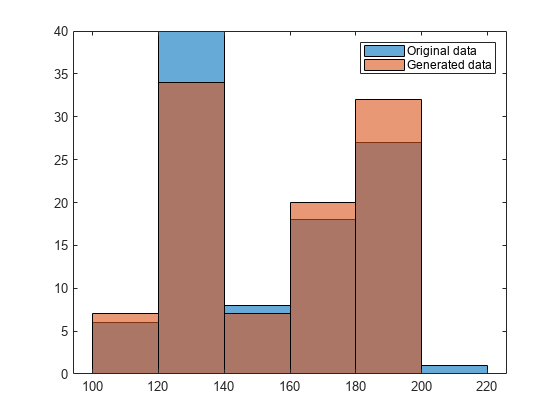
The random numbers generated from the piecewise linear distribution have the same bimodal distribution as the original data.
Input Arguments
Output Arguments
More About
Algorithms
ecdf computes the function values (f) and the
confidence bounds (flo and fup) using different
algorithms, depending on the censorship information. The function type of
f can be the cdf (default), Survivor Function, or Cumulative Hazard Function, as specified by the
Function name-value argument.
| Censorship Type | Algorithm for f | Algorithm for flo and fup |
|---|---|---|
| Right-censored data, which contains fully observed or right-censored observations |
| Use Greenwood’s formula, which is an approximation for the variance of the Kaplan-Meier estimator. The variance estimate is given by |
| Left-censored data, which contains fully observed or left-censored observations | Use the Kaplan-Meier estimator. | Use Greenwood's formula. |
| Double-censored data, which includes both right-censored and left-censored observations | Use Turnbull's algorithm [3][4]. You can specify
the maximum number of iterations ( | Use the Fisher information matrix. |
| Interval-censored data, which includes interval-censored observations |
| Not supported |
References
[1] Cox, D. R., and D. Oakes. Analysis of Survival Data. London: Chapman & Hall, 1984.
[2] Lawless, J. F. Statistical Models and Methods for Lifetime Data. 2nd ed., Hoboken, NJ: John Wiley & Sons, Inc., 2003.
[3] Klein, John P., and Melvin L. Moeschberger. Survival Analysis: Techniques for Censored and Truncated Data. 2nd ed. Statistics for Biology and Health. New York: Springer, 2003.
[4] Turnbull, Bruce W. "Nonparametric Estimation of a Survivorship Function with Doubly Censored Data." Journal of the American Statistical Association 69, No. 345 (1974): 169–73.
[5] Anderson-Bergman, Clifford. "An Efficient Implementation of the EMICM Algorithm for the Interval Censored NPMLE." Journal of Computational and Graphical Statistics 26, no. 2 (April 3, 2017): 463–67.
[6] Ware, James H., and David L. Demets. "Reanalysis of Some Baboon Descent Data." Biometrics 32, no. 2 (June 1976): 459–63.
Extended Capabilities
Version History
Introduced before R2006a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)