fitcsvm
Train support vector machine (SVM) classifier for one-class and binary classification
Syntax
Description
fitcsvm trains or cross-validates a support vector
machine (SVM) model for one-class and two-class (binary) classification on a
low-dimensional or moderate-dimensional predictor data set. fitcsvm
supports mapping the predictor data using kernel functions, and supports sequential
minimal optimization (SMO), iterative single data algorithm (ISDA), or
L1 soft-margin minimization via quadratic programming for
objective-function minimization.
To train a linear SVM model for binary classification on a high-dimensional data set,
that is, a data set that includes many predictor variables, use fitclinear instead.
For multiclass learning with combined binary SVM models, use error-correcting output
codes (ECOC). For more details, see fitcecoc.
To train an SVM regression model, see fitrsvm for low-dimensional and moderate-dimensional predictor data
sets, or fitrlinear for high-dimensional data
sets.
Mdl = fitcsvm(Tbl,ResponseVarName)Mdl trained using the sample data contained in the table
Tbl. ResponseVarName is the name of
the variable in Tbl that contains the class labels for
one-class or two-class classification.
If the class label variable contains only one class (for example, a vector of
ones), fitcsvm trains a model for one-class classification.
Otherwise, the function trains a model for two-class classification.
Mdl = fitcsvm(___,Name,Value)
Examples
Train SVM Classifier
Load Fisher's iris data set. Remove the sepal lengths and widths and all observed setosa irises.
load fisheriris inds = ~strcmp(species,'setosa'); X = meas(inds,3:4); y = species(inds);
Train an SVM classifier using the processed data set.
SVMModel = fitcsvm(X,y)
SVMModel =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 100
Alpha: [24x1 double]
Bias: -14.4149
KernelParameters: [1x1 struct]
BoxConstraints: [100x1 double]
ConvergenceInfo: [1x1 struct]
IsSupportVector: [100x1 logical]
Solver: 'SMO'
SVMModel is a trained ClassificationSVM classifier. Display the properties of SVMModel. For example, to determine the class order, use dot notation.
classOrder = SVMModel.ClassNames
classOrder = 2x1 cell
{'versicolor'}
{'virginica' }
The first class ('versicolor') is the negative class, and the second ('virginica') is the positive class. You can change the class order during training by using the 'ClassNames' name-value pair argument.
Plot a scatter diagram of the data and circle the support vectors.
sv = SVMModel.SupportVectors; figure gscatter(X(:,1),X(:,2),y) hold on plot(sv(:,1),sv(:,2),'ko','MarkerSize',10) legend('versicolor','virginica','Support Vector') hold off
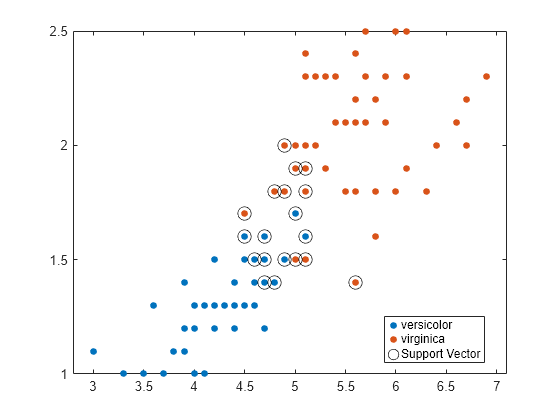
The support vectors are observations that occur on or beyond their estimated class boundaries.
You can adjust the boundaries (and, therefore, the number of support vectors) by setting a box constraint during training using the 'BoxConstraint' name-value pair argument.
Plot Decision Boundary and Margin Lines for Two-Class SVM Classifier
This example shows how to plot the decision boundary and margin lines of a two-class (binary) SVM classifier with two predictor variables.
Load Fisher's iris data set. Exclude all the versicolor iris species (leaving only the setosa and virginica species), and keep only the sepal length and width measurements.
load fisheriris; inds = ~strcmp(species,'versicolor'); X = meas(inds,1:2); s = species(inds);
Train a linear kernel SVM classifier.
SVMModel = fitcsvm(X,s);
SVMModel is a trained ClassificationSVM classifier, whose properties include the support vectors, linear predictor coefficients, and bias term.
sv = SVMModel.SupportVectors; % Support vectors beta = SVMModel.Beta; % Linear predictor coefficients b = SVMModel.Bias; % Bias term
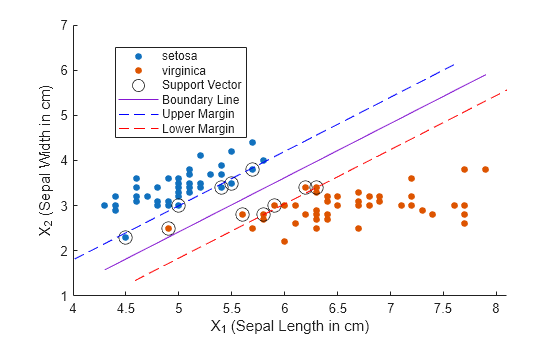
Plot a scatter diagram of the data, and circle the support vectors. The support vectors are observations that occur on or beyond their estimated class boundaries.
hold on gscatter(X(:,1),X(:,2),s) plot(sv(:,1),sv(:,2),'ko','MarkerSize',10)
The best separating hyperplane for the SVMModel classifier is a straight line specified by . Plot the decision boundary between the two species as a solid line.
X1 = linspace(min(X(:,1)),max(X(:,1)),100);
X2 = -(beta(1)/beta(2)*X1)-b/beta(2);
plot(X1,X2,'-')The linear predictor coefficients define a vector that is orthogonal to the decision boundary. The maximum margin width is (for more information, see Support Vector Machines for Binary Classification). Plot the maximum margin boundaries as dashed lines. Label the axes and add a legend.
m = 1/sqrt(beta(1)^2 + beta(2)^2); % Margin half-width X1margin_low = X1+beta(1)*m^2; X2margin_low = X2+beta(2)*m^2; X1margin_high = X1-beta(1)*m^2; X2margin_high = X2-beta(2)*m^2; plot(X1margin_high,X2margin_high,'b--') plot(X1margin_low,X2margin_low,'r--') xlabel('X_1 (Sepal Length in cm)') ylabel('X_2 (Sepal Width in cm)') legend('setosa','virginica','Support Vector', ... 'Boundary Line','Upper Margin','Lower Margin') hold off
Train and Cross-Validate SVM Classifier
Load the ionosphere data set.
load ionosphere rng(1); % For reproducibility
Train an SVM classifier using the radial basis kernel. Let the software find a scale value for the kernel function. Standardize the predictors.
SVMModel = fitcsvm(X,Y,'Standardize',true,'KernelFunction','RBF',... 'KernelScale','auto');
SVMModel is a trained ClassificationSVM classifier.
Cross-validate the SVM classifier. By default, the software uses 10-fold cross-validation.
CVSVMModel = crossval(SVMModel);
CVSVMModel is a ClassificationPartitionedModel cross-validated classifier.
Estimate the out-of-sample misclassification rate.
classLoss = kfoldLoss(CVSVMModel)
classLoss = 0.0484
The generalization rate is approximately 5%.
Detect Outliers Using SVM and One-Class Learning
Modify Fisher's iris data set by assigning all the irises to the same class. Detect outliers in the modified data set, and confirm the expected proportion of the observations that are outliers.
Load Fisher's iris data set. Remove the petal lengths and widths. Treat all irises as coming from the same class.
load fisheriris
X = meas(:,1:2);
y = ones(size(X,1),1);Train an SVM classifier using the modified data set. Assume that 5% of the observations are outliers. Standardize the predictors.
rng(1); SVMModel = fitcsvm(X,y,'KernelScale','auto','Standardize',true,... 'OutlierFraction',0.05);
SVMModel is a trained ClassificationSVM classifier. By default, the software uses the Gaussian kernel for one-class learning.
Plot the observations and the decision boundary. Flag the support vectors and potential outliers.
svInd = SVMModel.IsSupportVector; h = 0.02; % Mesh grid step size [X1,X2] = meshgrid(min(X(:,1)):h:max(X(:,1)),... min(X(:,2)):h:max(X(:,2))); [~,score] = predict(SVMModel,[X1(:),X2(:)]); scoreGrid = reshape(score,size(X1,1),size(X2,2)); figure plot(X(:,1),X(:,2),'k.') hold on plot(X(svInd,1),X(svInd,2),'ro','MarkerSize',10) contour(X1,X2,scoreGrid) colorbar; title('{\bf Iris Outlier Detection via One-Class SVM}') xlabel('Sepal Length (cm)') ylabel('Sepal Width (cm)') legend('Observation','Support Vector') hold off
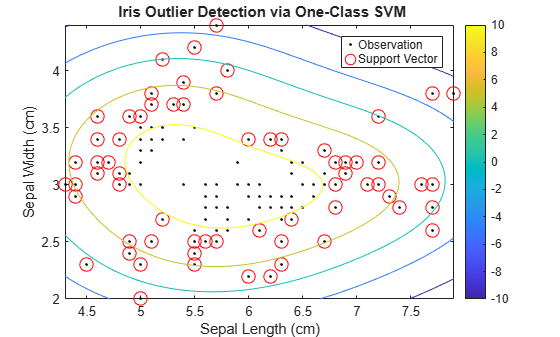
The boundary separating the outliers from the rest of the data occurs where the contour value is 0.
Verify that the fraction of observations with negative scores in the cross-validated data is close to 5%.
CVSVMModel = crossval(SVMModel); [~,scorePred] = kfoldPredict(CVSVMModel); outlierRate = mean(scorePred<0)
outlierRate = 0.0467
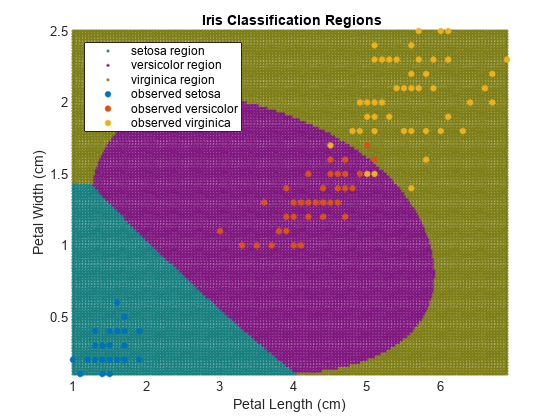
Find Multiple Class Boundaries Using Binary SVM
Create a scatter plot of the fisheriris data set. Treat coordinates of a grid within the plot as new observations from the distribution of the data set, and find class boundaries by assigning the coordinates to one of the three classes in the data set.
Load Fisher's iris data set. Use the petal lengths and widths as the predictors.
load fisheriris
X = meas(:,3:4);
Y = species;Examine a scatter plot of the data.
figure gscatter(X(:,1),X(:,2),Y); h = gca; lims = [h.XLim h.YLim]; % Extract the x and y axis limits title('{\bf Scatter Diagram of Iris Measurements}'); xlabel('Petal Length (cm)'); ylabel('Petal Width (cm)'); legend('Location','Northwest');
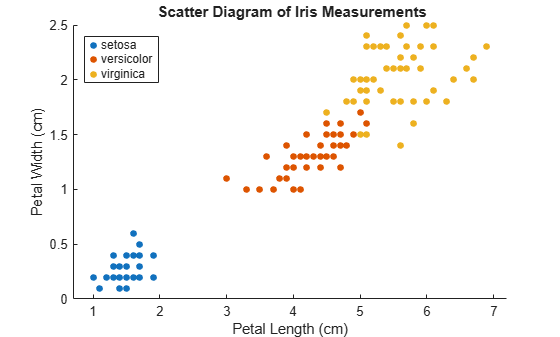
The data contains three classes, one of which is linearly separable from the others.
For each class:
Create a logical vector (
indx) indicating whether an observation is a member of the class.Train an SVM classifier using the predictor data and
indx.Store the classifier in a cell of a cell array.
Define the class order.
SVMModels = cell(3,1); classes = unique(Y); rng(1); % For reproducibility for j = 1:numel(classes) indx = strcmp(Y,classes(j)); % Create binary classes for each classifier SVMModels{j} = fitcsvm(X,indx,'ClassNames',[false true],'Standardize',true,... 'KernelFunction','rbf','BoxConstraint',1); end
SVMModels is a 3-by-1 cell array, with each cell containing a ClassificationSVM classifier. For each cell, the positive class is setosa, versicolor, and virginica, respectively.
Define a fine grid within the plot, and treat the coordinates as new observations from the distribution of the training data. Estimate the score of the new observations using each classifier.
d = 0.02; [x1Grid,x2Grid] = meshgrid(min(X(:,1)):d:max(X(:,1)),... min(X(:,2)):d:max(X(:,2))); xGrid = [x1Grid(:),x2Grid(:)]; N = size(xGrid,1); Scores = zeros(N,numel(classes)); for j = 1:numel(classes) [~,score] = predict(SVMModels{j},xGrid); Scores(:,j) = score(:,2); % Second column contains positive-class scores end
Each row of Scores contains three scores. The index of the element with the largest score is the index of the class to which the new class observation most likely belongs.
Associate each new observation with the classifier that gives it the maximum score.
[~,maxScore] = max(Scores,[],2);
Color in the regions of the plot based on the class to which the corresponding new observation belongs.
figure h(1:3) = gscatter(xGrid(:,1),xGrid(:,2),maxScore,... [0.1 0.5 0.5; 0.5 0.1 0.5; 0.5 0.5 0.1]); hold on h(4:6) = gscatter(X(:,1),X(:,2),Y); title('{\bf Iris Classification Regions}'); xlabel('Petal Length (cm)'); ylabel('Petal Width (cm)'); legend(h,{'setosa region','versicolor region','virginica region',... 'observed setosa','observed versicolor','observed virginica'},... 'Location','Northwest'); axis tight hold off
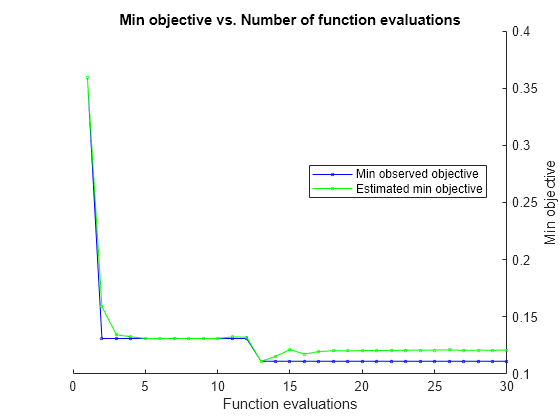
Optimize SVM Classifier
Optimize hyperparameters automatically using fitcsvm.
Load the ionosphere data set.
load ionosphereFind hyperparameters that minimize five-fold cross-validation loss by using automatic hyperparameter optimization. For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
rng default Mdl = fitcsvm(X,Y,'OptimizeHyperparameters','auto', ... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName', ... 'expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.35897 | 0.21571 | 0.35897 | 0.35897 | 3.8653 | 961.53 | true |
| 2 | Best | 0.12821 | 9.5601 | 0.12821 | 0.15646 | 429.99 | 0.2378 | false |
| 3 | Accept | 0.35897 | 0.15385 | 0.12821 | 0.1315 | 0.11801 | 8.9479 | false |
| 4 | Accept | 0.1339 | 4.7787 | 0.12821 | 0.12965 | 0.0010694 | 0.0032063 | true |
| 5 | Accept | 0.15954 | 11.394 | 0.12821 | 0.12824 | 973.65 | 0.15179 | false |
| 6 | Accept | 0.13675 | 0.20822 | 0.12821 | 0.1283 | 234.28 | 2.8822 | false |
| 7 | Accept | 0.35897 | 0.080604 | 0.12821 | 0.12826 | 0.005253 | 835.53 | true |
| 8 | Accept | 0.14245 | 10.658 | 0.12821 | 0.12829 | 91.176 | 0.042696 | false |
| 9 | Accept | 0.151 | 10.571 | 0.12821 | 0.12831 | 0.0064316 | 0.0010249 | true |
| 10 | Accept | 0.1339 | 5.7924 | 0.12821 | 0.12835 | 153.27 | 0.38874 | false |
| 11 | Accept | 0.26781 | 11.485 | 0.12821 | 0.12948 | 260.21 | 0.001097 | false |
| 12 | Accept | 0.12821 | 0.17168 | 0.12821 | 0.12935 | 0.0034086 | 0.029311 | true |
| 13 | Best | 0.11966 | 0.096056 | 0.11966 | 0.12144 | 0.0010229 | 0.032368 | true |
| 14 | Accept | 0.35897 | 0.079093 | 0.11966 | 0.12177 | 987.92 | 683.08 | false |
| 15 | Accept | 0.12821 | 0.10759 | 0.11966 | 0.11979 | 0.0010124 | 0.28112 | true |
| 16 | Accept | 0.22792 | 10.923 | 0.11966 | 0.11995 | 6.9606 | 0.001715 | true |
| 17 | Accept | 0.11966 | 0.14214 | 0.11966 | 0.11979 | 0.0010509 | 0.078769 | true |
| 18 | Accept | 0.12251 | 0.13518 | 0.11966 | 0.12049 | 0.0010131 | 0.054019 | true |
| 19 | Accept | 0.1339 | 6.0854 | 0.11966 | 0.12071 | 0.08684 | 0.018067 | true |
| 20 | Accept | 0.11966 | 0.14337 | 0.11966 | 0.12123 | 0.048335 | 0.21846 | true |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.11966 | 0.10788 | 0.11966 | 0.12119 | 0.013573 | 0.11789 | true |
| 22 | Accept | 0.1339 | 0.53704 | 0.11966 | 0.12123 | 1.2995 | 0.26436 | true |
| 23 | Accept | 0.1396 | 9.0082 | 0.11966 | 0.12127 | 0.0019603 | 0.0010023 | false |
| 24 | Accept | 0.13675 | 7.3357 | 0.11966 | 0.12136 | 0.17347 | 0.010479 | false |
| 25 | Accept | 0.14245 | 0.17413 | 0.11966 | 0.11914 | 0.0010001 | 0.0076351 | false |
| 26 | Accept | 0.12536 | 0.20403 | 0.11966 | 0.12144 | 0.035903 | 0.11247 | true |
| 27 | Accept | 0.1339 | 3.694 | 0.11966 | 0.12144 | 897.97 | 1.361 | false |
| 28 | Accept | 0.1339 | 5.6394 | 0.11966 | 0.12146 | 6.6245 | 0.085879 | false |
| 29 | Accept | 0.12251 | 0.076286 | 0.11966 | 0.1214 | 0.0069215 | 0.12029 | true |
| 30 | Accept | 0.12251 | 0.072214 | 0.11966 | 0.12136 | 0.049433 | 0.43143 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 121.8127 seconds
Total objective function evaluation time: 109.6289
Best observed feasible point:
BoxConstraint KernelScale Standardize
_____________ ___________ ___________
0.0010229 0.032368 true
Observed objective function value = 0.11966
Estimated objective function value = 0.12229
Function evaluation time = 0.096056
Best estimated feasible point (according to models):
BoxConstraint KernelScale Standardize
_____________ ___________ ___________
0.013573 0.11789 true
Estimated objective function value = 0.12136
Estimated function evaluation time = 0.10561
Mdl =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
Alpha: [90x1 double]
Bias: -0.1318
KernelParameters: [1x1 struct]
Mu: [0.8917 0 0.6413 0.0444 0.6011 0.1159 0.5501 0.1194 0.5118 0.1813 0.4762 0.1550 0.4008 0.0934 0.3442 0.0711 0.3819 -0.0036 0.3594 -0.0240 0.3367 0.0083 0.3625 -0.0574 0.3961 -0.0712 0.5416 -0.0695 ... ] (1x34 double)
Sigma: [0.3112 0 0.4977 0.4414 0.5199 0.4608 0.4927 0.5207 0.5071 0.4839 0.5635 0.4948 0.6222 0.4949 0.6528 0.4584 0.6180 0.4968 0.6263 0.5191 0.6098 0.5182 0.6038 0.5275 0.5785 0.5085 0.5162 0.5500 ... ] (1x34 double)
BoxConstraints: [351x1 double]
ConvergenceInfo: [1x1 struct]
IsSupportVector: [351x1 logical]
Solver: 'SMO'
Input Arguments
Output Arguments
Limitations
fitcsvmtrains SVM classifiers for one-class or two-class learning applications. To train SVM classifiers using data with more than two classes, usefitcecoc.fitcsvmsupports low-dimensional and moderate-dimensional data sets. For high-dimensional data sets, usefitclinearinstead.
More About
Tips
Unless your data set is large, always try to standardize the predictors (see
Standardize). Standardization makes predictors insensitive to the scales on which they are measured.It is a good practice to cross-validate using the
KFoldname-value pair argument. The cross-validation results determine how well the SVM classifier generalizes.For one-class learning:
The default setting for the name-value pair argument
Alphacan lead to long training times. To speed up training, setAlphato a vector mostly composed of0s.Set the name-value pair argument
Nuto a value closer to0to yield fewer support vectors and, therefore, a smoother but crude decision boundary.
Sparsity in support vectors is a desirable property of an SVM classifier. To decrease the number of support vectors, set
BoxConstraintto a large value. This action increases the training time.For optimal training time, set
CacheSizeas high as the memory limit your computer allows.If you expect many fewer support vectors than observations in the training set, then you can significantly speed up convergence by shrinking the active set using the name-value pair argument
'ShrinkagePeriod'. It is a good practice to specify'ShrinkagePeriod',1000.Duplicate observations that are far from the decision boundary do not affect convergence. However, just a few duplicate observations that occur near the decision boundary can slow down convergence considerably. To speed up convergence, specify
'RemoveDuplicates',trueif:Your data set contains many duplicate observations.
You suspect that a few duplicate observations fall near the decision boundary.
To maintain the original data set during training,
fitcsvmmust temporarily store separate data sets: the original and one without the duplicate observations. Therefore, if you specifytruefor data sets containing few duplicates, thenfitcsvmconsumes close to double the memory of the original data.After training a model, you can generate C/C++ code that predicts labels for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation.
Algorithms
For the mathematical formulation of the SVM binary classification algorithm, see Support Vector Machines for Binary Classification and Understanding Support Vector Machines.
NaN,<undefined>, empty character vector (''), empty string (""), and<missing>values indicate missing values.fitcsvmremoves entire rows of data corresponding to a missing response. When computing total weights (see the next bullets),fitcsvmignores any weight corresponding to an observation with at least one missing predictor. This action can lead to unbalanced prior probabilities in balanced-class problems. Consequently, observation box constraints might not equalBoxConstraint.If you specify the
Cost,Prior, andWeightsname-value arguments, the output model object stores the specified values in theCost,Prior, andWproperties, respectively. TheCostproperty stores the user-specified cost matrix (C) without modification. ThePriorandWproperties store the prior probabilities and observation weights, respectively, after normalization. For model training, the software updates the prior probabilities and observation weights to incorporate the penalties described in the cost matrix. For details, see Misclassification Cost Matrix, Prior Probabilities, and Observation Weights.Note that the
CostandPriorname-value arguments are used for two-class learning. For one-class learning, theCostandPriorproperties store0and1, respectively.For two-class learning,
fitcsvmassigns a box constraint to each observation in the training data. The formula for the box constraint of observation j iswhere C0 is the initial box constraint (see the
BoxConstraintname-value argument), and wj* is the observation weight adjusted byCostandPriorfor observation j. For details about the observation weights, see Adjust Prior Probabilities and Observation Weights for Misclassification Cost Matrix.If you specify
Standardizeastrueand set theCost,Prior, orWeightsname-value argument, thenfitcsvmstandardizes the predictors using their corresponding weighted means and weighted standard deviations. That is,fitcsvmstandardizes predictor j (xj) usingwhere xjk is observation k (row) of predictor j (column), and
Assume that
pis the proportion of outliers that you expect in the training data, and that you set'OutlierFraction',p.For one-class learning, the software trains the bias term such that 100
p% of the observations in the training data have negative scores.The software implements robust learning for two-class learning. In other words, the software attempts to remove 100
p% of the observations when the optimization algorithm converges. The removed observations correspond to gradients that are large in magnitude.
If your predictor data contains categorical variables, then the software generally uses full dummy encoding for these variables. The software creates one dummy variable for each level of each categorical variable.
The
PredictorNamesproperty stores one element for each of the original predictor variable names. For example, assume that there are three predictors, one of which is a categorical variable with three levels. ThenPredictorNamesis a 1-by-3 cell array of character vectors containing the original names of the predictor variables.The
ExpandedPredictorNamesproperty stores one element for each of the predictor variables, including the dummy variables. For example, assume that there are three predictors, one of which is a categorical variable with three levels. ThenExpandedPredictorNamesis a 1-by-5 cell array of character vectors containing the names of the predictor variables and the new dummy variables.Similarly, the
Betaproperty stores one beta coefficient for each predictor, including the dummy variables.The
SupportVectorsproperty stores the predictor values for the support vectors, including the dummy variables. For example, assume that there are m support vectors and three predictors, one of which is a categorical variable with three levels. ThenSupportVectorsis an n-by-5 matrix.The
Xproperty stores the training data as originally input and does not include the dummy variables. When the input is a table,Xcontains only the columns used as predictors.
For predictors specified in a table, if any of the variables contain ordered (ordinal) categories, the software uses ordinal encoding for these variables.
For a variable with k ordered levels, the software creates k – 1 dummy variables. The jth dummy variable is –1 for levels up to j, and +1 for levels j + 1 through k.
The names of the dummy variables stored in the
ExpandedPredictorNamesproperty indicate the first level with the value +1. The software stores k – 1 additional predictor names for the dummy variables, including the names of levels 2, 3, ..., k.
All solvers implement L1 soft-margin minimization.
For one-class learning, the software estimates the Lagrange multipliers, α1,...,αn, such that
Alternative Functionality
You can also use the ocsvm
function to train a one-class SVM model for anomaly detection.
The
ocsvmfunction provides a simpler and preferred workflow for anomaly detection than thefitcsvmfunction.The
ocsvmfunction returns aOneClassSVMobject, anomaly indicators, and anomaly scores. You can use the outputs to identify anomalies in training data. To find anomalies in new data, you can use theisanomalyobject function ofOneClassSVM. Theisanomalyfunction returns anomaly indicators and scores for the new data.The
fitcsvmfunction supports both one-class and binary classification. If the class label variable contains only one class (for example, a vector of ones),fitcsvmtrains a model for one-class classification and returns aClassificationSVMobject. To identify anomalies, you must first compute anomaly scores by using theresubPredictorpredictobject function ofClassificationSVM, and then identify anomalies by finding observations that have negative scores.Note that a large positive anomaly score indicates an anomaly in
ocsvm, whereas a negative score indicates an anomaly inpredictofClassificationSVM.
The
ocsvmfunction finds the decision boundary based on the primal form of SVM, whereas thefitcsvmfunction finds the decision boundary based on the dual form of SVM.The solver in
ocsvmis computationally less expensive than the solver infitcsvmfor a large data set (large n). Unlike solvers infitcsvm, which require computation of the n-by-n Gram matrix, the solver inocsvmonly needs to form a matrix of size n-by-m. Here, m is the number of dimensions of expanded space, which is typically much less than n for big data.
References
[1] Christianini, N., and J. C. Shawe-Taylor. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods. Cambridge, UK: Cambridge University Press, 2000.
[2] Fan, R.-E., P.-H. Chen, and C.-J. Lin. “Working set selection using second order information for training support vector machines.” Journal of Machine Learning Research, Vol. 6, 2005, pp. 1889–1918.
[3] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, Second Edition. NY: Springer, 2008.
[4] Kecman V., T. -M. Huang, and M. Vogt. “Iterative Single Data Algorithm for Training Kernel Machines from Huge Data Sets: Theory and Performance.” Support Vector Machines: Theory and Applications. Edited by Lipo Wang, 255–274. Berlin: Springer-Verlag, 2005.
[5] Scholkopf, B., J. C. Platt, J. C. Shawe-Taylor, A. J. Smola, and R. C. Williamson. “Estimating the Support of a High-Dimensional Distribution.” Neural Comput., Vol. 13, Number 7, 2001, pp. 1443–1471.
[6] Scholkopf, B., and A. Smola. Learning with Kernels: Support Vector Machines, Regularization, Optimization and Beyond, Adaptive Computation and Machine Learning. Cambridge, MA: The MIT Press, 2002.
Extended Capabilities
Version History
Introduced in R2014aSee Also
ClassificationSVM | CompactClassificationSVM | ClassificationPartitionedModel | predict | fitSVMPosterior | rng | quadprog (Optimization Toolbox) | fitcecoc | fitclinear | ocsvm
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)