nnmf
Nonnegative matrix factorization
Description
[
factors the n-by-m matrix W,H] = nnmf(A,k)A
into nonnegative factors W
(n-by-k) and H
(k-by-m). The factorization is not exact;
W*H is a lower-rank approximation to A.
The factors W and H minimize the root mean
square residual D between A and
W*H.
D = norm(A - W*H,'fro')/sqrt(n*m)The factorization uses an iterative algorithm starting with random initial values
for W and H. Because the root mean square
residual D might have local minima, repeated factorizations might
yield different W and H. Sometimes the
algorithm converges to a solution of lower rank than k, which can
indicate that the result is not optimal.
[
modifies the factorization using one or more name-value pair arguments. For example,
you can request repeated factorizations by setting W,H] = nnmf(A,k,Name,Value)'Replicates'
to an integer value greater than 1.
Examples
Nonnegative Rank-Two Approximation and Biplot
Load the sample data.
load fisheririsCompute a nonnegative rank-two approximation of the measurements of the four variables in Fisher's iris data.
rng(1) % For reproducibility
[W,H] = nnmf(meas,2);
HH = 2×4
0.6945 0.2856 0.6220 0.2218
0.8020 0.5683 0.1834 0.0149
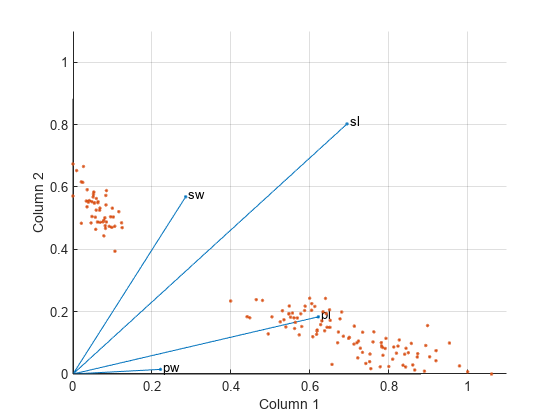
The first and third variables in meas (sepal length and petal length, with coefficients 0.6945 and 0.6220, respectively) provide relatively strong weights to the first column of W . The first and second variables in meas (sepal length and sepal width, with coefficients 0.8020 and 0.5683, respectively) provide relatively strong weights to the second column of W.
Create a biplot of the data and the variables in meas in the column space of W.
biplot(H','Scores',W,'VarLabels',{'sl','sw','pl','pw'}); axis([0 1.1 0 1.1]) xlabel('Column 1') ylabel('Column 2')
Change Algorithm
Starting from a random array X with rank 20, try a few iterations at several replicates using the multiplicative algorithm.
rng default % For reproducibility X = rand(100,20)*rand(20,50); opt = statset('MaxIter',5,'Display','final'); [W0,H0] = nnmf(X,5,'Replicates',10,... 'Options',opt,... 'Algorithm','mult');
rep iteration rms resid |delta x|
1 5 0.560887 0.0245182
2 5 0.66418 0.0364471
3 5 0.609125 0.0358355
4 5 0.608894 0.0415491
5 5 0.619291 0.0455135
6 5 0.621549 0.0299965
7 5 0.640549 0.0438758
8 5 0.673015 0.0366856
9 5 0.606835 0.0318931
10 5 0.633526 0.0319591
Final root mean square residual = 0.560887
Continue with more iterations from the best of these results using alternating least squares.
opt = statset('Maxiter',1000,'Display','final'); [W,H] = nnmf(X,5,'W0',W0,'H0',H0,... 'Options',opt,... 'Algorithm','als');
rep iteration rms resid |delta x|
1 24 0.257336 0.00271859
Final root mean square residual = 0.257336
Input Arguments
Output Arguments
References
[1] Berry, Michael W., Murray Browne, Amy N. Langville, V. Paul Pauca, and Robert J. Plemmons. “Algorithms and Applications for Approximate Nonnegative Matrix Factorization.” Computational Statistics & Data Analysis 52, no. 1 (September 2007): 155–73. https://doi.org/10.1016/j.csda.2006.11.006.
Extended Capabilities
Version History
Introduced in R2008a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)