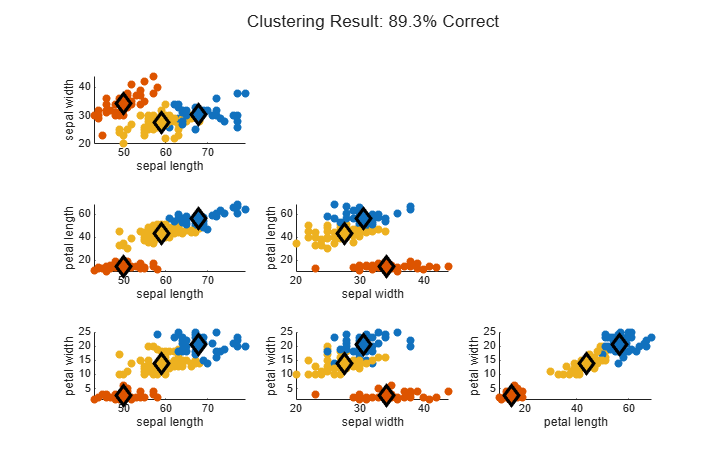
Data Clustering
The purpose of clustering is to identify natural groupings from a large data set to produce a concise representation of the data. You can use Fuzzy Logic Toolbox™ software to identify clusters within input/output training data using either fuzzy c-means or subtractive clustering. Also, you can use the resulting cluster information to generate a fuzzy inference system to model the data behavior. For more information, see Fuzzy Clustering.
Functions
fcm | Fuzzy c-means clustering |
fcmOptions | FCM clustering options (Since R2023a) |
subclust | Find cluster centers using subtractive clustering |
findcluster | Open clustering tool |
Topics
- Fuzzy Clustering
Identify natural groupings of data using fuzzy c-means or subtractive clustering.
- Fuzzy C-Means Clustering
Cluster example numerical data using a demonstration user interface.
- Cluster Quasi-Random Data Using Fuzzy C-Means Clustering
Cluster data and determine cluster centers using FCM.
- Adjust Fuzzy Overlap in Fuzzy C-Means Clustering
Specify the crispness of the boundary between fuzzy clusters.
- Cluster Data Using Clustering Tool
Interactively cluster data using fuzzy c-means or subtractive clustering.
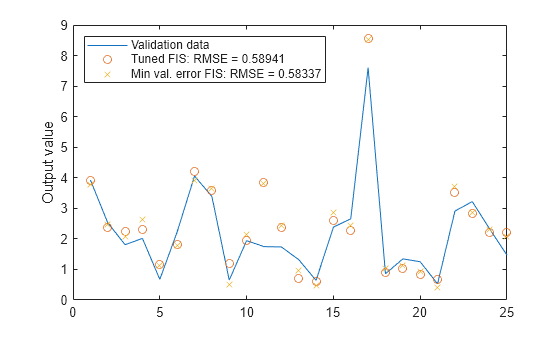
Featured Examples

You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)