vgg16
(Not recommended) VGG-16 convolutional neural network
vgg16 is not recommended. Use the imagePretrainedNetwork function instead and specify the "vgg16" model. For more information, see Version History.
Description
VGG-16 is a convolutional neural network that is 16 layers deep. You can load a pretrained version of the network trained on more than a million images from the ImageNet database [1]. The pretrained network can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. As a result, the network has learned rich feature representations for a wide range of images. The network has an image input size of 224-by-224. For more pretrained networks in MATLAB®, see Pretrained Deep Neural Networks.
net = vgg16
This function requires Deep Learning Toolbox™ Model for VGG-16 Network support package. If this support package is not installed, then the function provides a download link.
net = vgg16('Weights','imagenet')net = vgg16.
layers = vgg16('Weights','none')
Examples
Download VGG-16 Support Package
Download and install Deep Learning Toolbox Model for VGG-16 Network support package.
Type vgg16 at the command line.
vgg16
If Deep Learning Toolbox Model for VGG-16 Network support package is not
installed, then the function provides a link to the required support package in the
Add-On Explorer. To install the support package, click the link, and then click
Install. Check that the installation is successful by typing
vgg16 at the command line.
vgg16
ans =
SeriesNetwork with properties:
Layers: [41×1 nnet.cnn.layer.Layer]Visualize the network using Deep Network Designer.
deepNetworkDesigner(vgg16)
Explore other pretrained neural networks in Deep Network Designer by clicking New.
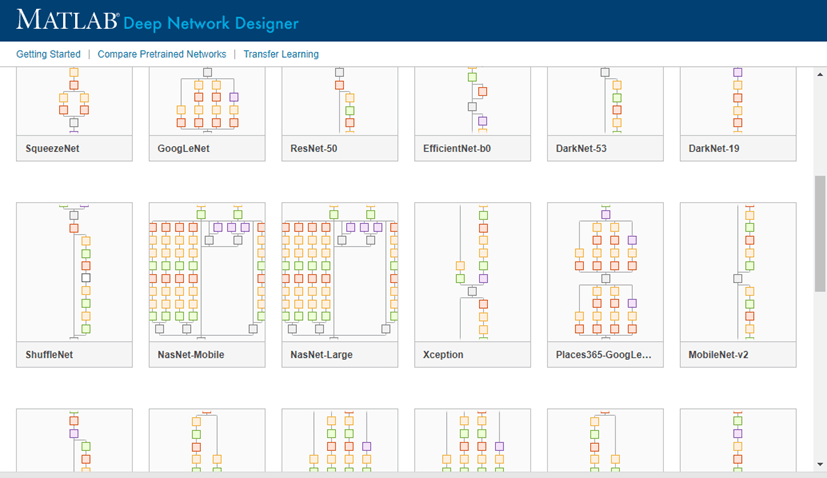
If you need to download a neural network, pause on the desired neural network and click Install to open the Add-On Explorer.
Output Arguments
References
[1] ImageNet. http://www.image-net.org.
[2] Russakovsky, O., Deng, J., Su, H., et al. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision (IJCV). Vol 115, Issue 3, 2015, pp. 211–252
[3] Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
[4] Very Deep Convolutional Networks for Large-Scale Visual Recognition http://www.robots.ox.ac.uk/~vgg/research/very_deep/
Extended Capabilities
Version History
Introduced in R2017aSee Also
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | Deep Network Designer
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)