Anatomy of App-Generated MATLAB Code
With Diagnostic Feature Designer, you can generate MATLAB® code that automates the computations for the features and variables you choose. This generated code accepts any ensemble data that is configured the same way as the ensemble data you imported into the app, and generates a new feature table, as well as computed signals, spectra, and ranking tables, that can be used for feature analysis or model training. The code replicates various options that you set within the app, and can perform:
Full-signal computation of signals and features for each member
Ranking for features
Ensemble-level computations for characterizing ensemble behavior
Parallel processing
Processing of segmented signals, also known as frame-based processing
Ensemble management is a fundamental component of the generated code. For information about data ensembles and ensemble variable types, see Data Ensembles for Condition Monitoring and Predictive Maintenance.
You can compare this functional description with actual code by generating your own code in the app. For more information, see Automatic Feature Extraction Using Generated MATLAB Code. For an example showing how to generate code, see Generate a MATLAB Function in Diagnostic Feature Designer. For an example that provides a setup for frame-based code generation, see Perform Prognostic Feature Ranking for a Degrading System Using Diagnostic Feature Designer.
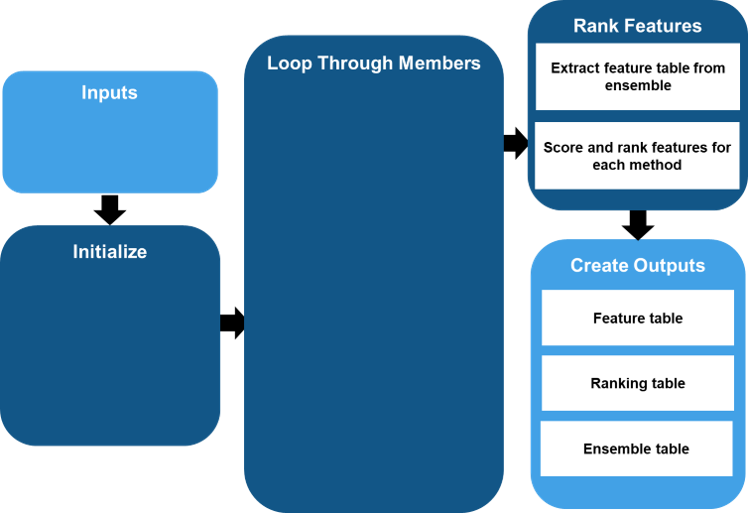
Basic Function Flow
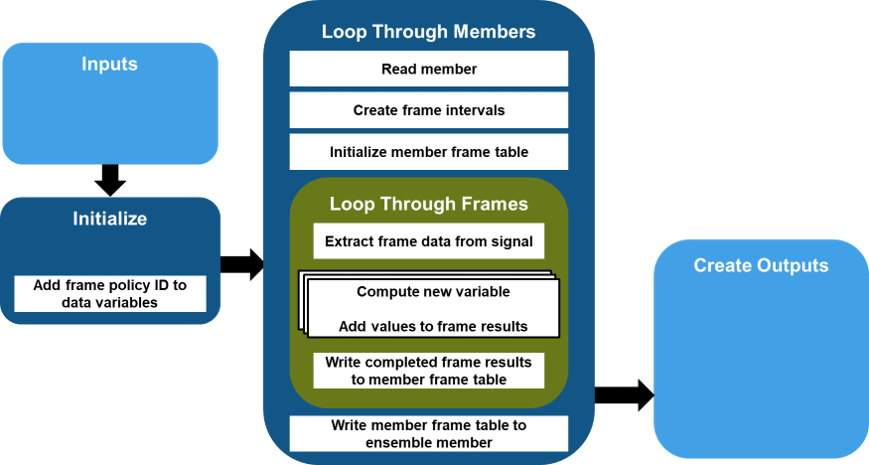
The figure illustrates the basic functional flow of generated code. In this diagram, the function returns both features and derived variables, uses serial processing, and operates on full signals.
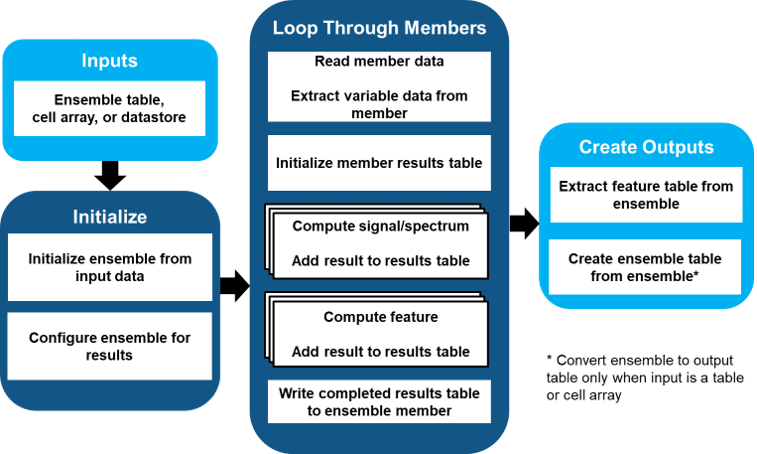
The figure breaks the code flow into three major sections: Initialize, Loop through Members, and Create Outputs.
The Initialize block performs initial configuration. Specific operations depend on the type of data you originally imported and the variables and features that you specified for code generation.
Loop Through Members block operations execute all the variable and feature computations one member at a time.
Create Outputs extracts and formats the feature table and the full ensemble.
Inputs
The function operates on input data that is consistent with the data you initially imported into the app. When you plan to generate code from the app, importing your data in the same format as the data that you plan to apply your code to is recommended.
If you imported a workspace variable such as an ensemble table or cell array from memory, the function requires an ensemble table or cell array.
If you imported a file or simulation ensemble datastore, the function requires a file or simulation ensemble datastore.
The input data for the code must have a variable structure that is similar to the data that you imported into the app. Your input ensemble can include additional variables as well. The code ignores the additional variables and does not flag them as errors.
Initialization
In the Initialize block, the code configures an ensemble that contains variables both
for the inputs and for the outputs that the function computes in the Loop Through Members
block. These computed outputs include the variables and features you explicitly selected
when you generated the code and any additional variables, such as a tsa signal,
that any of your features require.
If the input data is a table or cell array, the code creates a
workspaceEnsembleobject that includes variables corresponding to the input data variables. This object is similar to an ensemble datastore object, but it operates on data in memory rather than in external files.If the input data is a
simulationEnsembleDatastoreor afileEnsembleDatastoreobject, the code operates on the object directly.
Once the code initializes the ensemble, the code appends all the variables and features
to be computed during member computations. The code eliminates redundant variables with the
unique function.
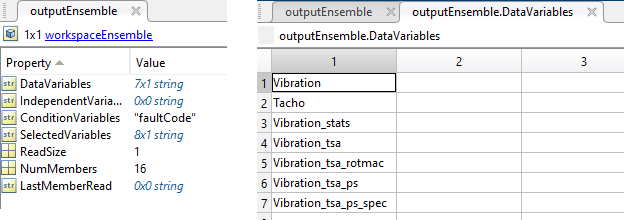
The figure shows an example of a workspace ensemble and its data variables. The data variables identify the input signals, output signals and spectra, and features.
Key ensemble-related functions during initialization include:
reset— Reset ensemble to its original unread state so that the code reads from the beginningworkspaceEnsemble— Ensemble object that manages data in memoryfileEnsembleDatastore— Ensemble object that manages data in external filessimulationEnsembleDatastore— Ensemble object that manages simulated data in external logs or files
Note
During initialization, the function does not preallocate arrays to use during
processing. This lack of preallocation is for clarity and flexibility, since the code must
operate on an input ensemble with any number of members. During follow-on computation
cycles, which append newly computed data to intermediate results tables, the code
suppresses MATLAB Code Analyzer warnings about preallocation using the in-line comment
%#ok<AGROW>. For information about Code Analyzer message
preferences, see Code Analyzer Settings.
Member Computation Loop
In the member computation loop, the function performs all member-specific computations, one member at a time.
A series of read
function calls initiates the loop, reading each ensemble member in succession until there
are no ensemble members left. The computations that follow each read
command provide, for that member, all the specified variables and features.
A running member-level results table collects the results as each variable or feature set is computed.
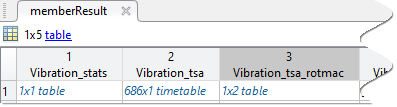
The figure shows an example of a member-level results table. Here, the results table contains two embedded tables that contain features and an embedded timetable that contains a computed signal.
Once all computations are complete, the code appends the full member results table back to the main ensemble.
Member computations use a try/catch combination to
handle input data that cannot be processed. This approach prevents bad data from halting
code execution.
The code uses these key ensemble-management functions:
read— Read the next ensemble memberreadMemberData— Extract data from an ensemble member for a specific variablewriteToLastMemberRead— Write data to ensemble membertable— Ensemble array that contains variables and features in named columns and members in rowsarray2table— Convert an array to a tabletimetable— Specialized member-specific table that contains signals in named variable columns and a specific time for each rowarray2timetable— Convert an array to a timetable
Outputs
The main output of the generated function is a feature table, which the code extracts
using the function readFeatureTable. This output is the same whether you are using a workspace
ensemble or an ensemble datastore as input. The feature table contains the scalar features
themselves as well as the condition variables.
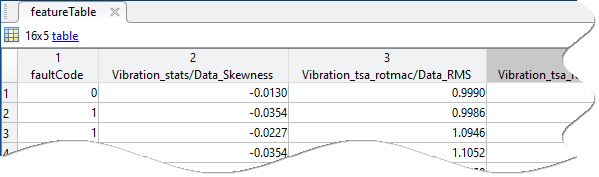
The figure shows an example of a feature table. Each row represents a member. The first column contains the condition variable, and subsequent columns contain a scalar feature value.
Use the optional second output argument to return the ensemble itself. If the input to
your function is a table or cell array, the function converts the workspace ensemble into a
table using the readall function, and returns the
table.
The figure shows an example of an output table. Each row represents a member. The first two columns are the input variables, and the remaining columns contain features or computed variables.
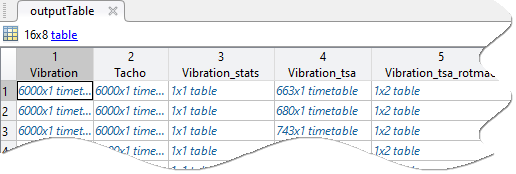
If your function is based on an original import of an ensemble datastore object, the function returns the updated datastore object.
The code includes these key functions for outputs:
readFeatureTable— Read condition variable and feature data from an ensemble data set into a tablereadall— Read all data from an ensemble data set into a table
Ranking
When you select one or more ranking tables when you generate code, the function includes a ranking section that follows the extraction of the feature table, as shown in the figure. The figure shows detail only for the portions of the flow chart that change from the Basic Function Flow figure. In Create Outputs, the figure shows all output arguments when using ranking.
To initialize ranking, the code extracts the feature values and the labels (condition
variable values) from the feature table. The code then defines class groups by converting
the labels into numeric values using the function grp2idx to assign a group index to each feature. For example, if the condition
variable FaultCode has the labels "Faulty",
"Degraded", and "Healthy",
grp2idx groups the members with these labels into groups 1, 2, and
3.
For each ranking method, the code computes a score for each feature with these steps:
Normalize the features using the specified normalization scheme.
Call the function for the ranking method, using a group-index mask to separate the groups. The specific syntax depends on the ranking method function.
If a correlation-importance factor is specified, update the score using
correlationWeightedScore. Correlation weighting lowers the scores of features that are highly correlated to higher ranking features, and that therefore are redundant.Append the scores to the scoring matrix and the method to the method list.
The code then creates a ranking table by using sortrows to sort the rows by the scores of the Sort By
method specified in the app during code generation.
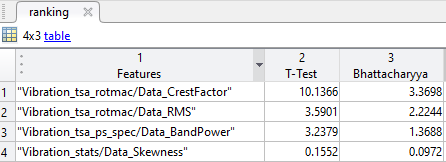
The figure shows an example of a ranking table for four features, sorted by T-Test results.
The code uses these key functions for managing ranking:
grp2idx— Convert labels to numeric valuescorrelationWeightedScore— Weight feature-ranking scores with correlation factorsortrows— Rank features by sorting the rows by score
Ensemble Statistics and Residues
An ensemble statistic is a statistical metric that represents the entire ensemble rather than an individual member. For example, in the app, you can specify the ensemble maximum for a vibration signal. The resulting single-member statistic contains, for each time sample, the vibration value that is the maximum of all the member vibration values.
You can use ensemble statistics to compute residues by subtracting the same ensemble metric from all the member signals for a specific variable. For example, if the ensemble mean represents an average operating point, you can subtract the mean from all members to isolate behavior around the operating point. The isolated signal is a form of a residue.
The figure illustrates the code flow when you specify features based on a mean residual signal.
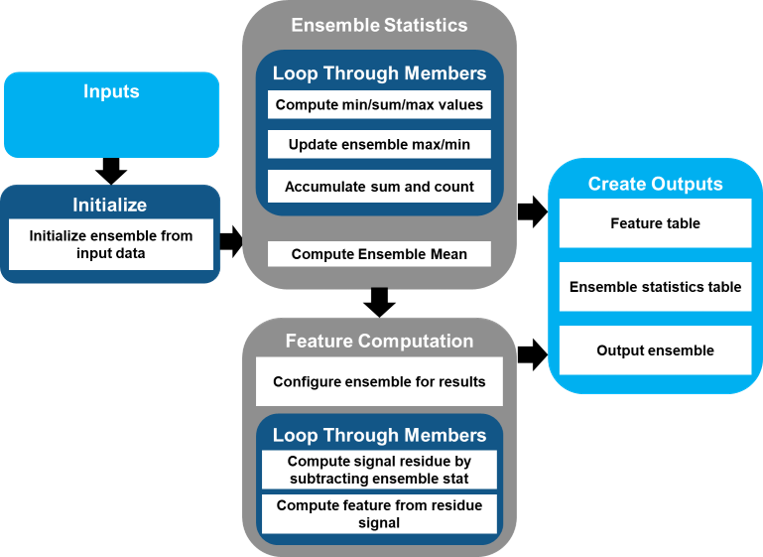
In this flow, there are two separate member loops. The first member loop computes the ensemble statistics. The second member loop performs the signal, spectrum, and feature processing. In the flow chart, the second member processing loop illustrates the residue signal and residue-based feature processing steps.
Loop 1: Ensemble Statistics Processing
To compute ensemble statistics for a specified variable, the code first loops through the members while maintaining an accumulator. At a given point in the looping sequence, the accumulator might contain, for example:
The maximum signal value calculated so far
A running sum of all the data values and an iteration count
The minimum signal value calculated so far
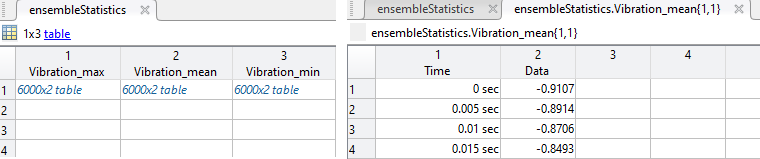
The figure shows an example of accumulator contents and the running sum and count in
the mean variable.

At the end of the loop iterations, the code transfers the ensemble max and min signals from the accumulator to the ensemble statistics max and min variables. The code calculates the ensemble mean by dividing the ensemble sum by the number of counts.
The figure shows an example of final ensemble statistics table and the final
mean variable that now contains the mean signal.
Loop 2: Residue Processing
In the main member processing loop, the code creates residue signal variables by subtracting the specified statistics from the specified signals, and packages these residues in the same manner as other signals and features.
The figure shows an example of a member result table with residues. The table contains two residue signals and two feature sets computed from those signals.

Parallel Processing
When you specify parallel processing, the code partitions the ensemble members into subensembles and executes the full member processing loop in parallel for each subensemble, as the figure shows.

If the main ensemble is a workspaceEnsemble object, then at the end of each partition-processing cycle,
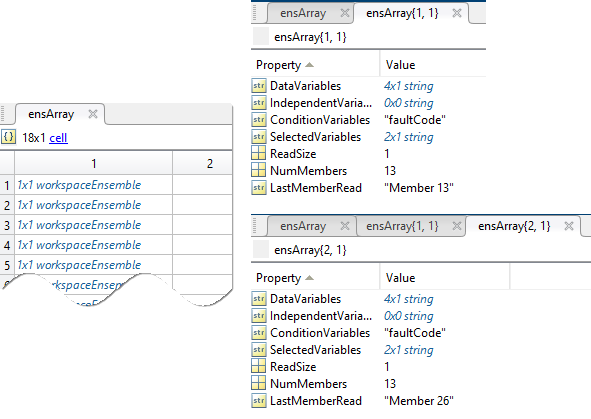
the code saves the updated subensemble as a cell in an array that stores the results for all
the subensembles. The following figure shows an example of this array along with the first
two cells. In this figure, each partition contains 13 members.
If the main ensemble is a workspace ensemble, then once all partition processing is
complete, the code reassembles the result partitions and updates the main ensemble using the
refresh
command.
If the main ensemble is an ensemble datastore object, then the code updates the object directly when it writes results to the subensemble member at the end of each member loop.
The code uses these key functions for parallel processing:
numpartitions— Number of partitions to separate ensemble members intopartition— Partition an ensemblerefresh— Update a workspace ensemble with reassembled partition results
Frame-Based Processing
When you have specified frame-based processing in the app, the generated code divides each full member signal into segments, or frames. The size and frequency of these frames are stored in the frame policy.
The figure illustrates the flow. The code executes a frame loop within each member loop. When you are selecting features for generating code, the app constrains your feature selections to a single frame policy. The generated function therefore never contains more than one frame loop.
During the initialization portion, the code adds only the input variables and the frame
policy id, such as FRM_2, to the data variables. The code does not add
the variables to be computed. Those variables are stored in the FRM_
variable.
During the first part of the member loop, the code:
Reads the full member signal.
Creates a frame interval table that spans the time range of the full signal and which contains the start and stop times for each frame, using
frameintervals.Initializes a frame table at the member level. This table ultimately contains computed variable values for all the frames in the member.
The second part of the member loop is the frame loop. For each frame, the code:
Uses the frame interval information to extract the data for that frame from the full signal.
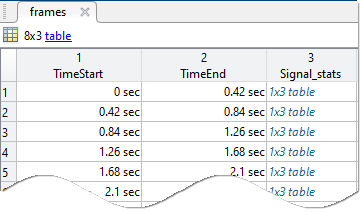
Computes the signals, spectra, and features in the same manner as for full-signal processing at the member level. After computing each new variable, the code appends the variable to the frame results table. The figure shows an example of a member frame table. The first two elements contain the start and stop time of the frame interval. The final element contains the features computed for that frame.

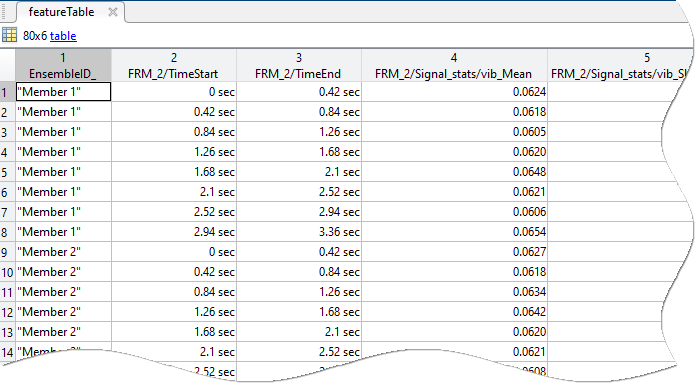
When the variable computations are complete, the code appends the completed frame results table to the member-level frame table. The figure shows an example of the member-level table, which contains the frame results for all members.
The final operation in the member loop is to write the completed member frame table to the ensemble member.
Creation of the feature table output is essentially the same as for the basic case, but each member variable now includes all the segments.
See Also
frameintervals | workspaceEnsemble | grp2idx | readall | correlationWeightedScore | simulationEnsembleDatastore | fileEnsembleDatastore | reset | unique | read | readMemberData | writeToLastMemberRead | refresh