Similarity-Based Remaining Useful Life Estimation
This example shows how to build a complete Remaining Useful Life (RUL) estimation workflow including the steps for preprocessing, selecting trendable features, constructing a health indicator by sensor fusion, training similarity RUL estimators, and validating prognostics performance. The example uses the training data from the PHM2008 challenge dataset [1].
Data Preparation
Since the dataset is small it is feasible to load the whole degradation data into memory. Download and unzip the data set to the current directory. Use the helperLoadData helper function to load and convert the training text file to a cell array of timetables. The training data contains 260 run-to-failure simulations. This group of measurements is called an "ensemble".
url = 'https://ssd.mathworks.com/supportfiles/nnet/data/TurbofanEngineDegradationSimulationData.zip'; websave('TurbofanEngineDegradationSimulationData.zip',url); unzip('TurbofanEngineDegradationSimulationData.zip') degradationData = helperLoadData('train_FD002.txt'); degradationData(1:5)
ans=5×1 cell array
149×26 table
269×26 table
206×26 table
235×26 table
154×26 table
Each ensemble member is a table with 26 columns. The columns contain data for the machine ID, time stamp, 3 operating conditions and 21 sensor measurements.
head(degradationData{1}) id time op_setting_1 op_setting_2 op_setting_3 sensor_1 sensor_2 sensor_3 sensor_4 sensor_5 sensor_6 sensor_7 sensor_8 sensor_9 sensor_10 sensor_11 sensor_12 sensor_13 sensor_14 sensor_15 sensor_16 sensor_17 sensor_18 sensor_19 sensor_20 sensor_21
__ ____ ____________ ____________ ____________ ________ ________ ________ ________ ________ ________ ________ ________ ________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________
1 1 34.998 0.84 100 449.44 555.32 1358.6 1137.2 5.48 8 194.64 2222.7 8341.9 1.02 42.02 183.06 2387.7 8048.6 9.3461 0.02 334 2223 100 14.73 8.8071
1 2 41.998 0.8408 100 445 549.9 1353.2 1125.8 3.91 5.71 138.51 2211.6 8304 1.02 42.2 130.42 2387.7 8072.3 9.3774 0.02 330 2212 100 10.41 6.2665
1 3 24.999 0.6218 60 462.54 537.31 1256.8 1047.5 7.05 9.02 175.71 1915.1 8001.4 0.94 36.69 164.22 2028 7864.9 10.894 0.02 309 1915 84.93 14.08 8.6723
1 4 42.008 0.8416 100 445 549.51 1354 1126.4 3.91 5.71 138.46 2211.6 8304 1.02 41.96 130.72 2387.6 8068.7 9.3528 0.02 329 2212 100 10.59 6.4701
1 5 25 0.6203 60 462.54 537.07 1257.7 1047.9 7.05 9.03 175.05 1915.1 7993.2 0.94 36.89 164.31 2028 7861.2 10.896 0.02 309 1915 84.93 14.13 8.5286
1 6 25.005 0.6205 60 462.54 537.02 1266.4 1048.7 7.05 9.03 175.17 1915.2 7996.1 0.94 36.78 164.27 2028 7868.9 10.891 0.02 306 1915 84.93 14.28 8.559
1 7 42.004 0.8409 100 445 549.74 1347.5 1127.2 3.91 5.71 138.71 2211.6 8307.8 1.02 42.19 130.49 2387.7 8075.5 9.3753 0.02 330 2212 100 10.62 6.4227
1 8 20.002 0.7002 100 491.19 607.44 1481.7 1252.4 9.35 13.65 334.41 2323.9 8709.1 1.08 44.27 315.11 2388 8049.3 9.2369 0.02 365 2324 100 24.33 14.799
Split the degradation data into a training data set and a validation data set for later performance evaluation.
rng('default') % To make sure the results are repeatable numEnsemble = length(degradationData); numFold = 5; cv = cvpartition(numEnsemble, 'KFold', numFold); trainData = degradationData(training(cv, 1)); validationData = degradationData(test(cv, 1));
Specify groups of variables of interest.
varNames = string(degradationData{1}.Properties.VariableNames);
timeVariable = varNames{2};
conditionVariables = varNames(3:5);
dataVariables = varNames(6:26);Visualize a sample of the ensemble data.
nsample = 10;
figure
helperPlotEnsemble(trainData, timeVariable, ...
[conditionVariables(1:2) dataVariables(1:2)], nsample)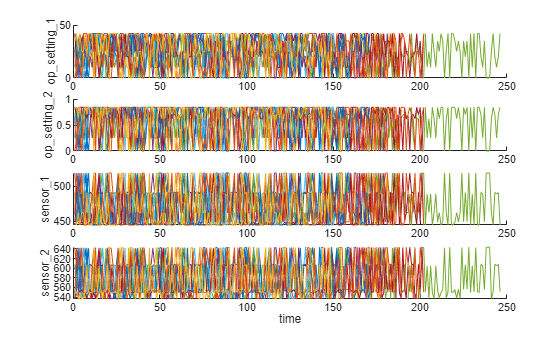
Working Regime Clustering
As shown in the previous section, there is no clear trend showing the degradation process in each run-to-failure measurement. In this and the next section, the operating conditions will be used to extract clearer degradation trends from sensor signals.
Notice that each ensemble member contains 3 operating conditions: "op_setting_1", "op_setting_2", and "op_setting_3". First, let's extract the table from each cell and concatenate them into a single table.
trainDataUnwrap = vertcat(trainData{:});
opConditionUnwrap = trainDataUnwrap(:, cellstr(conditionVariables));Visualize all operating points on a 3D scatter plot. It clearly shows 6 regimes and the points in each regime are in very close proximity.
figure helperPlotClusters(opConditionUnwrap)

Let's use clustering techniques to locate the 6 clusters automatically. Here, the K-means algorithm is used. K-means is one of the most popular clustering algorithms, but it can result in local optima. It is a good practice to repeat the K-means clustering algorithm several times with different initial conditions and pick the results with the lowest cost. In this case, the algorithm runs 5 times and the results are identical.
opts = statset('Display', 'final'); [clusterIndex, centers] = kmeans(table2array(opConditionUnwrap), 6, ... 'Distance', 'sqeuclidean', 'Replicates', 5, 'Options', opts);
Replicate 1, 1 iterations, total sum of distances = 0.331378. Replicate 2, 1 iterations, total sum of distances = 0.331378. Replicate 3, 1 iterations, total sum of distances = 0.331378. Replicate 4, 1 iterations, total sum of distances = 0.331378. Replicate 5, 1 iterations, total sum of distances = 0.331378. Best total sum of distances = 0.331378
Visualize the clustering results and the identified cluster centroids.
figure helperPlotClusters(opConditionUnwrap, clusterIndex, centers)

As the plot illustrates, the clustering algorithm successfully finds the 6 working regimes.
Working Regime Normalization
Let's perform a normalization on measurements grouped by different working regimes. First, compute the mean and standard deviation of each sensor measurement grouped by the working regimes identified in the last section.
centerstats = struct('Mean', table(), 'SD', table()); for v = dataVariables centerstats.Mean.(char(v)) = splitapply(@mean, trainDataUnwrap.(char(v)), clusterIndex); centerstats.SD.(char(v)) = splitapply(@std, trainDataUnwrap.(char(v)), clusterIndex); end centerstats.Mean
ans=6×21 table
489.0500 604.9094 1.5020e+03 1.3112e+03 10.5200 15.4933 394.3264 2.3190e+03 8.7858e+03 1.2600 45.4869 371.4472 2.3882e+03 8.1355e+03 8.6645 0.0300 369.6923 2319 100 28.5273 17.1155
462.5400 536.8592 1.2627e+03 1.0502e+03 7.0500 9.0277 175.4310 1.9154e+03 8.0156e+03 0.9399 36.7983 164.5749 2.0283e+03 7.8786e+03 10.9134 0.0200 307.3386 1915 84.9300 14.2633 8.5587
445 549.7039 1.3544e+03 1.1277e+03 3.9100 5.7158 138.6336 2.2120e+03 8.3281e+03 1.0202 42.1460 130.5532 2.3881e+03 8.0897e+03 9.3745 0.0200 331.0583 2212 100 10.5880 6.3516
491.1900 607.5606 1.4855e+03 1.2530e+03 9.3500 13.6566 334.5001 2.3240e+03 8.7300e+03 1.0777 44.4460 314.8797 2.3882e+03 8.0661e+03 9.2325 0.0221 365.3689 2324 100 24.4549 14.6738
518.6700 642.6744 1.5903e+03 1.4087e+03 14.6200 21.6098 553.3719 2.3881e+03 9.0633e+03 1.3000 47.5383 521.4148 2.3881e+03 8.1420e+03 8.4419 0.0300 393.1829 2388 100 38.8195 23.2916
449.4400 555.7971 1.3667e+03 1.1315e+03 5.4800 8.0003 194.4480 2.2230e+03 8.3564e+03 1.0204 41.9809 183.0256 2.3881e+03 8.0725e+03 9.3319 0.0200 334.2246 2223 100 14.8307 8.8983
centerstats.SD
ans=6×21 table
1.0346e-11 0.4758 5.8057 8.5359 3.2687e-13 0.0047 0.6736 0.0953 18.8192 1.7552e-04 0.2538 0.5362 0.0982 16.5074 0.0384 6.6965e-16 1.4900 0 0 0.1444 0.0860
4.6615e-12 0.3608 5.2850 6.8365 1.1370e-13 0.0042 0.4486 0.2701 14.4793 8.7595e-04 0.2084 0.3449 0.2859 13.4274 0.0433 3.4003e-16 1.2991 0 3.5246e-12 0.1122 0.0664
0 0.4328 5.6422 7.6564 1.1014e-13 0.0049 0.4397 0.3048 18.3251 0.0016 0.2396 0.3401 0.3286 16.7729 0.0375 1.0652e-15 1.4114 0 0 0.1083 0.0647
1.8362e-11 0.4634 5.7888 7.7768 2.5049e-13 0.0047 0.6046 0.1283 17.5800 0.0042 0.2383 0.4984 0.1316 15.4567 0.0389 0.0041 1.4729 0 0 0.1353 0.0796
1.2279e-11 0.4967 6.0349 8.9734 6.5730e-14 0.0013 0.8699 0.0708 19.8890 2.7314e-14 0.2651 0.7371 0.0705 17.1049 0.0373 6.6619e-16 1.5332 0 0 0.1787 0.1065
1.4098e-11 0.4401 5.6013 7.4461 2.2828e-13 0.0018 0.4756 0.2863 17.4460 0.0020 0.2308 0.3763 0.3077 15.8250 0.0381 3.3656e-16 1.4133 0 0 0.1135 0.0672
The statistics in each regime can be used to normalize the training data. For each ensemble member, extract the operating points of each row, compute its distance to each cluster centers and find the nearest cluster center. Then, for each sensor measurement, subtract the mean and divide it by the standard deviation of that cluster. If the standard deviation is close to 0, set the normalized sensor measurement to 0 because a nearly constant sensor measurement is not useful for remaining useful life estimation. Refer to the last section, "Helper Functions", for more details on regimeNormalization function.
trainDataNormalized = cellfun(@(data) regimeNormalization(data, centers, centerstats), ... trainData, 'UniformOutput', false);
Visualize the data normalized by working regime. Degradation trends for some sensor measurements are now revealed after normalization.
figure helperPlotEnsemble(trainDataNormalized, timeVariable, dataVariables(1:4), nsample)
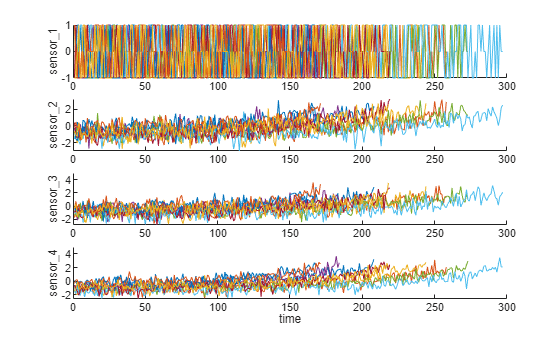
Trendability Analysis
Now select the most trendable sensor measurements to construct a health indicator for prediction. For each sensor measurement, a linear degradation model is estimated and the slopes of the signals are ranked.
numSensors = length(dataVariables); signalSlope = zeros(numSensors, 1); warn = warning('off'); for ct = 1:numSensors tmp = cellfun(@(tbl) tbl(:, cellstr(dataVariables(ct))), trainDataNormalized, 'UniformOutput', false); mdl = linearDegradationModel(); % create model fit(mdl, tmp); % train mode signalSlope(ct) = mdl.Theta; end warning(warn);
Sort the signal slopes and select 8 sensors with the largest slopes.
[~, idx] = sort(abs(signalSlope), 'descend');
sensorTrended = sort(idx(1:8))sensorTrended = 8×1
2
3
4
7
11
12
15
17
Visualize the selected trendable sensor measurements.
figure helperPlotEnsemble(trainDataNormalized, timeVariable, dataVariables(sensorTrended(3:6)), nsample)
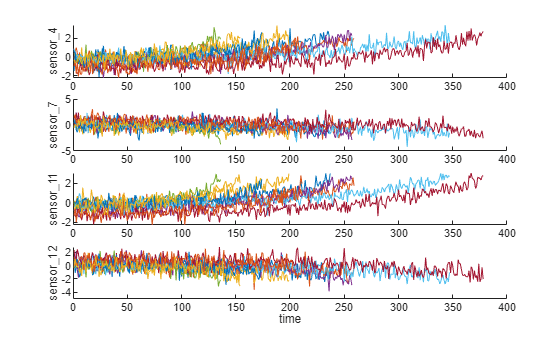
Notice that some of the most trendable signals show positive trends, while others show negative trends.
Construct Health Indicator
This section focuses on fusing the sensor measurements into a single health indicator, with which a similarity-based model is trained.
All the run-to-failure data is assumed to start with a healthy condition. The health condition at the beginning is assigned a value of 1 and the health condition at failure is assigned a value of 0. The health condition is assumed to be linearly degrading from 1 to 0 over time. This linear degradation is used to help fuse the sensor values. More sophisticated sensor fusion techniques are described in the literature [2-5].
for j=1:numel(trainDataNormalized) data = trainDataNormalized{j}; rul = max(data.time)-data.time; data.health_condition = rul / max(rul); trainDataNormalized{j} = data; end
Visualize the health condition.
figure
helperPlotEnsemble(trainDataNormalized, timeVariable, "health_condition", nsample)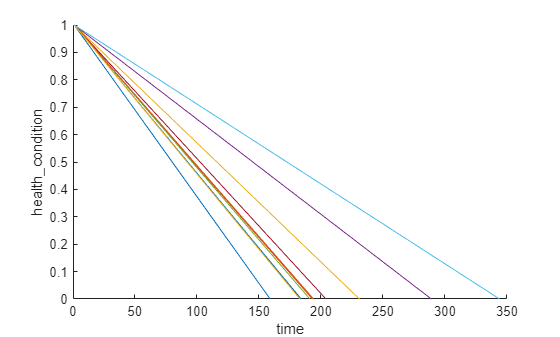
The health condition of all ensemble members change from 1 to 0 with varying degrading speeds.
Now fit a linear regression model of Health Condition with the most trended sensor measurements as regressors:
Health Condition ~ 1 + Sensor2 + Sensor3 + Sensor4 + Sensor7 + Sensor11 + Sensor12 + Sensor15 + Sensor17
trainDataNormalizedUnwrap = vertcat(trainDataNormalized{:});
sensorToFuse = dataVariables(sensorTrended);
X = trainDataNormalizedUnwrap{:, cellstr(sensorToFuse)};
y = trainDataNormalizedUnwrap.health_condition;
regModel = fitlm(X,y);
bias = regModel.Coefficients.Estimate(1)bias = 0.5000
weights = regModel.Coefficients.Estimate(2:end)
weights = 8×1
-0.0323
-0.0300
-0.0527
0.0057
-0.0646
0.0054
-0.0431
-0.0379
Construct a single health indicator by multiplying the sensor measurements with their associated weights.
trainDataFused = cellfun(@(data) degradationSensorFusion(data, sensorToFuse, weights), trainDataNormalized, ... 'UniformOutput', false);
Visualize the fused health indicator for training data.
figure helperPlotEnsemble(trainDataFused, [], 1, nsample) xlabel('Time') ylabel('Health Indicator') title('Training Data')
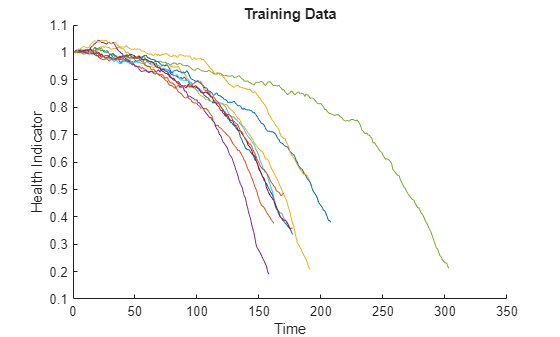
The data from multiple sensors are fused into a single health indicator. The health indicator is smoothed by a moving average filter. See helper function "degradationSensorFusion" in the last section for more details.
Apply Same Operation to Validation Data
Repeat the regime normalization and sensor fusion process with the validation data set.
validationDataNormalized = cellfun(@(data) regimeNormalization(data, centers, centerstats), ... validationData, 'UniformOutput', false); validationDataFused = cellfun(@(data) degradationSensorFusion(data, sensorToFuse, weights), ... validationDataNormalized, 'UniformOutput', false);
Visualize the health indicator for validation data.
figure helperPlotEnsemble(validationDataFused, [], 1, nsample) xlabel('Time') ylabel('Health Indicator') title('Validation Data')
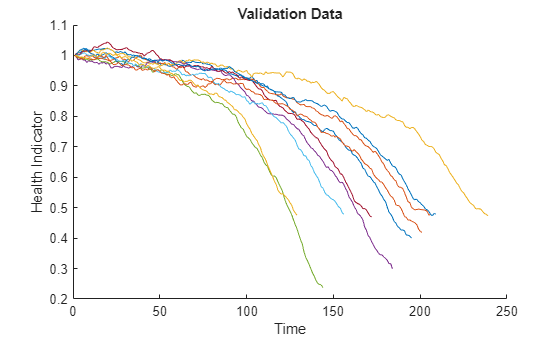
Build Similarity RUL Model
Now build a residual-based similarity RUL model using the training data. In this setting, the model tries to fit each fused data with a 2nd order polynomial.
The distance between data and data is computed by the 1-norm of the residual
where is the health indicator of machine , is the estimated health indicator of machine using the 2nd order polynomial model identified in machine .
The similarity score is computed by the following formula
Given one ensemble member in the validation data set, the model will find the nearest 50 ensemble members in the training data set, fit a probability distribution based on the 50 ensemble members, and use the median of the distribution as an estimate of RUL.
mdl = residualSimilarityModel(... 'Method', 'poly2',... 'Distance', 'absolute',... 'NumNearestNeighbors', 50,... 'Standardize', 1); fit(mdl, trainDataFused);
Performance Evaluation
To evaluate the similarity RUL model, use 50%, 70% and 90% of a sample validation data to predict its RUL.
breakpoint = [0.5, 0.7, 0.9];
validationDataTmp = validationDataFused{3}; % use one validation data for illustrationUse the validation data before the first breakpoint, which is 50% of the lifetime.
bpidx = 1; validationDataTmp50 = validationDataTmp(1:ceil(end*breakpoint(bpidx)),:); trueRUL = length(validationDataTmp) - length(validationDataTmp50); [estRUL, ciRUL, pdfRUL] = predictRUL(mdl, validationDataTmp50);
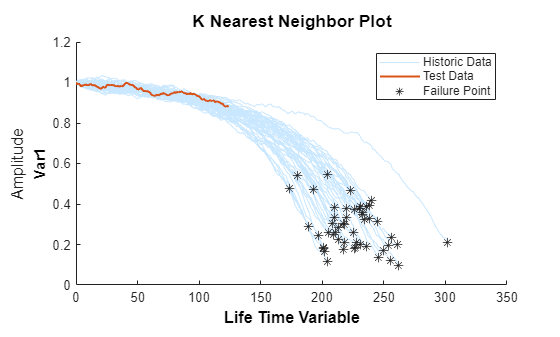
Visualize the validation data truncated at 50% and its nearest neighbors.
figure compare(mdl, validationDataTmp50);
Visualize the estimated RUL compared to the true RUL and the probability distribution of the estimated RUL.
figure helperPlotRULDistribution(trueRUL, estRUL, pdfRUL, ciRUL)
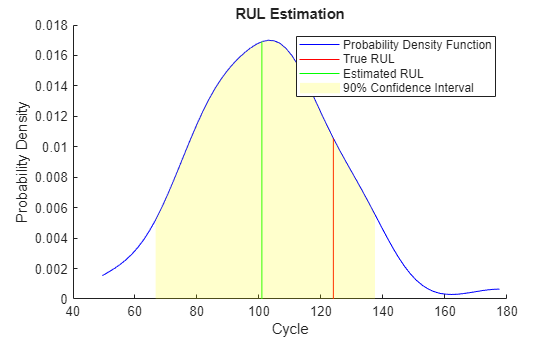
There is a relatively large error between the estimated RUL and the true RUL when the machine is in an intermediate health stage. In this example, the most similar 10 curves are close at the beginning, but bifurcate when they approach the failure state, resulting in roughly two modes in the RUL distribution.
Use the validation data before the second breakpoint, which is 70% of the lifetime.
bpidx = 2; validationDataTmp70 = validationDataTmp(1:ceil(end*breakpoint(bpidx)), :); trueRUL = length(validationDataTmp) - length(validationDataTmp70); [estRUL,ciRUL,pdfRUL] = predictRUL(mdl, validationDataTmp70); figure compare(mdl, validationDataTmp70);
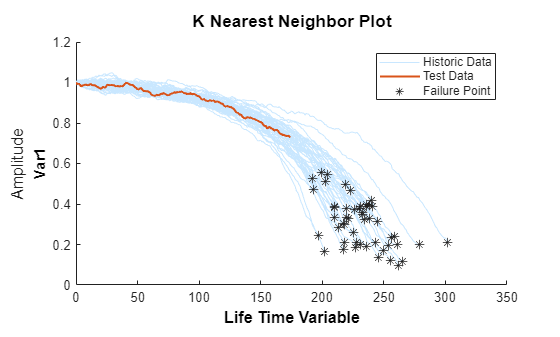
figure helperPlotRULDistribution(trueRUL, estRUL, pdfRUL, ciRUL)
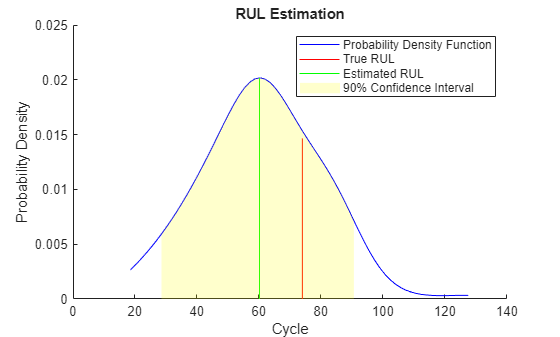
When more data is observed, the RUL estimation is enhanced.
Use the validation data before the third breakpoint, which is 90% of the lifetime.
bpidx = 3; validationDataTmp90 = validationDataTmp(1:ceil(end*breakpoint(bpidx)), :); trueRUL = length(validationDataTmp) - length(validationDataTmp90); [estRUL,ciRUL,pdfRUL] = predictRUL(mdl, validationDataTmp90); figure compare(mdl, validationDataTmp90);
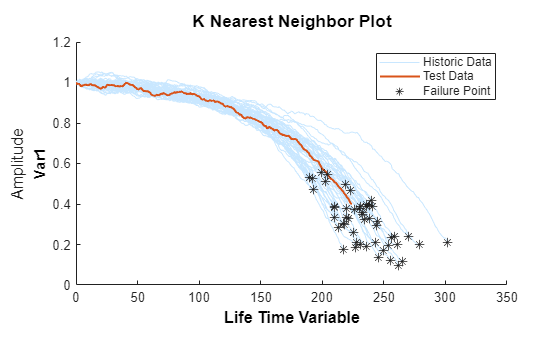
figure helperPlotRULDistribution(trueRUL, estRUL, pdfRUL, ciRUL)
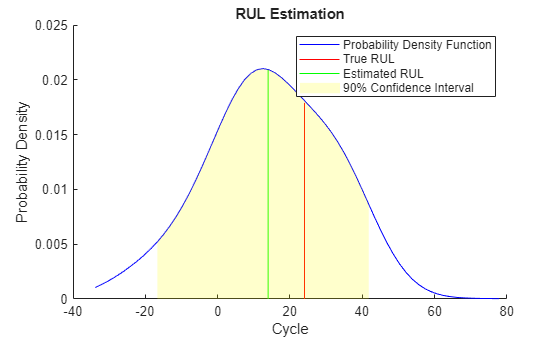
When the machine is close to failure, the RUL estimation is even more enhanced in this example.
Now repeat the same evaluation procedure for the whole validation data set and compute the error between estimated RUL and true RUL for each breakpoint.
numValidation = length(validationDataFused); numBreakpoint = length(breakpoint); error = zeros(numValidation, numBreakpoint); for dataIdx = 1:numValidation tmpData = validationDataFused{dataIdx}; for bpidx = 1:numBreakpoint tmpDataTest = tmpData(1:ceil(end*breakpoint(bpidx)), :); trueRUL = length(tmpData) - length(tmpDataTest); [estRUL, ~, ~] = predictRUL(mdl, tmpDataTest); error(dataIdx, bpidx) = estRUL - trueRUL; end end
Visualize the histogram of the error for each breakpoint together with its probability distribution.
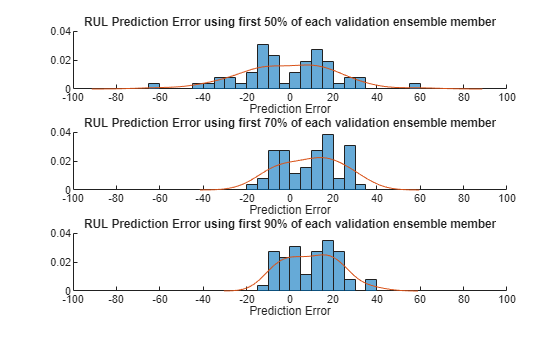
[pdf50, x50] = ksdensity(error(:, 1)); [pdf70, x70] = ksdensity(error(:, 2)); [pdf90, x90] = ksdensity(error(:, 3)); figure ax(1) = subplot(3,1,1); hold on histogram(error(:, 1), 'BinWidth', 5, 'Normalization', 'pdf') plot(x50, pdf50) hold off xlabel('Prediction Error') title('RUL Prediction Error using first 50% of each validation ensemble member') ax(2) = subplot(3,1,2); hold on histogram(error(:, 2), 'BinWidth', 5, 'Normalization', 'pdf') plot(x70, pdf70) hold off xlabel('Prediction Error') title('RUL Prediction Error using first 70% of each validation ensemble member') ax(3) = subplot(3,1,3); hold on histogram(error(:, 3), 'BinWidth', 5, 'Normalization', 'pdf') plot(x90, pdf90) hold off xlabel('Prediction Error') title('RUL Prediction Error using first 90% of each validation ensemble member') linkaxes(ax)
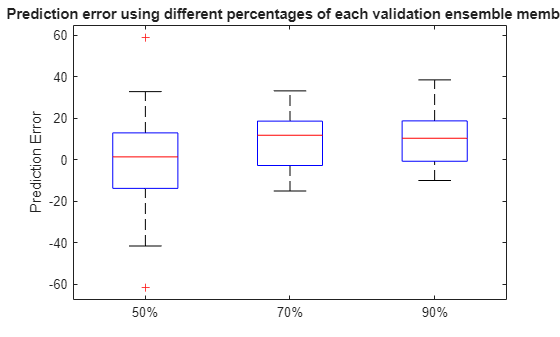
Plot the prediction error in a box plot to visualize the median, 25-75 quantile and outliers.
figure boxplot(error, 'Labels', {'50%', '70%', '90%'}) ylabel('Prediction Error') title('Prediction error using different percentages of each validation ensemble member')
Compute and visualize the mean and standard deviation of the prediction error.
errorMean = mean(error)
errorMean = 1×3
-1.1217 9.5186 9.6540
errorMedian = median(error)
errorMedian = 1×3
1.3798 11.8172 10.3457
errorSD = std(error)
errorSD = 1×3
21.7315 13.5194 12.3083
figure errorbar([50 70 90], errorMean, errorSD, '-o', 'MarkerEdgeColor','r') xlim([40, 100]) xlabel('Percentage of validation data used for RUL prediction') ylabel('Prediction Error') legend('Mean Prediction Error with 1 Standard Deviation Error bar', 'Location', 'south')

It is shown that the error becomes more concentrated around 0 (less outliers) as more data is observed.
References
[1] A. Saxena and K. Goebel (2008). "PHM08 Challenge Data Set", NASA Ames Prognostics Data Repository (http://ti.arc.nasa.gov/project/prognostic-data-repository), NASA Ames Research Center, Moffett Field, CA
[2] Roemer, Michael J., Gregory J. Kacprzynski, and Michael H. Schoeller. "Improved diagnostic and prognostic assessments using health management information fusion." AUTOTESTCON Proceedings, 2001. IEEE Systems Readiness Technology Conference. IEEE, 2001.
[3] Goebel, Kai, and Piero Bonissone. "Prognostic information fusion for constant load systems." Information Fusion, 2005 8th International Conference on. Vol. 2. IEEE, 2005.
[4] Wang, Peng, and David W. Coit. "Reliability prediction based on degradation modeling for systems with multiple degradation measures." Reliability and Maintainability, 2004 Annual Symposium-RAMS. IEEE, 2004.
[5] Jardine, Andrew KS, Daming Lin, and Dragan Banjevic. "A review on machinery diagnostics and prognostics implementing condition-based maintenance." Mechanical systems and signal processing 20.7 (2006): 1483-1510.
Helper Functions
function data = regimeNormalization(data, centers, centerstats) % Perform normalization for each observation (row) of the data % according to the cluster the observation belongs to. conditionIdx = 3:5; dataIdx = 6:26; % Perform row-wise operation data{:, dataIdx} = table2array(... rowfun(@(row) localNormalize(row, conditionIdx, dataIdx, centers, centerstats), ... data, 'SeparateInputs', false)); end function rowNormalized = localNormalize(row, conditionIdx, dataIdx, centers, centerstats) % Normalization operation for each row. % Get the operating points and sensor measurements ops = row(1, conditionIdx); sensor = row(1, dataIdx); % Find which cluster center is the closest dist = sum((centers - ops).^2, 2); [~, idx] = min(dist); % Normalize the sensor measurements by the mean and standard deviation of the cluster. % Reassign NaN and Inf to 0. rowNormalized = (sensor - centerstats.Mean{idx, :}) ./ centerstats.SD{idx, :}; rowNormalized(isnan(rowNormalized) | isinf(rowNormalized)) = 0; end function dataFused = degradationSensorFusion(data, sensorToFuse, weights) % Combine measurements from different sensors according % to the weights, smooth the fused data and offset the data % so that all the data start from 1 % Fuse the data according to weights dataToFuse = data{:, cellstr(sensorToFuse)}; dataFusedRaw = dataToFuse*weights; % Smooth the fused data with moving mean stepBackward = 10; stepForward = 10; dataFused = movmean(dataFusedRaw, [stepBackward stepForward]); % Offset the data to 1 dataFused = dataFused + 1 - dataFused(1); end