ClassificationPartitionedLinearECOC
Namespace: classreg.learning.partition
Superclasses: ClassificationPartitionedModel
Cross-validated linear error-correcting output codes model for multiclass classification of high-dimensional data
Description
ClassificationPartitionedLinearECOC is a set of
error-correcting output codes (ECOC) models composed of linear classification models,
trained on cross-validated folds. Estimate the quality of classification by
cross-validation using one or more “kfold” functions: kfoldPredict, kfoldLoss, kfoldMargin, and kfoldEdge.
Every “kfold” method uses models trained on in-fold observations to predict the response for out-of-fold observations. For example, suppose that you cross-validate using five folds. In this case, the software randomly assigns each observation into five roughly equal-sized groups. The training fold contains four of the groups (that is, roughly 4/5 of the data) and the test fold contains the other group (that is, roughly 1/5 of the data). In this case, cross-validation proceeds as follows.
The software trains the first model (stored in
CVMdl.Trained{1}) using the observations in the last four groups and reserves the observations in the first group for validation.The software trains the second model (stored in
CVMdl.Trained{2}) using the observations in the first group and last three groups. The software reserves the observations in the second group for validation.The software proceeds in a similar fashion for the third, fourth, and fifth models.
If you validate by calling kfoldPredict, it computes predictions for
the observations in group 1 using the first model, group 2 for the second model, and so
on. In short, the software estimates a response for every observation using the model
trained without that observation.
Note
ClassificationPartitionedLinearECOC model
objects do not store the predictor data set.
Construction
CVMdl = fitcecoc(X,Y,'Learners',t,Name,Value) returns a
cross-validated, linear ECOC model when:
tis'Linear'or a template object returned bytemplateLinear.Nameis one of'CrossVal','CVPartition','Holdout', or'KFold'.
For more details, see fitcecoc.
Properties
Methods
| kfoldEdge | Classification edge for observations not used for training |
| kfoldLoss | Classification loss for observations not used in training |
| kfoldMargin | Classification margins for observations not used in training |
| kfoldPredict | Predict labels for observations not used for training |
Copy Semantics
Value. To learn how value classes affect copy operations, see Copying Objects.
Examples
Load the NLP data set.
load nlpdataX is a sparse matrix of predictor data, and Y is a categorical vector of class labels.
Cross-validate a multiclass, linear classification model that can identify which MATLAB® toolbox a documentation web page is from based on counts of words on the page.
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners','linear','CrossVal','on')
CVMdl =
ClassificationPartitionedLinearECOC
CrossValidatedModel: 'LinearECOC'
ResponseName: 'Y'
NumObservations: 31572
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: [comm dsp ecoder fixedpoint hdlcoder phased physmod simulink stats supportpkg symbolic vision xpc]
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedLinearECOC cross-validated model. Because fitcecoc implements 10-fold cross-validation by default, CVMdl.Trained contains a 10-by-1 cell vector of ten CompactClassificationECOC models that contain the results of training ECOC models composed of binary, linear classification models for each of the folds.
Estimate labels for out-of-fold observations and estimate the generalization error by passing CVMdl to kfoldPredict and kfoldLoss, respectively.
oofLabels = kfoldPredict(CVMdl); ge = kfoldLoss(CVMdl)
ge = 0.0958
The estimated generalization error is about 10% misclassified observations.
To improve generalization error, try specifying another solver, such as LBFGS. To change default options when training ECOC models composed of linear classification models, create a linear classification model template using templateLinear, and then pass the template to fitcecoc.
To determine a good lasso-penalty strength for an ECOC model composed of linear classification models that use logistic regression learners, implement 5-fold cross-validation.
Load the NLP data set.
load nlpdataX is a sparse matrix of predictor data, and Y is a categorical vector of class labels.
For simplicity, use the label 'others' for all observations in Y that are not 'simulink', 'dsp', or 'comm'.
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';Create a set of 11 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-7,-2,11);
Create a linear classification model template that specifies to use logistic regression learners, use lasso penalties with strengths in Lambda, train using SpaRSA, and lower the tolerance on the gradient of the objective function to 1e-8.
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8);
Cross-validate the models. To increase execution speed, transpose the predictor data and specify that the observations are in columns.
X = X'; rng(10); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns','KFold',5);
CVMdl is a ClassificationPartitionedLinearECOC model.
Dissect CVMdl, and each model within it.
numECOCModels = numel(CVMdl.Trained)
numECOCModels = 5
ECOCMdl1 = CVMdl.Trained{1}ECOCMdl1 =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [comm dsp simulink others]
ScoreTransform: 'none'
BinaryLearners: {6×1 cell}
CodingMatrix: [4×6 double]
Properties, Methods
numCLModels = numel(ECOCMdl1.BinaryLearners)
numCLModels = 6
CLMdl1 = ECOCMdl1.BinaryLearners{1}CLMdl1 =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [-1 1]
ScoreTransform: 'logit'
Beta: [34023×11 double]
Bias: [-0.3169 -0.3169 -0.3168 -0.3168 -0.3168 -0.3167 -0.1725 -0.0805 -0.1762 -0.3450 -0.5174]
Lambda: [1.0000e-07 3.1623e-07 1.0000e-06 3.1623e-06 1.0000e-05 3.1623e-05 1.0000e-04 3.1623e-04 1.0000e-03 0.0032 0.0100]
Learner: 'logistic'
Properties, Methods
Because fitcecoc implements 5-fold cross-validation, CVMdl contains a 5-by-1 cell array of CompactClassificationECOC models that the software trains on each fold. The BinaryLearners property of each CompactClassificationECOC model contains the ClassificationLinear models. The number of ClassificationLinear models within each compact ECOC model depends on the number of distinct labels and coding design. Because Lambda is a sequence of regularization strengths, you can think of CLMdl1 as 11 models, one for each regularization strength in Lambda.
Determine how well the models generalize by plotting the averages of the 5-fold classification error for each regularization strength. Identify the regularization strength that minimizes the generalization error over the grid.
ce = kfoldLoss(CVMdl); figure; plot(log10(Lambda),log10(ce)) [~,minCEIdx] = min(ce); minLambda = Lambda(minCEIdx); hold on plot(log10(minLambda),log10(ce(minCEIdx)),'ro'); ylabel('log_{10} 5-fold classification error') xlabel('log_{10} Lambda') legend('MSE','Min classification error') hold off
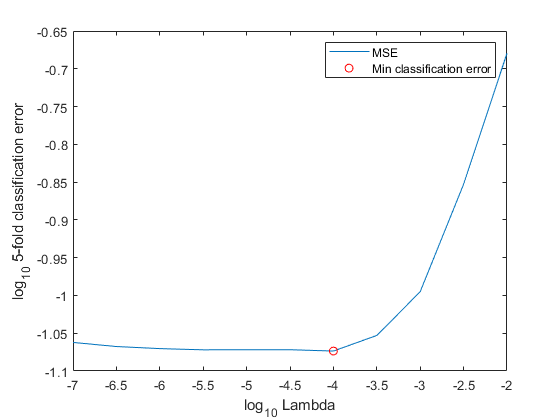
Train an ECOC model composed of linear classification model using the entire data set, and specify the minimal regularization strength.
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',minLambda,'GradientTolerance',1e-8); MdlFinal = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns');
To estimate labels for new observations, pass MdlFinal and the new data to predict.
Extended Capabilities
Version History
Introduced in R2016aSee Also
kfoldLoss | kfoldPredict | fitcecoc | fitclinear | ClassificationECOC | ClassificationLinear