kfoldLoss
Regression loss for observations not used in training
Description
L = kfoldLoss(CVMdl)CVMdl. That is, for every
fold, kfoldLoss estimates the regression loss for
observations that it holds out when it trains using all other observations.
L contains a regression loss for each regularization
strength in the linear regression models that compose CVMdl.
L = kfoldLoss(CVMdl,Name,Value)Name,Value pair
arguments. For example, indicate which folds to use for the loss calculation
or specify the regression-loss function.
Input Arguments
Output Arguments
Examples
Estimate k-Fold Mean Squared Error
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Cross-validate a linear regression model using SVM learners.
rng(1); % For reproducibility CVMdl = fitrlinear(X,Y,'CrossVal','on');
CVMdl is a RegressionPartitionedLinear model. By default, the software implements 10-fold cross validation. You can alter the number of folds using the 'KFold' name-value pair argument.
Estimate the average of the test-sample MSEs.
mse = kfoldLoss(CVMdl)
mse = 0.1735
Alternatively, you can obtain the per-fold MSEs by specifying the name-value pair 'Mode','individual' in kfoldLoss.
Specify Custom Regression Loss
Simulate data as in Estimate k-Fold Mean Squared Error.
rng(1) % For reproducibility n = 1e4; d = 1e3; nz = 0.1; X = sprandn(n,d,nz); Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1); X = X'; % Put observations in columns for faster training
Cross-validate a linear regression model using 10-fold cross-validation. Optimize the objective function using SpaRSA.
CVMdl = fitrlinear(X,Y,'CrossVal','on','ObservationsIn','columns',... 'Solver','sparsa');
CVMdl is a RegressionPartitionedLinear model. It contains the property Trained, which is a 10-by-1 cell array holding RegressionLinear models that the software trained using the training set.
Create an anonymous function that measures Huber loss ( = 1), that is,
where
is the residual for observation j. Custom loss functions must be written in a particular form. For rules on writing a custom loss function, see the 'LossFun' name-value pair argument.
huberloss = @(Y,Yhat,W)sum(W.*((0.5*(abs(Y-Yhat)<=1).*(Y-Yhat).^2) + ...
((abs(Y-Yhat)>1).*abs(Y-Yhat)-0.5)))/sum(W);Estimate the average Huber loss over the folds. Also, obtain the Huber loss for each fold.
mseAve = kfoldLoss(CVMdl,'LossFun',huberloss)mseAve = -0.4448
mseFold = kfoldLoss(CVMdl,'LossFun',huberloss,'Mode','individual')
mseFold = 10×1
-0.4454
-0.4473
-0.4453
-0.4469
-0.4434
-0.4434
-0.4465
-0.4430
-0.4438
-0.4426
Find Good Lasso Penalty Using Cross-Validation
To determine a good lasso-penalty strength for a linear regression model that uses least squares, implement 5-fold cross-validation.
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Create a set of 15 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-5,-1,15);
Cross-validate the models. To increase execution speed, transpose the predictor data and specify that the observations are in columns. Optimize the objective function using SpaRSA.
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','KFold',5,'Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numCLModels = numel(CVMdl.Trained)
numCLModels = 5
CVMdl is a RegressionPartitionedLinear model. Because fitrlinear implements 5-fold cross-validation, CVMdl contains 5 RegressionLinear models that the software trains on each fold.
Display the first trained linear regression model.
Mdl1 = CVMdl.Trained{1}Mdl1 =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000x15 double]
Bias: [-0.0049 -0.0049 -0.0049 -0.0049 -0.0049 -0.0048 -0.0044 -0.0037 -0.0030 -0.0031 -0.0033 -0.0036 -0.0041 -0.0051 -0.0071]
Lambda: [1.0000e-05 1.9307e-05 3.7276e-05 7.1969e-05 1.3895e-04 2.6827e-04 5.1795e-04 1.0000e-03 0.0019 0.0037 0.0072 0.0139 0.0268 0.0518 0.1000]
Learner: 'leastsquares'
Mdl1 is a RegressionLinear model object. fitrlinear constructed Mdl1 by training on the first four folds. Because Lambda is a sequence of regularization strengths, you can think of Mdl1 as 15 models, one for each regularization strength in Lambda.
Estimate the cross-validated MSE.
mse = kfoldLoss(CVMdl);
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a regression model. For each regularization strength, train a linear regression model using the entire data set and the same options as when you cross-validated the models. Determine the number of nonzero coefficients per model.
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the cross-validated MSE and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
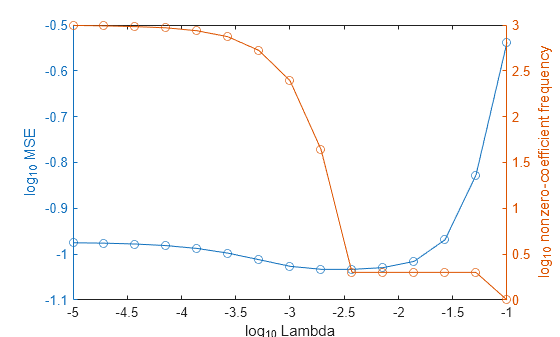
Choose the index of the regularization strength that balances predictor variable sparsity and low MSE (for example, Lambda(10)).
idxFinal = 10;
Extract the model with corresponding to the minimal MSE.
MdlFinal = selectModels(Mdl,idxFinal)
MdlFinal =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000x1 double]
Bias: -0.0050
Lambda: 0.0037
Learner: 'leastsquares'
idxNZCoeff = find(MdlFinal.Beta~=0)
idxNZCoeff = 2×1
100
200
EstCoeff = Mdl.Beta(idxNZCoeff)
EstCoeff = 2×1
1.0051
1.9965
MdlFinal is a RegressionLinear model with one regularization strength. The nonzero coefficients EstCoeff are close to the coefficients that simulated the data.
Extended Capabilities
Version History
Introduced in R2016aSee Also
RegressionPartitionedLinear | RegressionLinear | kfoldPredict | loss
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)