Deep Learning Toolbox
Design, train, analyze, and simulate deep learning networks
Have questions? Contact Sales.
Have questions? Contact Sales.
Deep Learning Toolbox provides functions, apps, and Simulink blocks for designing, implementing, and simulating deep neural networks. The toolbox provides a framework to create and use many types of networks, such as convolutional neural networks (CNNs) and transformers. You can visualize and interpret network predictions, verify network properties, and compress networks with quantization, projection, or pruning.
With the Deep Network Designer app, you can design, edit, and analyze networks interactively, import pretrained models, and export networks to Simulink. The toolbox lets you interoperate with other deep learning frameworks. You can import PyTorch®, TensorFlow™, and ONNX™ models for inference, transfer learning, simulation, and deployment. You can also export models to TensorFlow and ONNX.
You can automatically generate C/C++, CUDA®, and HDL code for trained networks.

Create and use explainable, robust, and scalable deep learning models for automated visual inspection, reduced order modeling, wireless communications, computer vision, and other applications.

Use deep learning with Simulink to test the integration of deep learning models into larger systems. Simulate models based on MATLAB or Python to assess model behavior and system performance.

Exchange deep learning models with Python-based deep learning frameworks. Import PyTorch, TensorFlow, and ONNX models, and export networks to TensorFlow and ONNX with a single line of code. Co-execute Python-based models in MATLAB and Simulink.

Automatically generate optimized C/C++ code (with MATLAB Coder) and CUDA code (with GPU Coder) for deployment to CPUs and GPUs. Generate synthesizable Verilog® and VHDL® code (with Deep Learning HDL Toolbox) for deployment to FPGAs and SoCs.

Visualize training progress and activations of deep neural networks. Use Grad-CAM, D-RISE, and LIME to explain network results. Verify the robustness and reliability of deep neural networks.

Use deep learning algorithms to create CNNs, LSTMs, GANs, and transformers, or perform transfer learning with pretrained models. Automatically label, process, and augment image, video, and signal data for network training.

Accelerate network design, analysis, and transfer learning for built-in and Python-based models by using the Deep Network Designer app. Tune and compare multiple models using the Experiment Manager app.

Compress your deep learning network with quantization, projection, or pruning to reduce its memory footprint and increase inference performance. Assess inference performance and accuracy using the Deep Network Quantizer app.

Speed up deep learning training using GPUs, cloud acceleration, and distributed computing. Train multiple networks in parallel and offload deep learning computations to run in the background.
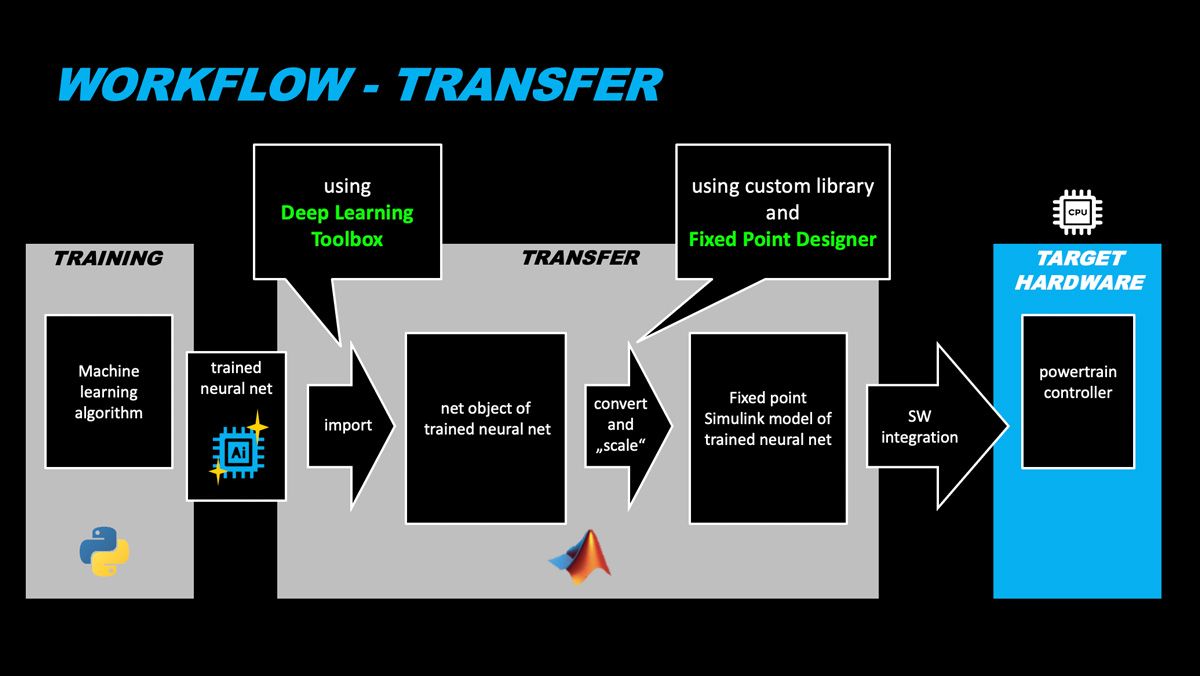
“This was the first time we were simulating sensors with neural networks on one of our powertrain ECUs. Without MATLAB and Simulink, we would have to use a tedious manual coding process that was very slow and error-prone.”
Katja Deuschl, AI developer at Mercedes-Benz
30 days of exploration at your fingertips.
Get pricing information and explore related products.
Your school may already provide access to MATLAB, Simulink, and add-on products through a campus-wide license.
You can also select a web site from the following list
Americas
Europe
Asia Pacific