trainlm
Levenberg-Marquardt backpropagation
Description
net.trainFcn = 'trainlm' sets the network trainFcn
property.
[
trains the network with trainedNet,tr] = train(net,...)trainlm.
trainlm is a network training function that updates weight and bias
values according to Levenberg-Marquardt optimization.
trainlm is often the fastest backpropagation algorithm in the toolbox,
and is highly recommended as a first-choice supervised algorithm, although it does require more
memory than other algorithms.
Training occurs according to trainlm training parameters, shown here
with their default values:
net.trainParam.epochs— Maximum number of epochs to train. The default value is 1000.net.trainParam.goal— Performance goal. The default value is 0.net.trainParam.max_fail— Maximum validation failures. The default value is6.net.trainParam.min_grad— Minimum performance gradient. The default value is1e-7.net.trainParam.mu— Initialmu. The default value is 0.001.net.trainParam.mu_dec— Decrease factor formu. The default value is 0.1.net.trainParam.mu_inc— Increase factor formu. The default value is 10.net.trainParam.mu_max— Maximum value formu. The default value is1e10.net.trainParam.show— Epochs between displays (NaNfor no displays). The default value is 25.net.trainParam.showCommandLine— Generate command-line output. The default value isfalse.net.trainParam.showWindow— Show training GUI. The default value istrue.net.trainParam.time— Maximum time to train in seconds. The default value isinf.
Validation vectors are used to stop training early if the network performance on the
validation vectors fails to improve or remains the same for max_fail epochs
in a row. Test vectors are used as a further check that the network is generalizing well, but
do not have any effect on training.
Examples
Train Neural Network Using trainlm Train Function
This example shows how to train a neural network using the trainlm train function.
Here a neural network is trained to predict body fat percentages.
[x, t] = bodyfat_dataset;
net = feedforwardnet(10, 'trainlm');
net = train(net, x, t);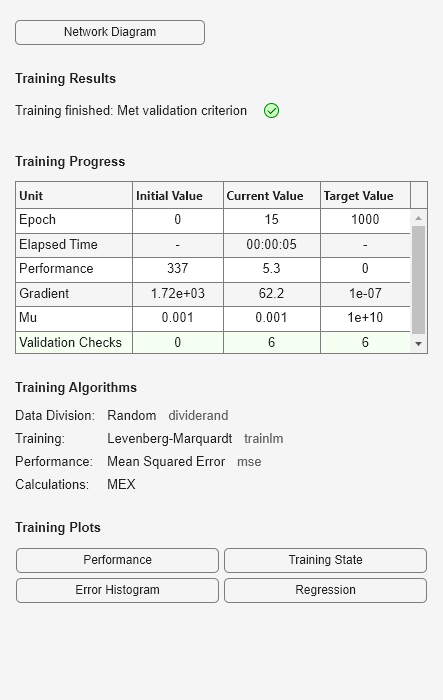
y = net(x);
Input Arguments
Output Arguments
Limitations
This function uses the Jacobian for calculations, which assumes that performance is a mean
or sum of squared errors. Therefore, networks trained with this function must use either the
mse or sse performance function.
More About
Algorithms
trainlm supports training with validation and test vectors if the
network’s NET.divideFcn property is set to a data division function.
Validation vectors are used to stop training early if the network performance on the validation
vectors fails to improve or remains the same for max_fail epochs in a row.
Test vectors are used as a further check that the network is generalizing well, but do not have
any effect on training.
trainlm can train any network as long as its weight, net input, and
transfer functions have derivative functions.
Backpropagation is used to calculate the Jacobian jX of performance
perf with respect to the weight and bias variables X.
Each variable is adjusted according to Levenberg-Marquardt,
jj = jX * jX je = jX * E dX = -(jj+I*mu) \ je
where E is all errors and I is the identity
matrix.
The adaptive value mu is increased by mu_inc until
the change above results in a reduced performance value. The change is then made to the network
and mu is decreased by mu_dec.
Training stops when any of these conditions occurs:
The maximum number of
epochs(repetitions) is reached.The maximum amount of
timeis exceeded.Performance is minimized to the
goal.The performance gradient falls below
min_grad.muexceedsmu_max.Validation performance (validation error) has increased more than
max_failtimes since the last time it decreased (when using validation).
Version History
Introduced before R2006a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)