fitctree
Fit binary decision tree for multiclass classification
Syntax
Description
tree = fitctree(Tbl,ResponseVarName)Tbl and output (response or labels) contained in
Tbl.ResponseVarName. The returned binary tree splits
branching nodes based on the values of a column of
Tbl.
tree = fitctree(___,Name,Value)
Examples
Grow a Classification Tree
Grow a classification tree using the ionosphere data set.
load ionosphere
tc = fitctree(X,Y)tc =
ClassificationTree
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
Control Tree Depth
You can control the depth of the trees using the MaxNumSplits, MinLeafSize, or MinParentSize name-value pair parameters. fitctree grows deep decision trees by default. You can grow shallower trees to reduce model complexity or computation time.
Load the ionosphere data set.
load ionosphereThe default values of the tree depth controllers for growing classification trees are:
n - 1forMaxNumSplits.nis the training sample size.1forMinLeafSize.10forMinParentSize.
These default values tend to grow deep trees for large training sample sizes.
Train a classification tree using the default values for tree depth control. Cross-validate the model by using 10-fold cross-validation.
rng(1); % For reproducibility MdlDefault = fitctree(X,Y,'CrossVal','on');
Draw a histogram of the number of imposed splits on the trees. Also, view one of the trees.
numBranches = @(x)sum(x.IsBranch); mdlDefaultNumSplits = cellfun(numBranches, MdlDefault.Trained); figure; histogram(mdlDefaultNumSplits)
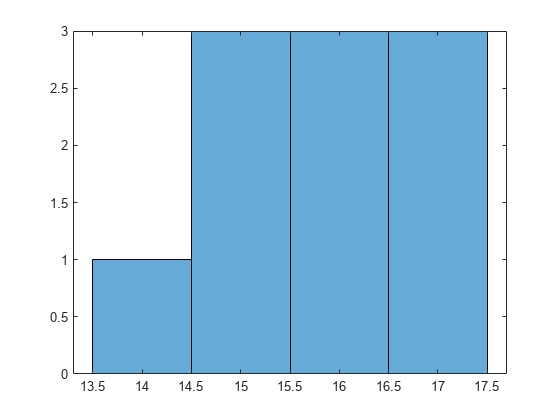
view(MdlDefault.Trained{1},'Mode','graph')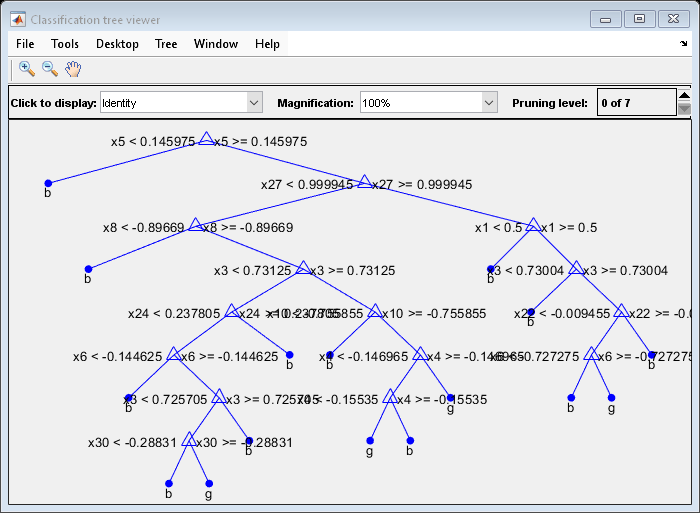
The average number of splits is around 15.
Suppose that you want a classification tree that is not as complex (deep) as the ones trained using the default number of splits. Train another classification tree, but set the maximum number of splits at 7, which is about half the mean number of splits from the default classification tree. Cross-validate the model by using 10-fold cross-validation.
Mdl7 = fitctree(X,Y,'MaxNumSplits',7,'CrossVal','on'); view(Mdl7.Trained{1},'Mode','graph')
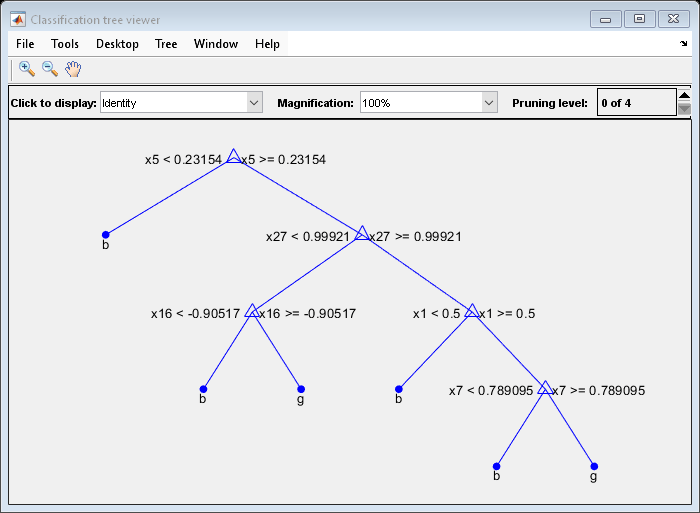
Compare the cross-validation classification errors of the models.
classErrorDefault = kfoldLoss(MdlDefault)
classErrorDefault = 0.1168
classError7 = kfoldLoss(Mdl7)
classError7 = 0.1311
Mdl7 is much less complex and performs only slightly worse than MdlDefault.
Optimize Classification Tree
This example shows how to optimize hyperparameters automatically using fitctree. The example uses Fisher's iris data.
Load Fisher's iris data.
load fisheririsOptimize the cross-validation loss of the classifier, using the data in meas to predict the response in species.
X = meas; Y = species; Mdl = fitctree(X,Y,'OptimizeHyperparameters','auto')
|======================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | MinLeafSize |
| | result | | runtime | (observed) | (estim.) | |
|======================================================================================|
| 1 | Best | 0.066667 | 0.96879 | 0.066667 | 0.066667 | 31 |
| 2 | Accept | 0.066667 | 0.48559 | 0.066667 | 0.066667 | 12 |
| 3 | Best | 0.04 | 0.1699 | 0.04 | 0.040003 | 2 |
| 4 | Accept | 0.66667 | 0.21648 | 0.04 | 0.15796 | 73 |
| 5 | Accept | 0.04 | 0.14794 | 0.04 | 0.040009 | 2 |
| 6 | Accept | 0.66667 | 0.15671 | 0.04 | 0.040012 | 74 |
| 7 | Accept | 0.066667 | 0.14561 | 0.04 | 0.040012 | 20 |
| 8 | Accept | 0.04 | 0.11119 | 0.04 | 0.040008 | 4 |
| 9 | Best | 0.033333 | 0.07511 | 0.033333 | 0.03335 | 1 |
| 10 | Accept | 0.066667 | 0.12097 | 0.033333 | 0.03335 | 7 |
| 11 | Accept | 0.04 | 0.11721 | 0.033333 | 0.033348 | 3 |
| 12 | Accept | 0.066667 | 0.072607 | 0.033333 | 0.033348 | 26 |
| 13 | Accept | 0.046667 | 0.081354 | 0.033333 | 0.033347 | 5 |
| 14 | Accept | 0.033333 | 0.075442 | 0.033333 | 0.03334 | 1 |
| 15 | Accept | 0.033333 | 0.15484 | 0.033333 | 0.033337 | 1 |
| 16 | Accept | 0.033333 | 0.2284 | 0.033333 | 0.033336 | 1 |
| 17 | Accept | 0.066667 | 0.12111 | 0.033333 | 0.033336 | 15 |
| 18 | Accept | 0.33333 | 0.23962 | 0.033333 | 0.033336 | 43 |
| 19 | Accept | 0.066667 | 0.08099 | 0.033333 | 0.033336 | 9 |
| 20 | Accept | 0.066667 | 0.2098 | 0.033333 | 0.033336 | 6 |
|======================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | MinLeafSize |
| | result | | runtime | (observed) | (estim.) | |
|======================================================================================|
| 21 | Accept | 0.066667 | 0.067257 | 0.033333 | 0.033336 | 17 |
| 22 | Accept | 0.066667 | 0.07785 | 0.033333 | 0.033336 | 10 |
| 23 | Accept | 0.066667 | 0.12608 | 0.033333 | 0.033336 | 36 |
| 24 | Accept | 0.33333 | 0.088971 | 0.033333 | 0.034075 | 54 |
| 25 | Accept | 0.04 | 0.10545 | 0.033333 | 0.034054 | 2 |
| 26 | Accept | 0.04 | 0.21242 | 0.033333 | 0.034022 | 3 |
| 27 | Accept | 0.04 | 0.06971 | 0.033333 | 0.033997 | 4 |
| 28 | Accept | 0.066667 | 0.097256 | 0.033333 | 0.033973 | 23 |
| 29 | Accept | 0.066667 | 0.11986 | 0.033333 | 0.033946 | 8 |
| 30 | Accept | 0.066667 | 0.063491 | 0.033333 | 0.033922 | 13 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 29.8173 seconds
Total objective function evaluation time: 5.008
Best observed feasible point:
MinLeafSize
___________
1
Observed objective function value = 0.033333
Estimated objective function value = 0.033922
Function evaluation time = 0.07511
Best estimated feasible point (according to models):
MinLeafSize
___________
1
Estimated objective function value = 0.033922
Estimated function evaluation time = 0.13144


Mdl =
ClassificationTree
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
Unbiased Predictor Importance Estimates
Load the census1994 data set. Consider a model that predicts a person's salary category given their age, working class, education level, martial status, race, sex, capital gain and loss, and number of working hours per week.
load census1994 X = adultdata(:,{'age','workClass','education_num','marital_status','race',... 'sex','capital_gain','capital_loss','hours_per_week','salary'});
Display the number of categories represented in the categorical variables using summary.
summary(X)
Variables:
age: 32561x1 double
Values:
Min 17
Median 37
Max 90
workClass: 32561x1 categorical
Values:
Federal-gov 960
Local-gov 2093
Never-worked 7
Private 22696
Self-emp-inc 1116
Self-emp-not-inc 2541
State-gov 1298
Without-pay 14
NumMissing 1836
education_num: 32561x1 double
Values:
Min 1
Median 10
Max 16
marital_status: 32561x1 categorical
Values:
Divorced 4443
Married-AF-spouse 23
Married-civ-spouse 14976
Married-spouse-absent 418
Never-married 10683
Separated 1025
Widowed 993
race: 32561x1 categorical
Values:
Amer-Indian-Eskimo 311
Asian-Pac-Islander 1039
Black 3124
Other 271
White 27816
sex: 32561x1 categorical
Values:
Female 10771
Male 21790
capital_gain: 32561x1 double
Values:
Min 0
Median 0
Max 99999
capital_loss: 32561x1 double
Values:
Min 0
Median 0
Max 4356
hours_per_week: 32561x1 double
Values:
Min 1
Median 40
Max 99
salary: 32561x1 categorical
Values:
<=50K 24720
>50K 7841
Because there are few categories represented in the categorical variables compared to levels in the continuous variables, the standard CART, predictor-splitting algorithm prefers splitting a continuous predictor over the categorical variables.
Train a classification tree using the entire data set. To grow unbiased trees, specify usage of the curvature test for splitting predictors. Because there are missing observations in the data, specify usage of surrogate splits.
Mdl = fitctree(X,'salary','PredictorSelection','curvature',... 'Surrogate','on');
Estimate predictor importance values by summing changes in the risk due to splits on every predictor and dividing the sum by the number of branch nodes. Compare the estimates using a bar graph.
imp = predictorImportance(Mdl); figure; bar(imp); title('Predictor Importance Estimates'); ylabel('Estimates'); xlabel('Predictors'); h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none';
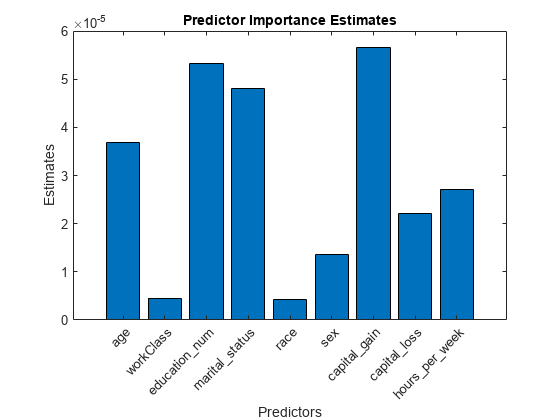
In this case, capital_gain is the most important predictor, followed by education_num.
Optimize Classification Tree on Tall Array
This example shows how to optimize hyperparameters of a classification tree automatically using a tall array. The sample data set airlinesmall.csv is a large data set that contains a tabular file of airline flight data. This example creates a tall table containing the data and uses it to run the optimization procedure.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. If you want to run the example using the local MATLAB session when you have Parallel Computing Toolbox, you can change the global execution environment by using the mapreducer function.
Create a datastore that references the folder location with the data. Select a subset of the variables to work with, and treat 'NA' values as missing data so that datastore replaces them with NaN values. Create a tall table that contains the data in the datastore.
ds = datastore('airlinesmall.csv'); ds.SelectedVariableNames = {'Month','DayofMonth','DayOfWeek',... 'DepTime','ArrDelay','Distance','DepDelay'}; ds.TreatAsMissing = 'NA'; tt = tall(ds) % Tall table
Starting parallel pool (parpool) using the 'local' profile ...
Connected to the parallel pool (number of workers: 6).
tt =
M×7 tall table
Month DayofMonth DayOfWeek DepTime ArrDelay Distance DepDelay
_____ __________ _________ _______ ________ ________ ________
10 21 3 642 8 308 12
10 26 1 1021 8 296 1
10 23 5 2055 21 480 20
10 23 5 1332 13 296 12
10 22 4 629 4 373 -1
10 28 3 1446 59 308 63
10 8 4 928 3 447 -2
10 10 6 859 11 954 -1
: : : : : : :
: : : : : : :
Determine the flights that are late by 10 minutes or more by defining a logical variable that is true for a late flight. This variable contains the class labels. A preview of this variable includes the first few rows.
Y = tt.DepDelay > 10 % Class labelsY = M×1 tall logical array 1 0 1 1 0 1 0 0 : :
Create a tall array for the predictor data.
X = tt{:,1:end-1} % Predictor dataX =
M×6 tall double matrix
10 21 3 642 8 308
10 26 1 1021 8 296
10 23 5 2055 21 480
10 23 5 1332 13 296
10 22 4 629 4 373
10 28 3 1446 59 308
10 8 4 928 3 447
10 10 6 859 11 954
: : : : : :
: : : : : :
Remove rows in X and Y that contain missing data.
R = rmmissing([X Y]); % Data with missing entries removed
X = R(:,1:end-1);
Y = R(:,end); Standardize the predictor variables.
Z = zscore(X);
Optimize hyperparameters automatically using the 'OptimizeHyperparameters' name-value pair argument. Find the optimal 'MinLeafSize' value that minimizes holdout cross-validation loss. (Specifying 'auto' uses 'MinLeafSize'.) For reproducibility, use the 'expected-improvement-plus' acquisition function and set the seeds of the random number generators using rng and tallrng. The results can vary depending on the number of workers and the execution environment for the tall arrays. For details, see Control Where Your Code Runs.
rng('default') tallrng('default') [Mdl,FitInfo,HyperparameterOptimizationResults] = fitctree(Z,Y,... 'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('Holdout',0.3,... 'AcquisitionFunctionName','expected-improvement-plus'))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 3: Completed in 5.6 sec - Pass 2 of 3: Completed in 2.1 sec - Pass 3 of 3: Completed in 3.4 sec Evaluation completed in 13 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.73 sec Evaluation completed in 0.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.2 sec Evaluation completed in 1.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.64 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 0.72 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 5.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.87 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.89 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.68 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 4.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 0.65 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 4.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.63 sec - Pass 2 of 4: Completed in 0.85 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 4.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.2 sec - Pass 2 of 4: Completed in 0.88 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 3 sec Evaluation completed in 6.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.72 sec - Pass 2 of 4: Completed in 0.96 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 4.2 sec Evaluation completed in 7.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.77 sec - Pass 2 of 4: Completed in 0.95 sec - Pass 3 of 4: Completed in 0.65 sec - Pass 4 of 4: Completed in 4.8 sec Evaluation completed in 7.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.79 sec - Pass 2 of 4: Completed in 1 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 5.1 sec Evaluation completed in 8.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.89 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 5.8 sec Evaluation completed in 9.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.63 sec - Pass 4 of 4: Completed in 5.2 sec Evaluation completed in 8.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.6 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.74 sec - Pass 4 of 4: Completed in 4.8 sec Evaluation completed in 9.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.68 sec - Pass 4 of 4: Completed in 3.9 sec Evaluation completed in 7.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.6 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.7 sec - Pass 4 of 4: Completed in 3 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.66 sec - Pass 4 of 4: Completed in 2.5 sec Evaluation completed in 6.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.66 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 5.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.69 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.2 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 0.67 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.3 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 0.65 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.67 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.2 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.73 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.65 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 2.4 sec Evaluation completed in 2.6 sec |======================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | MinLeafSize | | | result | | runtime | (observed) | (estim.) | | |======================================================================================| | 1 | Best | 0.11572 | 197.12 | 0.11572 | 0.11572 | 10 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.4 sec Evaluation completed in 0.56 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.93 sec Evaluation completed in 1.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 0.84 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.4 sec Evaluation completed in 1.6 sec | 2 | Accept | 0.19635 | 10.496 | 0.11572 | 0.12008 | 48298 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.33 sec Evaluation completed in 0.47 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.83 sec Evaluation completed in 0.99 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.68 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 0.74 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.73 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.68 sec - Pass 4 of 4: Completed in 0.77 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.86 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.5 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.75 sec Evaluation completed in 0.87 sec | 3 | Best | 0.1048 | 44.614 | 0.1048 | 0.11431 | 3166 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.3 sec Evaluation completed in 0.45 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.83 sec Evaluation completed in 0.97 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.99 sec - Pass 2 of 4: Completed in 0.68 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 0.73 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.82 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 0.89 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.6 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.5 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.63 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.66 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 4.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.62 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 4.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 1 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 4.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.8 sec Evaluation completed in 0.94 sec | 4 | Best | 0.10094 | 91.723 | 0.10094 | 0.10574 | 180 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.3 sec Evaluation completed in 0.42 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.93 sec Evaluation completed in 1.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.66 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.83 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 0.88 sec Evaluation completed in 4.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.5 sec - Pass 4 of 4: Completed in 0.98 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.5 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.7 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.64 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.97 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.89 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 0.85 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 0.82 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.3 sec Evaluation completed in 1.4 sec | 5 | Best | 0.10087 | 82.84 | 0.10087 | 0.10085 | 219 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.32 sec Evaluation completed in 0.45 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.87 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.66 sec - Pass 3 of 4: Completed in 0.5 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.68 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.68 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.86 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 1 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.85 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.6 sec - Pass 4 of 4: Completed in 0.84 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 0.87 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 0.92 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.77 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.68 sec - Pass 4 of 4: Completed in 0.86 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.77 sec Evaluation completed in 0.93 sec | 6 | Accept | 0.10155 | 61.043 | 0.10087 | 0.10089 | 1089 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.33 sec Evaluation completed in 0.46 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.89 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.85 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.83 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.87 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.98 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.62 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 4.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 4.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 2.7 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.64 sec - Pass 2 of 4: Completed in 0.87 sec - Pass 3 of 4: Completed in 1.2 sec - Pass 4 of 4: Completed in 3.7 sec Evaluation completed in 7.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.73 sec - Pass 2 of 4: Completed in 0.92 sec - Pass 3 of 4: Completed in 0.6 sec - Pass 4 of 4: Completed in 4.4 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.86 sec - Pass 2 of 4: Completed in 1.5 sec - Pass 3 of 4: Completed in 0.64 sec - Pass 4 of 4: Completed in 4.8 sec Evaluation completed in 8.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.9 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 0.65 sec - Pass 4 of 4: Completed in 5.2 sec Evaluation completed in 8.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.73 sec - Pass 4 of 4: Completed in 5.6 sec Evaluation completed in 9.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.5 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 0.75 sec - Pass 4 of 4: Completed in 5.8 sec Evaluation completed in 10 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.3 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.2 sec - Pass 4 of 4: Completed in 5.1 sec Evaluation completed in 9.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.4 sec - Pass 2 of 4: Completed in 1.5 sec - Pass 3 of 4: Completed in 0.7 sec - Pass 4 of 4: Completed in 4.1 sec Evaluation completed in 8.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.4 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 0.71 sec - Pass 4 of 4: Completed in 3.6 sec Evaluation completed in 7.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.5 sec - Pass 2 of 4: Completed in 1.8 sec - Pass 3 of 4: Completed in 0.74 sec - Pass 4 of 4: Completed in 3.2 sec Evaluation completed in 7.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.4 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 0.73 sec - Pass 4 of 4: Completed in 2.8 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.5 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 0.82 sec - Pass 4 of 4: Completed in 2.4 sec Evaluation completed in 7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 2 sec - Pass 2 of 4: Completed in 1.9 sec - Pass 3 of 4: Completed in 0.79 sec - Pass 4 of 4: Completed in 2.3 sec Evaluation completed in 7.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.6 sec - Pass 2 of 4: Completed in 1.8 sec - Pass 3 of 4: Completed in 0.73 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 6.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.6 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 0.79 sec - Pass 4 of 4: Completed in 2.3 sec Evaluation completed in 7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.7 sec - Pass 2 of 4: Completed in 1.9 sec - Pass 3 of 4: Completed in 0.8 sec - Pass 4 of 4: Completed in 1.8 sec Evaluation completed in 6.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.7 sec - Pass 2 of 4: Completed in 1.8 sec - Pass 3 of 4: Completed in 0.77 sec - Pass 4 of 4: Completed in 1.8 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.4 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 0.73 sec - Pass 4 of 4: Completed in 1.8 sec Evaluation completed in 6.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.5 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 1.3 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.5 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 0.73 sec - Pass 4 of 4: Completed in 1.8 sec Evaluation completed in 6.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.3 sec Evaluation completed in 1.5 sec | 7 | Accept | 0.13495 | 241.76 | 0.10087 | 0.10089 | 1 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.31 sec Evaluation completed in 0.44 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.87 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 0.67 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.74 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.85 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 0.89 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 0.6 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.62 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 4.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.2 sec - Pass 2 of 4: Completed in 1.5 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 6.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.69 sec - Pass 2 of 4: Completed in 0.88 sec - Pass 3 of 4: Completed in 0.75 sec - Pass 4 of 4: Completed in 2.1 sec Evaluation completed in 5.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 4.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.84 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 4.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.68 sec - Pass 2 of 4: Completed in 0.85 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 4.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.68 sec - Pass 2 of 4: Completed in 0.91 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 2.4 sec Evaluation completed in 5.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.92 sec - Pass 2 of 4: Completed in 0.86 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 4.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.69 sec - Pass 2 of 4: Completed in 0.91 sec - Pass 3 of 4: Completed in 0.63 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.67 sec - Pass 2 of 4: Completed in 0.86 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.99 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.2 sec - Pass 2 of 4: Completed in 0.9 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.95 sec Evaluation completed in 4.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.73 sec - Pass 2 of 4: Completed in 0.91 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.91 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.76 sec - Pass 2 of 4: Completed in 0.93 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.91 sec Evaluation completed in 1.1 sec | 8 | Accept | 0.10246 | 115.31 | 0.10087 | 0.10089 | 58 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.34 sec Evaluation completed in 0.49 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.87 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.6 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.95 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.94 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.83 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.83 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.77 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.72 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.6 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.3 sec Evaluation completed in 1.4 sec | 9 | Accept | 0.10173 | 77.229 | 0.10087 | 0.10086 | 418 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.32 sec Evaluation completed in 0.46 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.84 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.75 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.68 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.91 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 0.82 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 0.82 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.95 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 4.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 4.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.71 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 5.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.83 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.67 sec - Pass 2 of 4: Completed in 0.87 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.82 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.84 sec - Pass 3 of 4: Completed in 0.62 sec - Pass 4 of 4: Completed in 0.89 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.64 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.88 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.62 sec - Pass 2 of 4: Completed in 0.9 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.86 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.77 sec Evaluation completed in 0.89 sec | 10 | Accept | 0.10114 | 94.532 | 0.10087 | 0.10091 | 123 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.86 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.83 sec Evaluation completed in 0.99 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.73 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.85 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.82 sec - Pass 3 of 4: Completed in 0.64 sec - Pass 4 of 4: Completed in 0.94 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.97 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1.1 sec Evaluation completed in 4.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.84 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 1 sec Evaluation completed in 4.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.63 sec - Pass 2 of 4: Completed in 0.84 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.2 sec - Pass 2 of 4: Completed in 0.83 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.81 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.77 sec Evaluation completed in 0.89 sec | 11 | Best | 0.1008 | 90.637 | 0.1008 | 0.10088 | 178 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.38 sec Evaluation completed in 0.52 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.88 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.59 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.93 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 0.83 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.91 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.85 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 1.1 sec - Pass 2 of 4: Completed in 0.81 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 3.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.82 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.66 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.79 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1.2 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.62 sec - Pass 2 of 4: Completed in 0.85 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 1 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 0.86 sec - Pass 3 of 4: Completed in 1.1 sec - Pass 4 of 4: Completed in 0.96 sec Evaluation completed in 4.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 0.8 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.86 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.69 sec - Pass 2 of 4: Completed in 0.84 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.83 sec Evaluation completed in 3.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.76 sec Evaluation completed in 0.89 sec | 12 | Accept | 0.1008 | 90.267 | 0.1008 | 0.10086 | 179 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.32 sec Evaluation completed in 0.45 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.9 sec Evaluation completed in 1.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.77 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 0.77 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.72 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.74 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 3.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.74 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.83 sec Evaluation completed in 0.97 sec | 13 | Accept | 0.11126 | 32.134 | 0.1008 | 0.10084 | 10251 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.32 sec Evaluation completed in 0.45 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.85 sec Evaluation completed in 0.99 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.75 sec - Pass 3 of 4: Completed in 0.55 sec - Pass 4 of 4: Completed in 0.74 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.7 sec - Pass 3 of 4: Completed in 0.57 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.68 sec - Pass 3 of 4: Completed in 0.53 sec - Pass 4 of 4: Completed in 0.79 sec Evaluation completed in 3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.91 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.86 sec Evaluation completed in 3.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 1 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.71 sec - Pass 3 of 4: Completed in 0.64 sec - Pass 4 of 4: Completed in 0.99 sec Evaluation completed in 3.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 0.58 sec - Pass 4 of 4: Completed in 0.94 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 0.77 sec - Pass 3 of 4: Completed in 0.59 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 0.78 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.9 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 0.72 sec - Pass 3 of 4: Completed in 0.52 sec - Pass 4 of 4: Completed in 0.89 sec Evaluation completed in 3.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.58 sec - Pass 2 of 4: Completed in 0.76 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.8 sec Evaluation completed in 3.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 0.61 sec - Pass 4 of 4: Completed in 0.76 sec Evaluation completed in 3.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.83 sec Evaluation completed in 0.97 sec | 14 | Accept | 0.10154 | 66.262 | 0.1008 | 0.10085 | 736 | Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.36 sec Evaluation completed in 0.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.89 sec Evaluation completed in 1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.74 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 0.67 sec - Pass 3 of 4: Completed in 0.56 sec - Pass 4 of 4: Completed in 0.78 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 0.69 sec - Pass 3 of 4: Completed in 0.54 sec - Pass 4 of 4: Completed in 0.84 sec Evaluation completed in 3.1 sec Evaluating tall expression using the Parallel Pool 'local': Evaluation 0% ...
Mdl =
CompactClassificationTree
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [0 1]
ScoreTransform: 'none'
Properties, Methods
FitInfo = struct with no fields.
HyperparameterOptimizationResults =
BayesianOptimization with properties:
ObjectiveFcn: @createObjFcn/tallObjFcn
VariableDescriptions: [4×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.1004
XAtMinObjective: [1×1 table]
MinEstimatedObjective: 0.1008
XAtMinEstimatedObjective: [1×1 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 3.0367e+03
NextPoint: [1×1 table]
XTrace: [30×1 table]
ObjectiveTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
Input Arguments
Output Arguments
More About
Tips
By default,
Pruneis'on'. However, this specification does not prune the classification tree. To prune a trained classification tree, pass the classification tree toprune.After training a model, you can generate C/C++ code that predicts labels for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation.
Algorithms
References
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
[2] Coppersmith, D., S. J. Hong, and J. R. M. Hosking. “Partitioning Nominal Attributes in Decision Trees.” Data Mining and Knowledge Discovery, Vol. 3, 1999, pp. 197–217.
[3] Loh, W.Y. “Regression Trees with Unbiased Variable Selection and Interaction Detection.” Statistica Sinica, Vol. 12, 2002, pp. 361–386.
[4] Loh, W.Y. and Y.S. Shih. “Split Selection Methods for Classification Trees.” Statistica Sinica, Vol. 7, 1997, pp. 815–840.
Extended Capabilities
Version History
Introduced in R2014a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)