fitrtree
Fit binary decision tree for regression
Syntax
Description
tree = fitrtree(Tbl,ResponseVarName)Tbl and the
output (response) contained in Tbl.ResponseVarName. The
returned tree is a binary tree where each branching node is
split based on the values of a column of Tbl.
tree = fitrtree(___,Name,Value)
Examples
Construct Regression Tree
Load the sample data.
load carsmallConstruct a regression tree using the sample data. The response variable is miles per gallon, MPG.
tree = fitrtree([Weight, Cylinders],MPG,... 'CategoricalPredictors',2,'MinParentSize',20,... 'PredictorNames',{'W','C'})
tree =
RegressionTree
PredictorNames: {'W' 'C'}
ResponseName: 'Y'
CategoricalPredictors: 2
ResponseTransform: 'none'
NumObservations: 94
Predict the mileage of 4,000-pound cars with 4, 6, and 8 cylinders.
MPG4Kpred = predict(tree,[4000 4; 4000 6; 4000 8])
MPG4Kpred = 3×1
19.2778
19.2778
14.3889
Control Regression Tree Depth
fitrtree grows deep decision trees by default. You can grow shallower trees to reduce model complexity or computation time. To control the depth of trees, use the 'MaxNumSplits', 'MinLeafSize', or 'MinParentSize' name-value pair arguments.
Load the carsmall data set. Consider Displacement, Horsepower, and Weight as predictors of the response MPG.
load carsmall
X = [Displacement Horsepower Weight];The default values of the tree-depth controllers for growing regression trees are:
n - 1forMaxNumSplits.nis the training sample size.1forMinLeafSize.10forMinParentSize.
These default values tend to grow deep trees for large training sample sizes.
Train a regression tree using the default values for tree-depth control. Cross-validate the model using 10-fold cross-validation.
rng(1); % For reproducibility MdlDefault = fitrtree(X,MPG,'CrossVal','on');
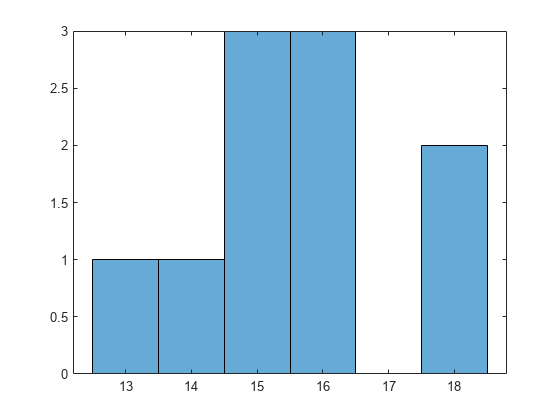
Draw a histogram of the number of imposed splits on the trees. The number of imposed splits is one less than the number of leaves. Also, view one of the trees.
numBranches = @(x)sum(x.IsBranch); mdlDefaultNumSplits = cellfun(numBranches, MdlDefault.Trained); figure; histogram(mdlDefaultNumSplits)
view(MdlDefault.Trained{1},'Mode','graph')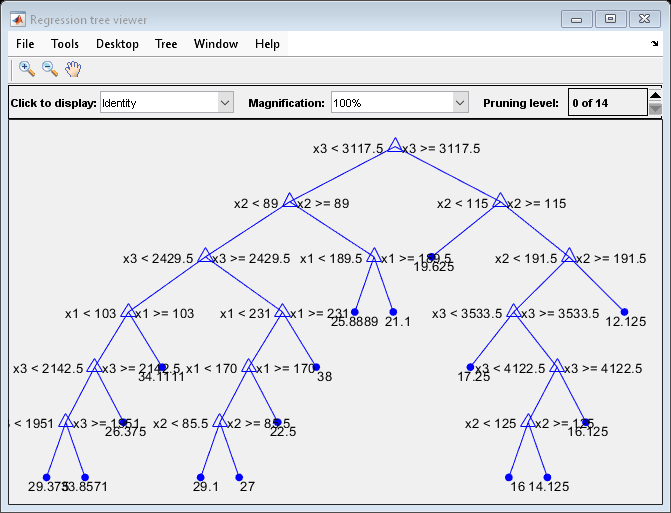
The average number of splits is between 14 and 15.
Suppose that you want a regression tree that is not as complex (deep) as the ones trained using the default number of splits. Train another regression tree, but set the maximum number of splits at 7, which is about half the mean number of splits from the default regression tree. Cross-validate the model using 10-fold cross-validation.
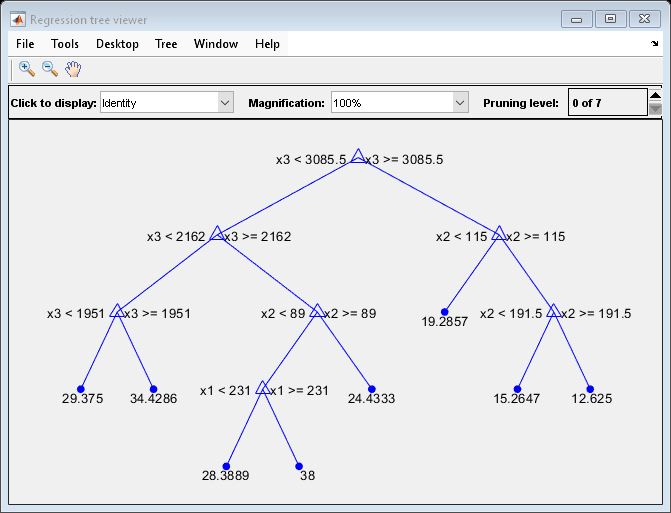
Mdl7 = fitrtree(X,MPG,'MaxNumSplits',7,'CrossVal','on'); view(Mdl7.Trained{1},'Mode','graph')
Compare the cross-validation mean squared errors (MSEs) of the models.
mseDefault = kfoldLoss(MdlDefault)
mseDefault = 25.7383
mse7 = kfoldLoss(Mdl7)
mse7 = 26.5748
Mdl7 is much less complex and performs only slightly worse than MdlDefault.
Optimize Regression Tree
Optimize hyperparameters automatically using fitrtree.
Load the carsmall data set.
load carsmallUse Weight and Horsepower as predictors for MPG. Find hyperparameters that minimize five-fold cross-validation loss by using automatic hyperparameter optimization.
For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
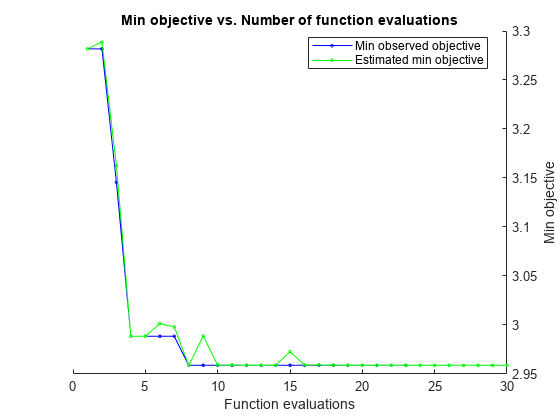
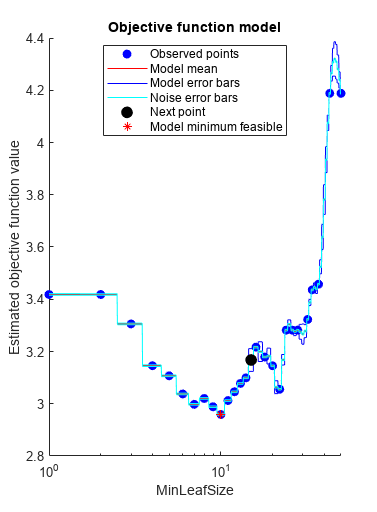
X = [Weight,Horsepower]; Y = MPG; rng default Mdl = fitrtree(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName',... 'expected-improvement-plus'))
|======================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | |
|======================================================================================|
| 1 | Best | 3.2818 | 0.17856 | 3.2818 | 3.2818 | 28 |
| 2 | Accept | 3.4183 | 0.10154 | 3.2818 | 3.2888 | 1 |
| 3 | Best | 3.1457 | 0.05041 | 3.1457 | 3.1628 | 4 |
| 4 | Best | 2.9885 | 0.060213 | 2.9885 | 2.9885 | 9 |
| 5 | Accept | 2.9978 | 0.081682 | 2.9885 | 2.9885 | 7 |
| 6 | Accept | 3.0203 | 0.045349 | 2.9885 | 3.0013 | 8 |
| 7 | Accept | 2.9885 | 0.071842 | 2.9885 | 2.9981 | 9 |
| 8 | Best | 2.9589 | 0.05939 | 2.9589 | 2.9589 | 10 |
| 9 | Accept | 3.078 | 0.036471 | 2.9589 | 2.9888 | 13 |
| 10 | Accept | 4.1881 | 0.045413 | 2.9589 | 2.9592 | 50 |
| 11 | Accept | 3.4182 | 0.084952 | 2.9589 | 2.9592 | 2 |
| 12 | Accept | 3.0376 | 0.038532 | 2.9589 | 2.9591 | 6 |
| 13 | Accept | 3.1453 | 0.039329 | 2.9589 | 2.9591 | 20 |
| 14 | Accept | 2.9589 | 0.048311 | 2.9589 | 2.959 | 10 |
| 15 | Accept | 3.0123 | 0.035575 | 2.9589 | 2.9728 | 11 |
| 16 | Accept | 2.9589 | 0.039667 | 2.9589 | 2.9593 | 10 |
| 17 | Accept | 3.3055 | 0.048941 | 2.9589 | 2.9593 | 3 |
| 18 | Accept | 2.9589 | 0.082784 | 2.9589 | 2.9592 | 10 |
| 19 | Accept | 3.4577 | 0.0753 | 2.9589 | 2.9591 | 37 |
| 20 | Accept | 3.2166 | 0.035505 | 2.9589 | 2.959 | 16 |
|======================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | |
|======================================================================================|
| 21 | Accept | 3.107 | 0.043718 | 2.9589 | 2.9591 | 5 |
| 22 | Accept | 3.2818 | 0.038819 | 2.9589 | 2.959 | 24 |
| 23 | Accept | 3.3226 | 0.029256 | 2.9589 | 2.959 | 32 |
| 24 | Accept | 4.1881 | 0.10829 | 2.9589 | 2.9589 | 43 |
| 25 | Accept | 3.1789 | 0.031267 | 2.9589 | 2.9589 | 18 |
| 26 | Accept | 3.0992 | 0.043228 | 2.9589 | 2.9589 | 14 |
| 27 | Accept | 3.0556 | 0.045482 | 2.9589 | 2.9589 | 22 |
| 28 | Accept | 3.0459 | 0.038532 | 2.9589 | 2.9589 | 12 |
| 29 | Accept | 3.2818 | 0.078529 | 2.9589 | 2.9589 | 26 |
| 30 | Accept | 3.4361 | 0.035617 | 2.9589 | 2.9589 | 34 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 21.1606 seconds
Total objective function evaluation time: 1.7525
Best observed feasible point:
MinLeafSize
___________
10
Observed objective function value = 2.9589
Estimated objective function value = 2.9589
Function evaluation time = 0.05939
Best estimated feasible point (according to models):
MinLeafSize
___________
10
Estimated objective function value = 2.9589
Estimated function evaluation time = 0.052838
Mdl =
RegressionTree
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
Unbiased Predictor Importance Estimates
Load the carsmall data set. Consider a model that predicts the mean fuel economy of a car given its acceleration, number of cylinders, engine displacement, horsepower, manufacturer, model year, and weight. Consider Cylinders, Mfg, and Model_Year as categorical variables.
load carsmall Cylinders = categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg, ... Model_Year,Weight,MPG);
Display the number of categories represented in the categorical variables.
numCylinders = numel(categories(Cylinders))
numCylinders = 3
numMfg = numel(categories(Mfg))
numMfg = 28
numModelYear = numel(categories(Model_Year))
numModelYear = 3
Because there are 3 categories only in Cylinders and Model_Year, the standard CART, predictor-splitting algorithm prefers splitting a continuous predictor over these two variables.
Train a regression tree using the entire data set. To grow unbiased trees, specify usage of the curvature test for splitting predictors. Because there are missing values in the data, specify usage of surrogate splits.
Mdl = fitrtree(X,"MPG",PredictorSelection="curvature",Surrogate="on");
Estimate predictor importance values by summing changes in the risk due to splits on every predictor and dividing the sum by the number of branch nodes. Compare the estimates using a bar graph.
imp = predictorImportance(Mdl); figure bar(imp) title("Predictor Importance Estimates") ylabel("Estimates") xlabel("Predictors") h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = "none";
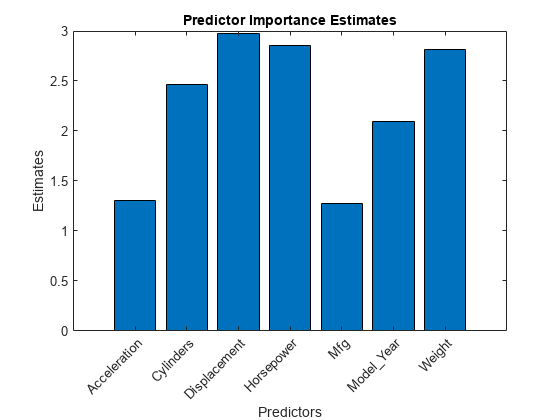
In this case, Displacement is the most important predictor, followed by Horsepower.
Control Maximum Tree Depth on Tall Array
fitrtree grows deep decision trees by default. Build a shallower tree that requires fewer passes through a tall array. Use the 'MaxDepth' name-value pair argument to control the maximum tree depth.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. If you want to run the example using the local MATLAB session when you have Parallel Computing Toolbox, you can change the global execution environment by using the mapreducer function.
Load the carsmall data set. Consider Displacement, Horsepower, and Weight as predictors of the response MPG.
load carsmall
X = [Displacement Horsepower Weight];Convert the in-memory arrays X and MPG to tall arrays.
tx = tall(X);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
ty = tall(MPG);
Grow a regression tree using all observations. Allow the tree to grow to the maximum possible depth.
For reproducibility, set the seeds of the random number generators using rng and tallrng. The results can vary depending on the number of workers and the execution environment for the tall arrays. For details, see Control Where Your Code Runs.
rng('default') tallrng('default') Mdl = fitrtree(tx,ty);
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 2: Completed in 4.1 sec - Pass 2 of 2: Completed in 0.71 sec Evaluation completed in 6.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 1.4 sec - Pass 2 of 7: Completed in 0.29 sec - Pass 3 of 7: Completed in 1.5 sec - Pass 4 of 7: Completed in 3.3 sec - Pass 5 of 7: Completed in 0.63 sec - Pass 6 of 7: Completed in 1.2 sec - Pass 7 of 7: Completed in 2.6 sec Evaluation completed in 12 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.36 sec - Pass 2 of 7: Completed in 0.27 sec - Pass 3 of 7: Completed in 0.85 sec - Pass 4 of 7: Completed in 2 sec - Pass 5 of 7: Completed in 0.55 sec - Pass 6 of 7: Completed in 0.92 sec - Pass 7 of 7: Completed in 1.6 sec Evaluation completed in 7.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.32 sec - Pass 2 of 7: Completed in 0.29 sec - Pass 3 of 7: Completed in 0.89 sec - Pass 4 of 7: Completed in 1.9 sec - Pass 5 of 7: Completed in 0.83 sec - Pass 6 of 7: Completed in 1.2 sec - Pass 7 of 7: Completed in 2.4 sec Evaluation completed in 9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.33 sec - Pass 2 of 7: Completed in 0.28 sec - Pass 3 of 7: Completed in 0.89 sec - Pass 4 of 7: Completed in 2.4 sec - Pass 5 of 7: Completed in 0.76 sec - Pass 6 of 7: Completed in 1 sec - Pass 7 of 7: Completed in 1.7 sec Evaluation completed in 8.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.34 sec - Pass 2 of 7: Completed in 0.26 sec - Pass 3 of 7: Completed in 0.81 sec - Pass 4 of 7: Completed in 1.7 sec - Pass 5 of 7: Completed in 0.56 sec - Pass 6 of 7: Completed in 1 sec - Pass 7 of 7: Completed in 1.9 sec Evaluation completed in 7.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.35 sec - Pass 2 of 7: Completed in 0.28 sec - Pass 3 of 7: Completed in 0.81 sec - Pass 4 of 7: Completed in 1.8 sec - Pass 5 of 7: Completed in 0.76 sec - Pass 6 of 7: Completed in 0.96 sec - Pass 7 of 7: Completed in 2.2 sec Evaluation completed in 8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.35 sec - Pass 2 of 7: Completed in 0.32 sec - Pass 3 of 7: Completed in 0.92 sec - Pass 4 of 7: Completed in 1.9 sec - Pass 5 of 7: Completed in 1 sec - Pass 6 of 7: Completed in 1.5 sec - Pass 7 of 7: Completed in 2.1 sec Evaluation completed in 9.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.33 sec - Pass 2 of 7: Completed in 0.28 sec - Pass 3 of 7: Completed in 0.82 sec - Pass 4 of 7: Completed in 1.4 sec - Pass 5 of 7: Completed in 0.61 sec - Pass 6 of 7: Completed in 0.93 sec - Pass 7 of 7: Completed in 1.5 sec Evaluation completed in 6.6 sec
View the trained tree Mdl.
view(Mdl,'Mode','graph')
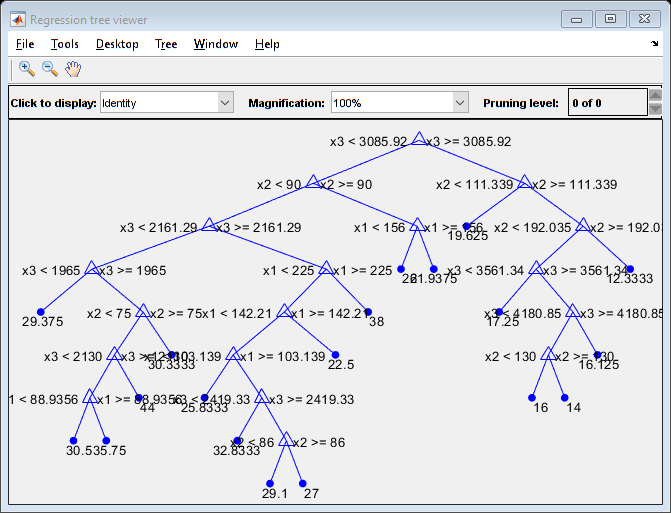
Mdl is a tree of depth 8.
Estimate the in-sample mean squared error.
MSE_Mdl = gather(loss(Mdl,tx,ty))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.6 sec Evaluation completed in 1.9 sec
MSE_Mdl = 4.9078
Grow a regression tree using all observations. Limit the tree depth by specifying a maximum tree depth of 4.
Mdl2 = fitrtree(tx,ty,'MaxDepth',4);Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 2: Completed in 0.27 sec - Pass 2 of 2: Completed in 0.28 sec Evaluation completed in 0.84 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.36 sec - Pass 2 of 7: Completed in 0.3 sec - Pass 3 of 7: Completed in 0.95 sec - Pass 4 of 7: Completed in 1.6 sec - Pass 5 of 7: Completed in 0.55 sec - Pass 6 of 7: Completed in 0.93 sec - Pass 7 of 7: Completed in 1.5 sec Evaluation completed in 7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.34 sec - Pass 2 of 7: Completed in 0.3 sec - Pass 3 of 7: Completed in 0.95 sec - Pass 4 of 7: Completed in 1.7 sec - Pass 5 of 7: Completed in 0.57 sec - Pass 6 of 7: Completed in 0.94 sec - Pass 7 of 7: Completed in 1.8 sec Evaluation completed in 7.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.34 sec - Pass 2 of 7: Completed in 0.3 sec - Pass 3 of 7: Completed in 0.87 sec - Pass 4 of 7: Completed in 1.5 sec - Pass 5 of 7: Completed in 0.57 sec - Pass 6 of 7: Completed in 0.81 sec - Pass 7 of 7: Completed in 1.7 sec Evaluation completed in 6.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.32 sec - Pass 2 of 7: Completed in 0.27 sec - Pass 3 of 7: Completed in 0.85 sec - Pass 4 of 7: Completed in 1.6 sec - Pass 5 of 7: Completed in 0.63 sec - Pass 6 of 7: Completed in 0.9 sec - Pass 7 of 7: Completed in 1.6 sec Evaluation completed in 7 sec
View the trained tree Mdl2.
view(Mdl2,'Mode','graph')
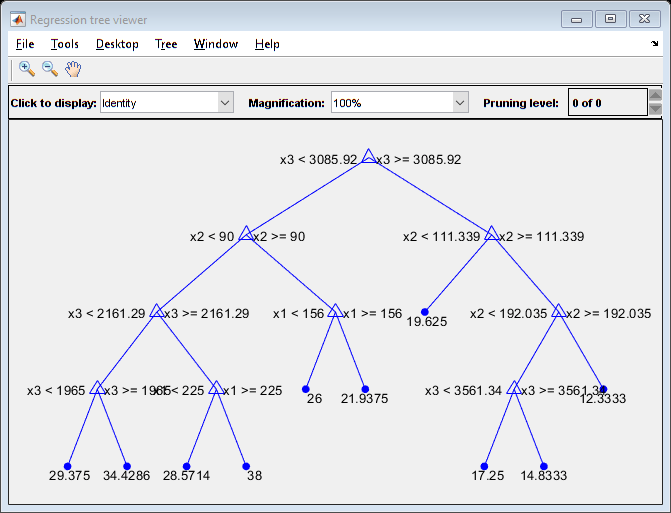
Estimate the in-sample mean squared error.
MSE_Mdl2 = gather(loss(Mdl2,tx,ty))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.73 sec Evaluation completed in 1 sec
MSE_Mdl2 = 9.3903
Mdl2 is a less complex tree with a depth of 4 and an in-sample mean squared error that is higher than the mean squared error of Mdl.
Optimize Regression Tree on Tall Array
Optimize hyperparameters of a regression tree automatically using a tall array. The sample data set is the carsmall data set. This example converts the data set to a tall array and uses it to run the optimization procedure.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. If you want to run the example using the local MATLAB session when you have Parallel Computing Toolbox, you can change the global execution environment by using the mapreducer function.
Load the carsmall data set. Consider Displacement, Horsepower, and Weight as predictors of the response MPG.
load carsmall
X = [Displacement Horsepower Weight];Convert the in-memory arrays X and MPG to tall arrays.
tx = tall(X);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
ty = tall(MPG);
Optimize hyperparameters automatically using the 'OptimizeHyperparameters' name-value pair argument. Find the optimal 'MinLeafSize' value that minimizes holdout cross-validation loss. (Specifying 'auto' uses 'MinLeafSize'.) For reproducibility, use the 'expected-improvement-plus' acquisition function and set the seeds of the random number generators using rng and tallrng. The results can vary depending on the number of workers and the execution environment for the tall arrays. For details, see Control Where Your Code Runs.
rng('default') tallrng('default') [Mdl,FitInfo,HyperparameterOptimizationResults] = fitrtree(tx,ty,... 'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('Holdout',0.3,... 'AcquisitionFunctionName','expected-improvement-plus'))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 4.4 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.97 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 3.6 sec - Pass 4 of 4: Completed in 2.4 sec Evaluation completed in 9.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 2.7 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 3 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 8.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 2.6 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.4 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.4 sec Evaluation completed in 1.7 sec |======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 1 | Best | 3.2007 | 69.013 | 3.2007 | 3.2007 | 2 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.52 sec Evaluation completed in 0.83 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 3 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 8.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.79 sec Evaluation completed in 1 sec | 2 | Error | NaN | 13.772 | NaN | 3.2007 | 46 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.52 sec Evaluation completed in 0.81 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 2.2 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.7 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 6.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.72 sec Evaluation completed in 0.99 sec | 3 | Best | 3.1876 | 29.091 | 3.1876 | 3.1884 | 18 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.48 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.92 sec | 4 | Best | 2.9048 | 33.465 | 2.9048 | 2.9537 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.71 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.66 sec Evaluation completed in 0.92 sec | 5 | Accept | 3.2895 | 25.902 | 2.9048 | 2.9048 | 15 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.54 sec Evaluation completed in 0.82 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 6.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.68 sec Evaluation completed in 0.99 sec | 6 | Accept | 3.1641 | 35.522 | 2.9048 | 3.1493 | 5 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.51 sec Evaluation completed in 0.79 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.67 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.89 sec | 7 | Accept | 2.9048 | 33.755 | 2.9048 | 2.9048 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.45 sec Evaluation completed in 0.75 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.68 sec Evaluation completed in 0.97 sec | 8 | Accept | 2.9522 | 33.362 | 2.9048 | 2.9048 | 7 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.42 sec Evaluation completed in 0.71 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.9 sec | 9 | Accept | 2.9985 | 32.674 | 2.9048 | 2.9048 | 8 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.88 sec Evaluation completed in 1.2 sec | 10 | Accept | 3.0185 | 33.922 | 2.9048 | 2.9048 | 10 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.74 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.73 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.88 sec | 11 | Accept | 3.2895 | 26.625 | 2.9048 | 2.9048 | 14 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.48 sec Evaluation completed in 0.78 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.65 sec Evaluation completed in 0.9 sec | 12 | Accept | 3.4798 | 18.111 | 2.9048 | 2.9049 | 31 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.71 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.91 sec | 13 | Accept | 3.2248 | 47.436 | 2.9048 | 2.9048 | 1 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.74 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2.6 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.62 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.61 sec Evaluation completed in 0.88 sec | 14 | Accept | 3.1498 | 42.062 | 2.9048 | 2.9048 | 3 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.67 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 2.3 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 7.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.6 sec Evaluation completed in 0.86 sec | 15 | Accept | 2.9048 | 34.3 | 2.9048 | 2.9048 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.48 sec Evaluation completed in 0.78 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.88 sec | 16 | Accept | 2.9048 | 32.97 | 2.9048 | 2.9048 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.9 sec | 17 | Accept | 3.1847 | 17.47 | 2.9048 | 2.9048 | 23 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.72 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.68 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.93 sec | 18 | Accept | 3.1817 | 33.346 | 2.9048 | 2.9048 | 4 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.72 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.86 sec | 19 | Error | NaN | 10.235 | 2.9048 | 2.9048 | 38 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.47 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.89 sec | 20 | Accept | 3.0628 | 32.459 | 2.9048 | 2.9048 | 12 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.68 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.9 sec |======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 21 | Accept | 3.1847 | 19.02 | 2.9048 | 2.9048 | 27 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.45 sec Evaluation completed in 0.75 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 2.4 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.89 sec | 22 | Accept | 3.0185 | 33.933 | 2.9048 | 2.9048 | 9 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.89 sec | 23 | Accept | 3.0749 | 25.147 | 2.9048 | 2.9048 | 20 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.42 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.88 sec | 24 | Accept | 3.0628 | 32.764 | 2.9048 | 2.9048 | 11 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.61 sec Evaluation completed in 0.87 sec | 25 | Error | NaN | 10.294 | 2.9048 | 2.9048 | 34 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.87 sec | 26 | Accept | 3.1847 | 17.587 | 2.9048 | 2.9048 | 25 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.45 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.66 sec Evaluation completed in 0.96 sec | 27 | Accept | 3.2895 | 24.867 | 2.9048 | 2.9048 | 16 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.74 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.6 sec Evaluation completed in 0.88 sec | 28 | Accept | 3.2135 | 24.928 | 2.9048 | 2.9048 | 13 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.47 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.87 sec | 29 | Accept | 3.1847 | 17.582 | 2.9048 | 2.9048 | 21 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.53 sec Evaluation completed in 0.81 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.88 sec | 30 | Accept | 3.1827 | 17.597 | 2.9048 | 2.9122 | 29 |
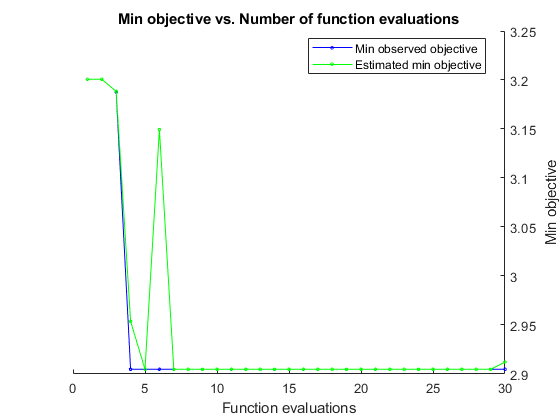
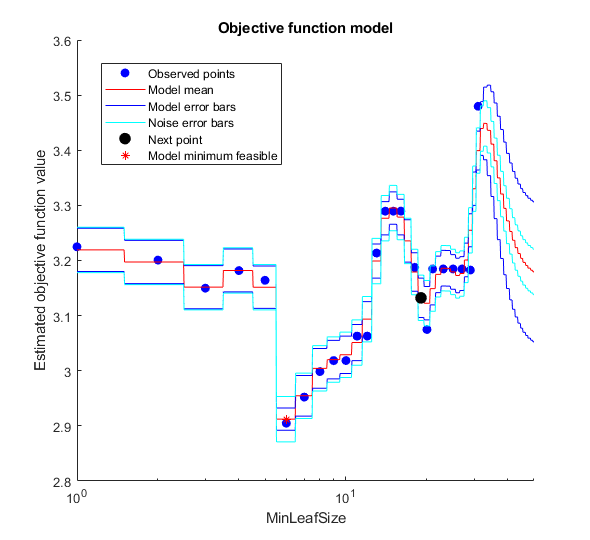
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 882.5668 seconds.
Total objective function evaluation time: 859.2122
Best observed feasible point:
MinLeafSize
___________
6
Observed objective function value = 2.9048
Estimated objective function value = 2.9122
Function evaluation time = 33.4655
Best estimated feasible point (according to models):
MinLeafSize
___________
6
Estimated objective function value = 2.9122
Estimated function evaluation time = 33.6594
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 2: Completed in 0.26 sec
- Pass 2 of 2: Completed in 0.26 sec
Evaluation completed in 0.84 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.31 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.75 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.45 sec
- Pass 6 of 7: Completed in 0.69 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.7 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.28 sec
- Pass 2 of 7: Completed in 0.24 sec
- Pass 3 of 7: Completed in 0.75 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.46 sec
- Pass 6 of 7: Completed in 0.67 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.6 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.32 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.71 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.47 sec
- Pass 6 of 7: Completed in 0.66 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.6 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.29 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.73 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.46 sec
- Pass 6 of 7: Completed in 0.68 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.5 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.27 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.75 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.47 sec
- Pass 6 of 7: Completed in 0.69 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.6 sec
Mdl =
CompactRegressionTree
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
Properties, Methods
FitInfo = struct with no fields.
HyperparameterOptimizationResults =
BayesianOptimization with properties:
ObjectiveFcn: @createObjFcn/tallObjFcn
VariableDescriptions: [3×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 2.9048
XAtMinObjective: [1×1 table]
MinEstimatedObjective: 2.9122
XAtMinEstimatedObjective: [1×1 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 882.5668
NextPoint: [1×1 table]
XTrace: [30×1 table]
ObjectiveTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
Input Arguments
Output Arguments
More About
Tips
By default,
Pruneis'on'. However, this specification does not prune the regression tree. To prune a trained regression tree, pass the regression tree toprune.After training a model, you can generate C/C++ code that predicts responses for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation.
Algorithms
References
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
[2] Loh, W.Y. “Regression Trees with Unbiased Variable Selection and Interaction Detection.” Statistica Sinica, Vol. 12, 2002, pp. 361–386.
[3] Loh, W.Y. and Y.S. Shih. “Split Selection Methods for Classification Trees.” Statistica Sinica, Vol. 7, 1997, pp. 815–840.
Extended Capabilities
Version History
Introduced in R2014a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)