resubPredict
Predict response of regression tree by resubstitution
Syntax
Description
Examples
Compute the In-Sample MSE
Load the carsmall data set. Consider Displacement, Horsepower, and Weight as predictors of the response MPG.
load carsmall
X = [Displacement Horsepower Weight];Grow a regression tree using all observations.
Mdl = fitrtree(X,MPG);
Compute the resubstitution MSE.
Yfit = resubPredict(Mdl); mean((Yfit - Mdl.Y).^2)
ans = 4.8952
You can get the same result using resubLoss.
resubLoss(Mdl)
ans = 4.8952
Estimate In-Sample Responses for Each Subtree
Load the carsmall data set. Consider Weight as a predictor of the response MPG.
load carsmall
idxNaN = isnan(MPG + Weight);
X = Weight(~idxNaN);
Y = MPG(~idxNaN);
n = numel(X);Grow a regression tree using all observations.
Mdl = fitrtree(X,Y);
Compute resubstitution fitted values for the subtrees at several pruning levels.
m = max(Mdl.PruneList);
pruneLevels = 1:4:m; % Pruning levels to consider
z = numel(pruneLevels);
Yfit = resubPredict(Mdl,Subtrees=pruneLevels);Yfit is an n-by-z matrix of fitted values in which the rows correspond to observations and the columns correspond to a subtree.
Plot several columns of Yfit and Y against X.
sortDat = sortrows([X Y Yfit],1); % Sort all data with respect to X plot(repmat(sortDat(:,1),1,size(Yfit,2)+1),sortDat(:,2:end)) % Vectorize for efficiency lev = num2str((pruneLevels)',"Level %d MPG"); legend(["Observed MPG"; lev]) title("In-Sample Fitted Responses") xlabel("Weight (lbs)") ylabel("MPG") h = findobj(gcf); set(h(4:end),LineWidth=3) % Widen all lines
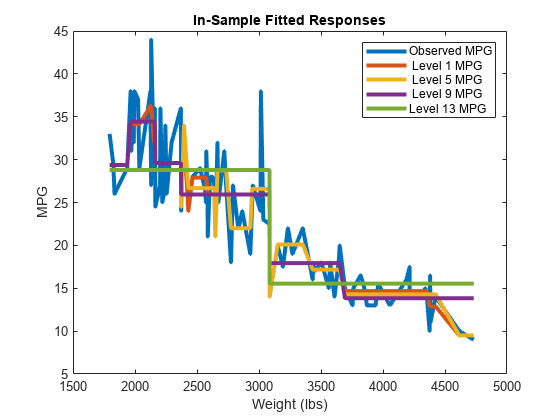
The values of Yfit for lower pruning levels tend to follow the data more closely than higher levels. Higher pruning levels tend to be flat for large X intervals.
Input Arguments
Output Arguments
Extended Capabilities
Version History
Introduced in R2011a
See Also
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)