Code Generation for Semantic Segmentation Network
This example shows code generation for an image segmentation application that uses deep learning. It uses the codegen command to generate a MEX function that performs prediction on a DAG Network object for SegNet [1], a deep learning network for image segmentation.
Third-Party Prerequisites
Required
This example generates CUDA MEX and has the following third-party requirements.
CUDA® enabled NVIDIA® GPU and compatible driver.
Optional
For non-MEX builds such as static, dynamic libraries or executables, this example has the following additional requirements.
NVIDIA toolkit.
NVIDIA cuDNN library.
Environment variables for the compilers and libraries. For more information, see Third-Party Hardware and Setting Up the Prerequisite Products.
Verify GPU Environment
Use the coder.checkGpuInstall function to verify that the compilers and libraries necessary for running this example are set up correctly.
envCfg = coder.gpuEnvConfig('host'); envCfg.DeepLibTarget = 'cudnn'; envCfg.DeepCodegen = 1; envCfg.Quiet = 1; coder.checkGpuInstall(envCfg);
Segmentation Network
SegNet [1] is a type of convolutional neural network (CNN) designed for semantic image segmentation. It is a deep encoder-decoder multi-class pixel-wise segmentation network trained on the CamVid [2] dataset and imported into MATLAB® for inference. The SegNet [1] is trained to segment pixels belonging to 11 classes that include Sky, Building, Pole, Road, Pavement, Tree, SignSymbol, Fence, Car, Pedestrian, and Bicyclist.
For information regarding training a semantic segmentation network in MATLAB by using the CamVid [2] dataset, see Semantic Segmentation Using Deep Learning (Computer Vision Toolbox).
The segnet_predict Entry-Point Function
The segnet_predict.m entry-point function takes an image input and performs prediction on the image by using the deep learning network saved in the SegNet.mat file. The function loads the network object from the SegNet.mat file into a persistent variable mynet and reuses the persistent variable on subsequent prediction calls.
type('segnet_predict.m')function out = segnet_predict(in)
%#codegen
% Copyright 2018-2021 The MathWorks, Inc.
persistent mynet;
if isempty(mynet)
mynet = coder.loadDeepLearningNetwork('SegNet.mat');
end
% pass in input
out = predict(mynet,in);
Get Pretrained SegNet DAG Network Object
net = getSegNet();
Downloading pretrained SegNet (107 MB)...
The DAG network contains 91 layers including convolution, batch normalization, pooling, unpooling, and the pixel classification output layers. Use the analyzeNetwork (Deep Learning Toolbox) function to display an interactive visualization of the deep learning network architecture.
analyzeNetwork(net);
Run MEX Code Generation
To generate CUDA code for the segnet_predict.m entry-point function, create a GPU code configuration object for a MEX target and set the target language to C++. Use the coder.DeepLearningConfig function to create a CuDNN deep learning configuration object and assign it to the DeepLearningConfig property of the GPU code configuration object. Run the codegen command specifying an input size of [360,480,3]. This value corresponds to the input layer size of SegNet.
cfg = coder.gpuConfig('mex'); cfg.TargetLang = 'C++'; cfg.DeepLearningConfig = coder.DeepLearningConfig('cudnn'); codegen -config cfg segnet_predict -args {ones(360,480,3,'uint8')} -report
Code generation successful: View report
Run Generated MEX
Load and display an input image.
im = imread('gpucoder_segnet_image.png');
imshow(im);
Call segnet_predict_mex on the input image.
predict_scores = segnet_predict_mex(im);
The predict_scores variable is a three-dimensional matrix that has 11 channels corresponding to the pixel-wise prediction scores for every class. Compute the channel by using the maximum prediction score to get pixel-wise labels.
[~,argmax] = max(predict_scores,[],3);
Overlay the segmented labels on the input image and display the segmented region.
classes = [
"Sky"
"Building"
"Pole"
"Road"
"Pavement"
"Tree"
"SignSymbol"
"Fence"
"Car"
"Pedestrian"
"Bicyclist"
];
cmap = camvidColorMap();
SegmentedImage = labeloverlay(im,argmax,'ColorMap',cmap);
figure
imshow(SegmentedImage);
pixelLabelColorbar(cmap,classes);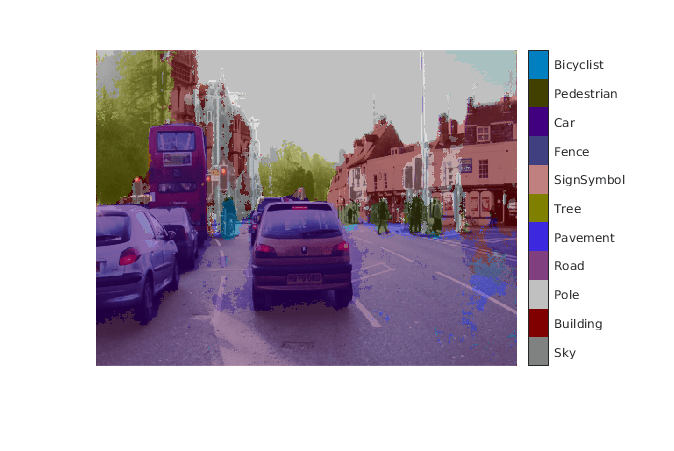
References
[1] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla. "SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." arXiv preprint arXiv:1511.00561, 2015.
[2] Brostow, Gabriel J., Julien Fauqueur, and Roberto Cipolla. "Semantic object classes in video: A high-definition ground truth database." Pattern Recognition Letters Vol 30, Issue 2, 2009, pp 88-97.
See Also
Functions
Objects
Topics
- Semantic Segmentation Using Deep Learning (Computer Vision Toolbox)
- Semantic Segmentation on NVIDIA DRIVE
- Code Generation for Semantic Segmentation Network That Uses U-net
- Get Started with Semantic Segmentation Using Deep Learning (Computer Vision Toolbox)