quantile
Quantiles of data set
Syntax
Description
Q = quantile(A,p)A for the cumulative
probability or probabilities p in the interval [0,1].
If
Ais a vector, thenQis a scalar or a vector with the same length asp.Q(i)contains thep(i)quantile.If
Ais a matrix, thenQis a row vector or a matrix, where the number of rows ofQis equal tolength(p). Theith row ofQcontains thep(i)quantiles of each column ofA.If
Ais a multidimensional array, thenQcontains the quantiles computed along the first array dimension whose size does not equal 1.
Q = quantile(A,n)n evenly spaced cumulative probabilities
(1/(n + 1), 2/(n + 1), ...,
n/(n + 1)) for integer n > 1.
If
Ais a vector, thenQis a scalar or a vector with lengthn.If
Ais a matrix, thenQis a matrix withnrows.If
Ais a multidimensional array, thenQcontains the quantiles computed along the first array dimension whose size does not equal 1.
Q = quantile(___,"all")A for either of the first two
syntaxes.
Q = quantile(___,vecdim)vecdim for either
of the first two syntaxes. For example, if A is a matrix, then
quantile(A,n,[1 2]) operates on all the elements of
A because every element of a matrix is contained in the array slice
defined by dimensions 1 and 2.
Examples
Input Arguments
Output Arguments
More About
T-digest [2] is a probabilistic data structure that is a sparse representation of the empirical cumulative distribution function (CDF) of a data set. T-digest is useful for computing approximations of rank-based statistics (such as percentiles and quantiles) from online or distributed data in a way that allows for controllable accuracy, particularly near the tails of the data distribution.
For data that is distributed in different partitions, t-digest computes quantile estimates (and percentile estimates) for each data partition separately, and then combines the estimates while maintaining a constant-memory bound and constant relative accuracy of computation ( for the qth quantile). For these reasons, t-digest is practical for working with tall arrays.
To estimate quantiles of an array that is distributed in different partitions, first
build a t-digest in each partition of the data. A t-digest clusters the data in the
partition and summarizes each cluster by a centroid value and an accumulated weight that
represents the number of samples contributing to the cluster. T-digest uses large clusters
(widely spaced centroids) to represent areas of the CDF that are near
q = 0.5 and uses small clusters (tightly spaced
centroids) to represent areas of the CDF that are near q =
0 and q = 1.
T-digest controls the cluster size by using a scaling function that maps a quantile q to an index k with a compression parameter δ. That is,
where the mapping k is monotonic with minimum value k(0,δ) = 0 and maximum value k(1,δ) = δ. This figure shows the scaling function for δ = 10.
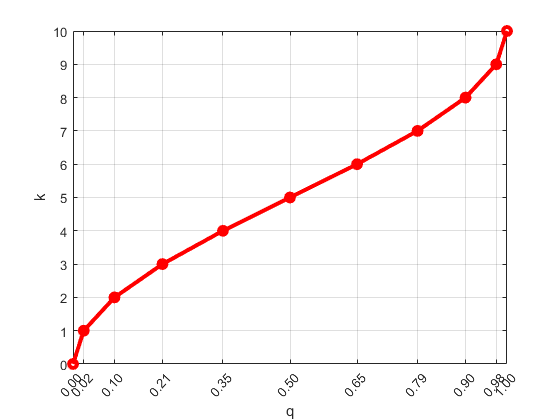
The scaling function translates the quantile q to the scaling factor
k in order to give variable-size steps in q. As a
result, cluster sizes are unequal (larger around the center quantiles and smaller near
q = 0 and q =
1). The smaller clusters allow for better accuracy near the edges of the
data.
To update a t-digest with a new observation that has a weight and location, find the cluster closest to the new observation. Then, add the weight and update the centroid of the cluster based on the weighted average, provided that the updated weight of the cluster does not exceed the size limitation.
You can combine independent t-digests from each partition of the data by taking a union of the t-digests and merging their centroids. To combine t-digests, first sort the clusters from all the independent t-digests in decreasing order of cluster weights. Then, merge neighboring clusters, when they meet the size limitation, to form a new t-digest.
Once you form a t-digest that represents the complete data set, you can estimate the endpoints (or boundaries) of each cluster in the t-digest and then use interpolation between the endpoints of each cluster to find accurate quantile estimates.
Algorithms
For an n-element vector A, the
quantile function computes quantiles by using a sorting-based algorithm
when you choose any method except "approximate".
The sorted elements in
Aare mapped to quantiles based on the method you choose, as described in this table.Quantile Method"midpoint"Before R2025a:
"exact""inclusive"(since R2025a)"exclusive"(since R2025a)Quantile of 1st sorted element 1/(2n) 0 1/(n+1) Quantile of 2nd sorted element 3/(2n) 1/(n−1) 2/(n+1) Quantile of 3rd sorted element 5/(2n) 2/(n−1) 3/(n+1) ... ... ... ... Quantile of kth sorted element (2k−1)/(2n) (k−1)/(n−1) k/(n+1) ... ... ... ... Quantile of (n−1)th sorted element (2n−3)/(2n) (n−2)/(n−1) (n−1)/(n+1) Quantile of nth sorted element (2n−1)/(2n) 1 n/(n+1) For example, if
Ais[6 3 2 10 1], then the quantiles are as shown in this table.Quantile Method"midpoint"Before R2025a:
"exact""inclusive"(since R2025a)"exclusive"(since R2025a)Quantile of 11/10 0 1/6 Quantile of 23/10 1/4 1/3 Quantile of 31/2 1/2 1/2 Quantile of 67/10 3/4 2/3 Quantile of 109/10 1 5/6 The
quantilefunction uses linear interpolation to compute quantiles for probabilities between that of the first and that of the last sorted element ofA. For more information, see Linear Interpolation.For example, if
Ais[6 3 2 10 1], then:For the midpoint method, the 0.4th quantile is
2.5.Before R2025a: For the exact method, the 0.4th quantile is
2.5.For the inclusive method, the 0.4th quantile is
2.6. (since R2025a)For the exclusive method, the 0.4th quantile is
2.4. (since R2025a)
The
quantilefunction assigns the minimum or maximum values of the elements inAto the quantiles corresponding to the probabilities outside of that range.For example, if
Ais[6 3 2 10 1], then, for both the midpoint and exclusive method, the 0.05th quantile is1. (since R2025a)Before R2025a: For example, if
Ais[6 3 2 10 1], then, for the exact method, the 0.05th quantile is1.
The quantile function treats NaN values as missing
values and removes them.
References
[1] Langford, E. “Quartiles in Elementary Statistics”, Journal of Statistics Education. Vol. 14, No. 3, 2006.