capaplot
Process capability plot
Description
Examples
Simulate a sample of 100 measurements from a process with a mean of 3 and a standard deviation of 0.005.
X = normrnd(3,0.005,100,1);
Set a lower specification limit of 2.99 and an upper specification limit of 3.01 for the process, and then compute the capability indices.
specs = [2.99 3.01]; S = capability(X,specs)
S = struct with fields:
mu: 3.0006
sigma: 0.0058
P: 0.9129
Pl: 0.0339
Pu: 0.0532
Cp: 0.5735
Cpl: 0.6088
Cpu: 0.5382
Cpk: 0.5382
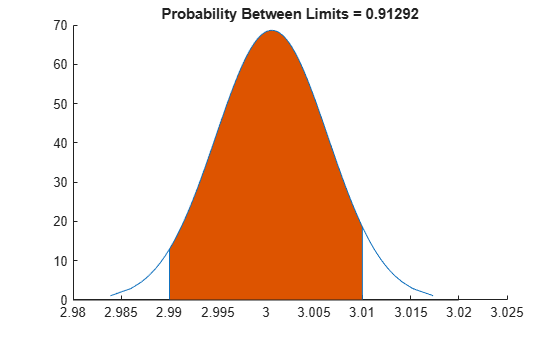
Visualize the specification and process widths.
capaplot(X,specs);
Input Arguments
Output Arguments
References
[1] Montgomery, Douglas C. Statistical Quality Control. 7th ed. Nashville, TN: John Wiley & Sons, 2012.