ClassificationPartitionedECOC
Cross-validated multiclass ECOC model for support vector machines (SVMs) and other classifiers
Description
ClassificationPartitionedECOC is a set of
error-correcting output codes (ECOC) models trained on cross-validated folds. Estimate
the quality of the cross-validated classification by using one or more
“kfold” functions: kfoldPredict, kfoldLoss, kfoldMargin, kfoldEdge, and kfoldfun.
Every “kfold” method uses models trained on training-fold (in-fold) observations to predict the response for validation-fold (out-of-fold) observations. For example, suppose you cross-validate using five folds. In this case, the software randomly assigns each observation into five groups of equal size (roughly). The training fold contains four of the groups (roughly 4/5 of the data), and the validation fold contains the other group (roughly 1/5 of the data). In this case, cross-validation proceeds as follows:
The software trains the first model (stored in
CVMdl.Trained{1}) by using the observations in the last four groups and reserves the observations in the first group for validation.The software trains the second model (stored in
CVMdl.Trained{2}) by using the observations in the first group and the last three groups. The software reserves the observations in the second group for validation.The software proceeds in a similar fashion for the third, fourth, and fifth models.
If you validate by using kfoldPredict, the software computes
predictions for the observations in group i by using the
ith model. In short, the software estimates a response for every
observation by using the model trained without that observation.
Creation
You can create a ClassificationPartitionedECOC model in two
ways:
Properties
Object Functions
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
kfoldEdge | Classification edge for cross-validated ECOC model |
kfoldLoss | Classification loss for cross-validated ECOC model |
kfoldMargin | Classification margins for cross-validated ECOC model |
kfoldPredict | Classify observations in cross-validated ECOC model |
kfoldfun | Cross-validate function using cross-validated ECOC model |
Examples
Cross-validate an ECOC classifier with SVM binary learners, and estimate the generalized classification error.
Load Fisher's iris data set. Specify the predictor data X and the response data Y.
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
Create an SVM template, and standardize the predictors.
t = templateSVM('Standardize',true)t =
Fit template for SVM.
Standardize: 1
t is an SVM template. Most of the template object properties are empty. When training the ECOC classifier, the software sets the applicable properties to their default values.
Train the ECOC classifier, and specify the class order.
Mdl = fitcecoc(X,Y,'Learners',t,... 'ClassNames',{'setosa','versicolor','virginica'});
Mdl is a ClassificationECOC classifier. You can access its properties using dot notation.
Cross-validate Mdl using 10-fold cross-validation.
CVMdl = crossval(Mdl);
CVMdl is a ClassificationPartitionedECOC cross-validated ECOC classifier.
Estimate the generalized classification error.
genError = kfoldLoss(CVMdl)
genError = 0.0400
The generalized classification error is 4%, which indicates that the ECOC classifier generalizes fairly well.
Train a one-versus-all ECOC classifier using a GentleBoost ensemble of decision trees with surrogate splits. To speed up training, bin numeric predictors and use parallel computing. Binning is valid only when fitcecoc uses a tree learner. After training, estimate the classification error using 10-fold cross-validation. Note that parallel computing requires Parallel Computing Toolbox™.
Load Sample Data
Load and inspect the arrhythmia data set.
load arrhythmia
[n,p] = size(X)n = 452
p = 279
isLabels = unique(Y); nLabels = numel(isLabels)
nLabels = 13
tabulate(categorical(Y))
Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
The data set contains 279 predictors, and the sample size of 452 is relatively small. Of the 16 distinct labels, only 13 are represented in the response (Y). Each label describes various degrees of arrhythmia, and 54.20% of the observations are in class 1.
Train One-Versus-All ECOC Classifier
Create an ensemble template. You must specify at least three arguments: a method, a number of learners, and the type of learner. For this example, specify 'GentleBoost' for the method, 100 for the number of learners, and a decision tree template that uses surrogate splits because there are missing observations.
tTree = templateTree('surrogate','on'); tEnsemble = templateEnsemble('GentleBoost',100,tTree);
tEnsemble is a template object. Most of its properties are empty, but the software fills them with their default values during training.
Train a one-versus-all ECOC classifier using the ensembles of decision trees as binary learners. To speed up training, use binning and parallel computing.
Binning (
'NumBins',50) — When you have a large training data set, you can speed up training (a potential decrease in accuracy) by using the'NumBins'name-value pair argument. This argument is valid only whenfitcecocuses a tree learner. If you specify the'NumBins'value, then the software bins every numeric predictor into a specified number of equiprobable bins, and then grows trees on the bin indices instead of the original data. You can try'NumBins',50first, and then change the'NumBins'value depending on the accuracy and training speed.Parallel computing (
'Options',statset('UseParallel',true)) — With a Parallel Computing Toolbox license, you can speed up the computation by using parallel computing, which sends each binary learner to a worker in the pool. The number of workers depends on your system configuration. When you use decision trees for binary learners,fitcecocparallelizes training using Intel® Threading Building Blocks (TBB) for dual-core systems and above. Therefore, specifying the'UseParallel'option is not helpful on a single computer. Use this option on a cluster.
Additionally, specify that the prior probabilities are 1/K, where K = 13 is the number of distinct classes.
options = statset('UseParallel',true); Mdl = fitcecoc(X,Y,'Coding','onevsall','Learners',tEnsemble,... 'Prior','uniform','NumBins',50,'Options',options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Mdl is a ClassificationECOC model.
Cross-Validation
Cross-validate the ECOC classifier using 10-fold cross-validation.
CVMdl = crossval(Mdl,'Options',options);Warning: One or more folds do not contain points from all the groups.
CVMdl is a ClassificationPartitionedECOC model. The warning indicates that some classes are not represented while the software trains at least one fold. Therefore, those folds cannot predict labels for the missing classes. You can inspect the results of a fold using cell indexing and dot notation. For example, access the results of the first fold by entering CVMdl.Trained{1}.
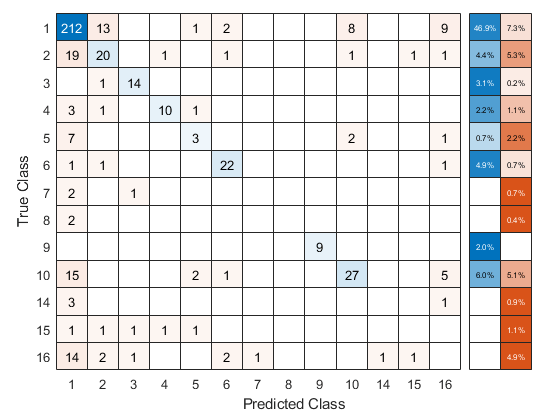
Use the cross-validated ECOC classifier to predict validation-fold labels. You can compute the confusion matrix by using confusionchart. Move and resize the chart by changing the inner position property to ensure that the percentages appear in the row summary.
oofLabel = kfoldPredict(CVMdl,'Options',options); ConfMat = confusionchart(Y,oofLabel,'RowSummary','total-normalized'); ConfMat.InnerPosition = [0.10 0.12 0.85 0.85];
Reproduce Binned Data
Reproduce binned predictor data by using the BinEdges property of the trained model and the discretize function.
X = Mdl.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
Xbinned contains the bin indices, ranging from 1 to the number of bins, for numeric predictors. Xbinned values are 0 for categorical predictors. If X contains NaNs, then the corresponding Xbinned values are NaNs.
Extended Capabilities
Version History
Introduced in R2014bSee Also
cvpartition | crossval | fitcecoc | ClassificationECOC | CompactClassificationECOC