glmfit
Fit generalized linear regression model
Syntax
Description
b = glmfit(X,y,distr,Name,Value)'Constant','off' to omit the constant term from the model.
Examples
Fit Generalized Linear Model with Probit Link
Fit a generalized linear regression model, and compute predicted (estimated) values for the predictor data using the fitted model.
Create a sample data set.
x = [2100 2300 2500 2700 2900 3100 ...
3300 3500 3700 3900 4100 4300]';
n = [48 42 31 34 31 21 23 23 21 16 17 21]';
y = [1 2 0 3 8 8 14 17 19 15 17 21]';x contains the predictor variable values. Each y value is the number of successes in the corresponding number of trials in n.
Fit a probit regression model for y on x.
b = glmfit(x,[y n],'binomial','Link','probit');
Compute the estimated number of successes.
yfit = glmval(b,x,'probit','Size',n);
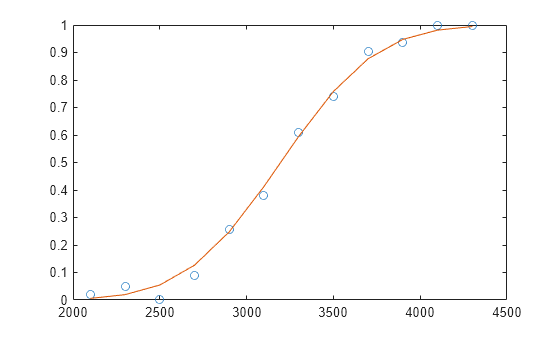
Plot the observed success percent and estimated success percent versus the x values.
plot(x,y./n,'o',x,yfit./n,'-')
Fit Generalized Linear Model Using Custom Link Function
Define a custom link function and use it to fit a generalized linear regression model.
Load the sample data.
load fisheririsThe column vector species contains iris flowers of three different species: setosa, versicolor, and virginica. The matrix meas contains four types of measurements for the flowers, the length and width of sepals and petals in centimeters.
Define the predictor variables and response variable.
X = meas(51:end,:);
y = strcmp('versicolor',species(51:end));Define a custom link function for a logit link function. Create three function handles that define the link function, the derivative of the link function, and the inverse link function. Store them in a cell array.
link = @(mu) log(mu./(1-mu));
derlink = @(mu) 1./(mu.*(1-mu));
invlink = @(resp) 1./(1+exp(-resp));
F = {link,derlink,invlink};Fit a logistic regression model using glmfit with the custom link function.
b = glmfit(X,y,'binomial','link',F)
b = 5×1
42.6378
2.4652
6.6809
-9.4294
-18.2861
Fit a generalized linear model by using the built-in logit link function, and compare the results.
b = glmfit(X,y,'binomial','link','logit')
b = 5×1
42.6378
2.4652
6.6809
-9.4294
-18.2861
Perform Deviance Test
Fit a generalized linear regression model that contains an intercept and linear term for each predictor. Perform a deviance test that determines whether the model fits significantly better than a constant model.
Generate sample data using Poisson random numbers with two underlying predictors X(:,1) and X(:,2).
rng('default') % For reproducibility rndvars = randn(100,2); X = [2 + rndvars(:,1),rndvars(:,2)]; mu = exp(1 + X*[1;2]); y = poissrnd(mu);
Fit a generalized linear regression model that contains an intercept and linear term for each predictor.
[b,dev] = glmfit(X,y,'poisson');The second output argument dev is a Deviance of the fit.
Fit a generalized linear regression model that contains only an intercept. Specify the predictor variable as a column of 1s, and specify 'Constant' as 'off' so that glmfit does not include a constant term in the model.
[~,dev_noconstant] = glmfit(ones(100,1),y,'poisson','Constant','off');
Compute the difference between dev_constant and dev.
D = dev_noconstant - dev
D = 2.9533e+05
D has a chi-square distribution with 2 degrees of freedom. The degrees of freedom equal the difference in the number of estimated parameters in the model corresponding to dev and the number of estimated parameters in the constant model. Find the p-value for a deviance test.
p = 1 - chi2cdf(D,2)
p = 0
The small p-value indicates that the model differs significantly from a constant.
Alternatively, you can create a generalized linear regression model of Poisson data by using the fitglm function. The model display includes the statistic (Chi^2-statistic vs. constant model) and p-value.
mdl = fitglm(X,y,'y ~ x1 + x2','Distribution','poisson')
mdl =
Generalized linear regression model:
log(y) ~ 1 + x1 + x2
Distribution = Poisson
Estimated Coefficients:
Estimate SE tStat pValue
________ _________ ______ ______
(Intercept) 1.0405 0.022122 47.034 0
x1 0.9968 0.003362 296.49 0
x2 1.987 0.0063433 313.24 0
100 observations, 97 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 2.95e+05, p-value = 0
You can also use the devianceTest function with the fitted model object.
devianceTest(mdl)
ans=2×4 table
Deviance DFE chi2Stat pValue
__________ ___ __________ ______
log(y) ~ 1 2.9544e+05 99
log(y) ~ 1 + x1 + x2 107.4 97 2.9533e+05 0
Input Arguments
Output Arguments
More About
Alternative Functionality
glmfit is useful when you simply need the output arguments of the
function or when you want to repeat fitting a model multiple times in a loop. If you need to
investigate a fitted model further, create a generalized linear regression model object GeneralizedLinearModel by using fitglm or stepwiseglm. A
GeneralizedLinearModel object provides more features than
glmfit.
Use the properties of
GeneralizedLinearModelto investigate a fitted model. The object properties include information about the coefficient estimates, summary statistics, fitting method, and input data.Use the object functions of
GeneralizedLinearModelto predict responses and to modify, evaluate, and visualize the generalized linear regression model.You can find the information in the output of
glmfitusing the properties and object functions ofGeneralizedLinearModel.Output of glmfitEquivalent Values in GeneralizedLinearModelbSee the Estimatecolumn of theCoefficientsproperty.devSee the Devianceproperty.statsSee the model display in the Command Window. You can find the statistics in the model properties (
CoefficientCovariance,Coefficients,Dispersion,DispersionEstimated, andResiduals).The dispersion parameter in
stats.sglmfitis the scale factor for the standard errors of coefficients, whereas the dispersion parameter in theDispersionproperty of a generalized linear model is the scale factor for the variance of the response. Therefore,stats.sis the square root of theDispersionvalue.
References
[1] Dobson, A. J. An Introduction to Generalized Linear Models. New York: Chapman & Hall, 1990.
[2] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.
[3] Collett, D. Modeling Binary Data. New York: Chapman & Hall, 2002.
Extended Capabilities
Version History
Introduced before R2006a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)