pdist2
Pairwise distance between two sets of observations
Syntax
Description
D = pdist2(X,Y,Distance,DistParameter)Distance and
DistParameter. You can specify
DistParameter only when Distance is
"seuclidean", "minkowski", or
"mahalanobis".
D = pdist2(___,Name,Value)
D = pdist2(X,Y,Distance,'Smallest',K)computes the distance using the metric specified byDistanceand returns theKsmallest pairwise distances to observations inXfor each observation inYin ascending order.D = pdist2(X,Y,Distance,DistParameter,'Largest',K)computes the distance using the metric specified byDistanceandDistParameterand returns theKlargest pairwise distances in descending order.
Examples
Create two matrices with three observations and two variables.
rng('default') % For reproducibility X = rand(3,2); Y = rand(3,2);
Compute the Euclidean distance. The default value of the input argument Distance is 'euclidean'. When computing the Euclidean distance without using a name-value pair argument, you do not need to specify Distance.
D = pdist2(X,Y)
D = 3×3
0.5387 0.8018 0.1538
0.7100 0.5951 0.3422
0.8805 0.4242 1.2050
D(i,j) corresponds to the pairwise distance between observation i in X and observation j in Y.
Create two matrices with three observations and two variables.
rng('default') % For reproducibility X = rand(3,2); Y = rand(3,2);
Compute the Minkowski distance with the default exponent 2.
D1 = pdist2(X,Y,'minkowski')D1 = 3×3
0.5387 0.8018 0.1538
0.7100 0.5951 0.3422
0.8805 0.4242 1.2050
Compute the Minkowski distance with an exponent of 1, which is equal to the city block distance.
D2 = pdist2(X,Y,'minkowski',1)D2 = 3×3
0.5877 1.0236 0.2000
0.9598 0.8337 0.3899
1.0189 0.4800 1.7036
D3 = pdist2(X,Y,'cityblock')D3 = 3×3
0.5877 1.0236 0.2000
0.9598 0.8337 0.3899
1.0189 0.4800 1.7036
Create two matrices with five observations and two variables.
rng(0,"twister") % For reproducibility X = rand(5,2); Y = rand(5,2);
Compute the Mahalanobis distance using the pdist2 function.
D = pdist2(X,Y,"mahalanobis")D = 5×5
2.0012 0.9926 2.1767 1.9656 2.2036
2.3429 0.4318 1.6528 1.7564 1.7453
1.0330 2.5697 2.7833 1.3093 2.3936
3.2463 1.3676 0.1638 1.4094 0.3452
2.6608 1.6585 0.9895 0.6572 0.5121
Compute the Mahalanobis distance between the mean of X and the observations Y. Use the covariance of X for the distance metric parameter.
D2 = pdist2(mean(X),Y,"mahalanobis",cov(X))D2 = 1×5
2.0090 0.9377 1.2824 0.7850 1.0966
Compute the squared Mahalanobis distance using the mahal function.
SqMahalDist = mahal(Y,X)'
SqMahalDist = 1×5
4.0360 0.8792 1.6445 0.6162 1.2025
Compute the square root of each value.
MahalDist = SqMahalDist.^0.5
MahalDist = 1×5
2.0090 0.9377 1.2824 0.7850 1.0966
The Mahalanobis distance values are the same as those returned by the pdist2 function.
Create two matrices with three observations and two variables.
rng('default') % For reproducibility X = rand(3,2); Y = rand(3,2);
Find the two smallest pairwise Euclidean distances to observations in X for each observation in Y.
[D,I] = pdist2(X,Y,'euclidean','Smallest',2)
D = 2×3
0.5387 0.4242 0.1538
0.7100 0.5951 0.3422
I = 2×3
1 3 1
2 2 2
For each observation in Y, pdist2 finds the two smallest distances by computing and comparing the distance values to all the observations in X. The function then sorts the distances in each column of D in ascending order. I contains the indices of the observations in X corresponding to the distances in D.
Create two large matrices of points, and then measure the time used by pdist2 with the default "euclidean" distance metric.
rng default % For reproducibility N = 10000; X = randn(N,1000); Y = randn(N,1000); D = pdist2(X,Y); % Warm up function for more reliable timing information tic D = pdist2(X,Y); standard = toc
standard = 11.1077
Next, measure the time used by pdist2 with the "fasteuclidean" distance metric. Specify a cache size of 100.
D = pdist2(X,Y,"fasteuclidean",CacheSize=100); % Warm up function tic D2 = pdist2(X,Y,"fasteuclidean",CacheSize=100); accelerated = toc
accelerated = 2.0451
Evaluate how many times faster the accelerated computation is compared to the standard.
standard/accelerated
ans = 5.4314
The accelerated version is more than twice as fast for this example.
Define a custom distance function that ignores coordinates with NaN values, and compute pairwise distance by using the custom distance function.
Create two matrices with three observations and three variables.
rng('default') % For reproducibility X = rand(3,3) Y = [X(:,1:2) rand(3,1)]
X =
0.8147 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
Y =
0.8147 0.9134 0.9649
0.9058 0.6324 0.1576
0.1270 0.0975 0.9706
The first two columns of X and Y are identical. Assume that X(1,1) is missing.
X(1,1) = NaN
X =
NaN 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
Compute the Hamming distance.
D1 = pdist2(X,Y,'hamming')
D1 =
NaN NaN NaN
1.0000 0.3333 1.0000
1.0000 1.0000 0.3333
If observation i in X or observation j in Y contains NaN values, the function pdist2 returns NaN for the pairwise distance between i and j. Therefore, D1(1,1), D1(1,2), and D1(1,3) are NaN values.
Define a custom distance function nanhamdist that ignores coordinates with NaN values and computes the Hamming distance. When working with a large number of observations, you can compute the distance more quickly by looping over coordinates of the data.
function D2 = nanhamdist(XI,XJ) %NANHAMDIST Hamming distance ignoring coordinates with NaNs [m,p] = size(XJ); nesum = zeros(m,1); pstar = zeros(m,1); for q = 1:p notnan = ~(isnan(XI(q)) | isnan(XJ(:,q))); nesum = nesum + ((XI(q) ~= XJ(:,q)) & notnan); pstar = pstar + notnan; end D2 = nesum./pstar;
Compute the distance with nanhamdist by passing the function handle as an input argument of pdist2.
D2 = pdist2(X,Y,@nanhamdist)
D2 =
0.5000 1.0000 1.0000
1.0000 0.3333 1.0000
1.0000 1.0000 0.3333
kmeans performs k-means clustering to partition data into k clusters. When you have a new data set to cluster, you can create new clusters that include the existing data and the new data by using kmeans. The kmeans function supports C/C++ code generation, so you can generate code that accepts training data and returns clustering results, and then deploy the code to a device. In this workflow, you must pass training data, which can be of considerable size. To save memory on the device, you can separate training and prediction by using kmeans and pdist2, respectively.
Use kmeans to create clusters in MATLAB® and use pdist2 in the generated code to assign new data to existing clusters. For code generation, define an entry-point function that accepts the cluster centroid positions and the new data set, and returns the index of the nearest cluster. Then, generate code for the entry-point function.
Generating C/C++ code requires MATLAB® Coder™.
Perform k-Means Clustering
Generate a training data set using three distributions.
rng('default') % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.5-ones(100,2); randn(100,2)*0.75];
Partition the training data into three clusters by using kmeans.
[idx,C] = kmeans(X,3);
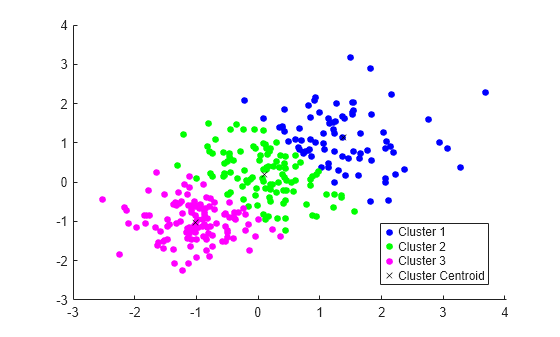
Plot the clusters and the cluster centroids.
figure gscatter(X(:,1),X(:,2),idx,'bgm') hold on plot(C(:,1),C(:,2),'kx') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')
Assign New Data to Existing Clusters
Generate a test data set.
Xtest = [randn(10,2)*0.75+ones(10,2);
randn(10,2)*0.5-ones(10,2);
randn(10,2)*0.75];Classify the test data set using the existing clusters. Find the nearest centroid from each test data point by using pdist2.
[~,idx_test] = pdist2(C,Xtest,'euclidean','Smallest',1);
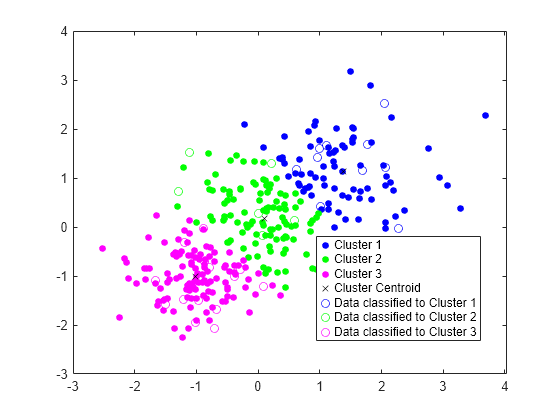
Plot the test data and label the test data using idx_test by using gscatter.
gscatter(Xtest(:,1),Xtest(:,2),idx_test,'bgm','ooo') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid', ... 'Data classified to Cluster 1','Data classified to Cluster 2', ... 'Data classified to Cluster 3')
Generate Code
Generate C code that assigns new data to the existing clusters. Note that generating C/C++ code requires MATLAB® Coder™.
Define an entry-point function named findNearestCentroid that accepts centroid positions and new data, and then find the nearest cluster by using pdist2.
Add the %#codegen compiler directive (or pragma) to the entry-point function after the function signature to indicate that you intend to generate code for the MATLAB algorithm. Adding this directive instructs the MATLAB Code Analyzer to help you diagnose and fix violations that would cause errors during code generation.
type findNearestCentroid % Display contents of findNearestCentroid.m
function idx = findNearestCentroid(C,X) %#codegen [~,idx] = pdist2(C,X,'euclidean','Smallest',1); % Find the nearest centroid
Note: If you click the button located in the upper-right section of this page and open this example in MATLAB®, then MATLAB® opens the example folder. This folder includes the entry-point function file.
Generate code by using codegen (MATLAB Coder). Because C and C++ are statically typed languages, you must determine the properties of all variables in the entry-point function at compile time. To specify the data type and array size of the inputs of findNearestCentroid, pass a MATLAB expression that represents the set of values with a certain data type and array size by using the -args option. For details, see Specify Variable-Size Arguments for Code Generation of Machine Learning Models.
codegen findNearestCentroid -args {C,Xtest}
Code generation successful.
codegen generates the MEX function findNearestCentroid_mex with a platform-dependent extension.
Verify the generated code.
myIndx = findNearestCentroid(C,Xtest); myIndex_mex = findNearestCentroid_mex(C,Xtest); verifyMEX = isequal(idx_test,myIndx,myIndex_mex)
verifyMEX = logical
1
isequal returns logical 1 (true), which means all the inputs are equal. The comparison confirms that the pdist2 function, the findNearestCentroid function, and the MEX function return the same index.
You can also generate optimized CUDA® code using GPU Coder™.
cfg = coder.gpuConfig('mex'); codegen -config cfg findNearestCentroid -args {C,Xtest}
For more information on code generation, see Introduction to Code Generation for Statistics and Machine Learning Functions. For more information on GPU coder, see Get Started with GPU Coder (GPU Coder) and Supported Functions (GPU Coder).
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Albanie, Samuel. Euclidean Distance Matrix Trick. June, 2019. Available at https://samuelalbanie.com/files/Euclidean_distance_trick.pdf.
Extended Capabilities
Version History
Introduced in R2010aSee Also
pdist | createns | knnsearch | ExhaustiveSearcher | KDTreeSearcher