tsne
t-Distributed Stochastic Neighbor Embedding
Description
Y = tsne(X,Name,Value)
Examples
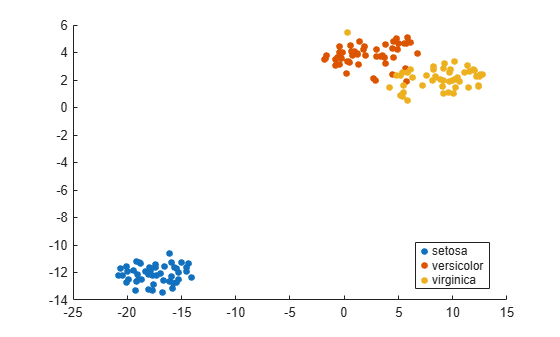
The Fisher iris data set has four-dimensional measurements of irises, and corresponding classification into species. Visualize this data by reducing the dimension using tsne.
load fisheriris rng default % for reproducibility Y = tsne(meas); gscatter(Y(:,1),Y(:,2),species)
Use various distance metrics to try to obtain a better separation between species in the Fisher iris data.
load fisheriris rng('default') % for reproducibility Y = tsne(meas,'Algorithm','exact','Distance','mahalanobis'); subplot(2,2,1) gscatter(Y(:,1),Y(:,2),species) title('Mahalanobis') rng('default') % for fair comparison Y = tsne(meas,'Algorithm','exact','Distance','cosine'); subplot(2,2,2) gscatter(Y(:,1),Y(:,2),species) title('Cosine') rng('default') % for fair comparison Y = tsne(meas,'Algorithm','exact','Distance','chebychev'); subplot(2,2,3) gscatter(Y(:,1),Y(:,2),species) title('Chebychev') rng('default') % for fair comparison Y = tsne(meas,'Algorithm','exact','Distance','euclidean'); subplot(2,2,4) gscatter(Y(:,1),Y(:,2),species) title('Euclidean')
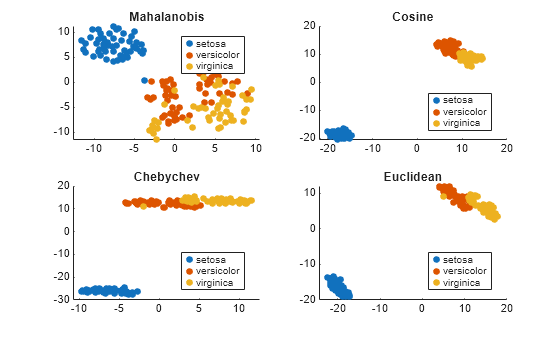
In this case, the cosine, Chebychev, and Euclidean distance metrics give reasonably good separation of clusters. But the Mahalanobis distance metric does not give a good separation.
tsne removes input data rows that contain any NaN entries. Therefore, you must remove any such rows from your classification data before plotting.
For example, change a few random entries in the Fisher iris data to NaN.
load fisheriris rng default % for reproducibility meas(rand(size(meas)) < 0.05) = NaN;
Embed the four-dimensional data into two dimensions using tsne.
Y = tsne(meas,'Algorithm','exact');
Warning: Rows with NaN missing values in X or 'InitialY' values are removed.
Determine how many rows were eliminated from the embedding.
length(species)-length(Y)
ans = 22
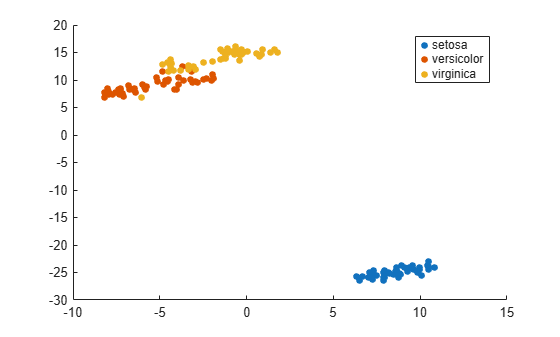
Prepare to plot the result by locating the rows of meas that have no NaN values.
goodrows = not(any(isnan(meas),2));
Plot the results using only the rows of species that correspond to rows of meas with no NaN values.
gscatter(Y(:,1),Y(:,2),species(goodrows))
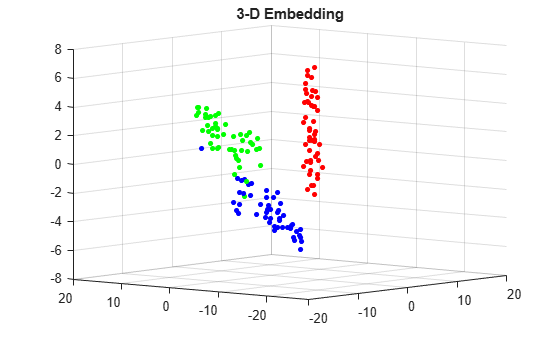
Find both 2-D and 3-D embeddings of the Fisher iris data, and compare the loss for each embedding. It is likely that the loss is lower for a 3-D embedding, because this embedding has more freedom to match the original data.
load fisheriris rng default % for reproducibility [Y,loss] = tsne(meas,'Algorithm','exact'); rng default % for fair comparison [Y2,loss2] = tsne(meas,'Algorithm','exact','NumDimensions',3); fprintf('2-D embedding has loss %g, and 3-D embedding has loss %g.\n',loss,loss2)
2-D embedding has loss 0.1255, and 3-D embedding has loss 0.0980872.
As expected, the 3-D embedding has lower loss.
View the embeddings. Use RGB colors [1 0 0], [0 1 0], and [0 0 1].
For the 3-D plot, convert the species to numeric values using the categorical command, then convert the numeric values to RGB colors using the sparse function as follows. If v is a vector of positive integers 1, 2, or 3, corresponding to the species data, then the command
sparse(1:numel(v),v,ones(size(v)))
is a sparse matrix whose rows are the RGB colors of the species.
gscatter(Y(:,1),Y(:,2),species,eye(3))
title('2-D Embedding')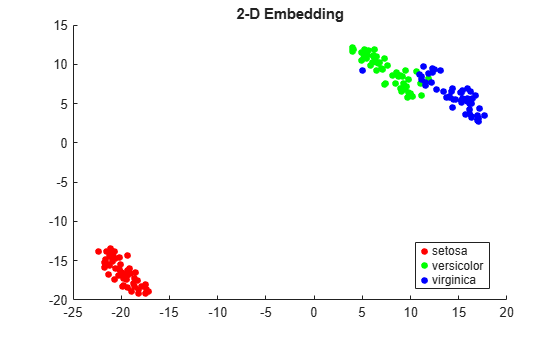
figure v = double(categorical(species)); c = full(sparse(1:numel(v),v,ones(size(v)),numel(v),3)); scatter3(Y2(:,1),Y2(:,2),Y2(:,3),15,c,'filled') title('3-D Embedding') view(-50,8)
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Albanie, Samuel. Euclidean Distance Matrix Trick. June, 2019. Available at https://samuelalbanie.com/files/Euclidean_distance_trick.pdf.