Multicore Code Generation for Dataflow Domain
This example shows how to deploy a noise reduction application on a multicore target hardware using Dataflow.
Before You Begin
To run this example, you must have the following software and hardware installed and set up:
Embedded Coder® Support Package for Xilinx® Zynq® Platform
Zynq board
For details on installing the support package and setting up the Zynq hardware, refer to Install Support for AMD SoC Boards (Embedded Coder).
Introduction
The dataflow execution domain allows you to make use of the multiple cores on the target hardware for computationally intensive signal processing systems.
This example shows how to specify dataflow as the execution domain of a subsystem and improve performance by generating multicore code. The example uses processor-in-the-loop (PIL) simulation for deploying the application on the ARM CPU within a Zynq hardware and execution-time profiling for measuring the performance.
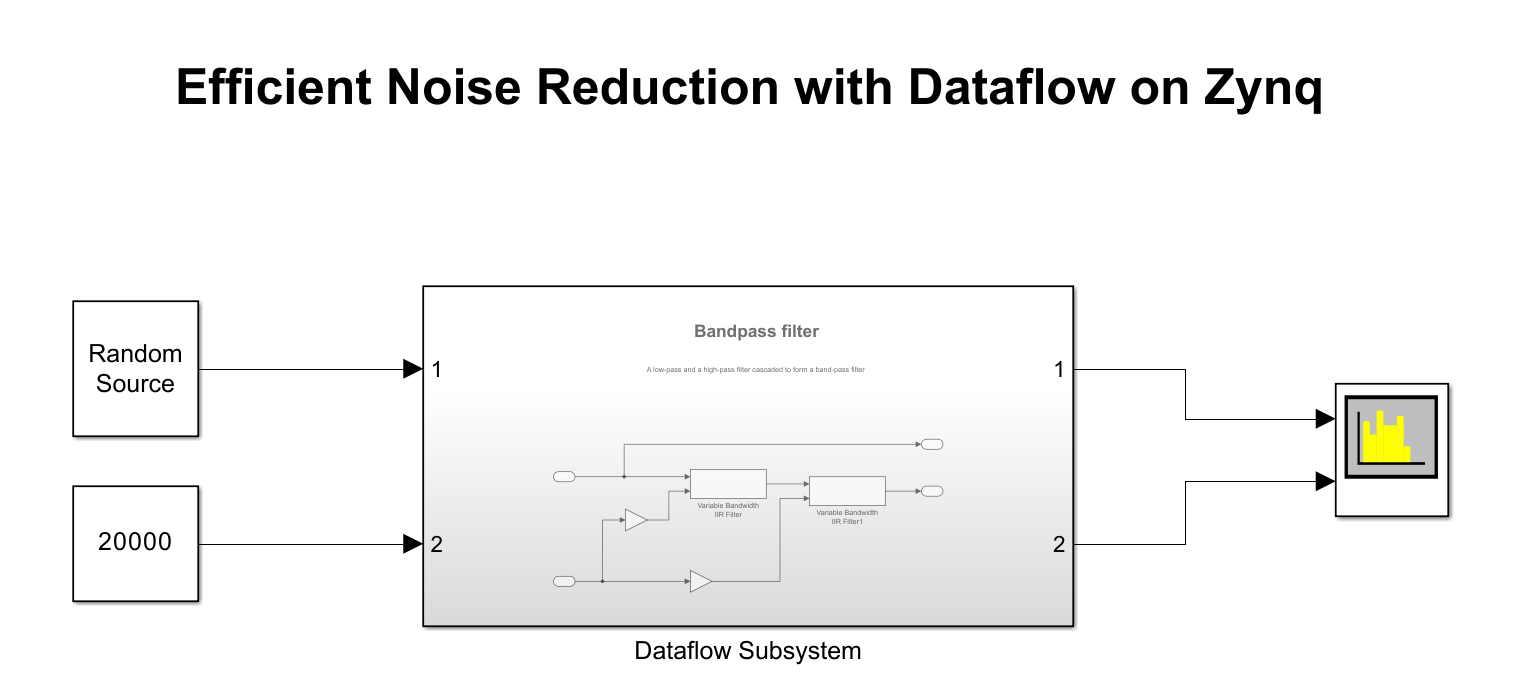
Noise Reduction System
The model in this example uses two Variable Bandwidth IIR filter blocks configured as a low-pass and a high-pass filter respectively. The filters are connected in series within the Dataflow Subsystem to collectively form a bandpass noise filtering system. The source signal is a random noise. Open dataflowzynq model.
Configure Hardware Settings
Configure the model to generate code for the Zynq-based hardware. This example uses a Zynq-7000 SoC ZC702 Evaluation Kit and performs processor-in-the-loop (PIL) simulation on the target hardware.

Configure PIL simulation and execution-time profiling
Configure the model to generate a PIL block when code is generated for a subsystem. This allows you to measure the time taken for the Dataflow Subsystem block on the target hardware. For details on configuring PIL simulation with PIL blocks, see .
Enable profiling of function execution times for subsystems. For details on profiling with PIL, see Create Execution-Time Profile for Generated Code (Embedded Coder).
Generate code and simulate on target
Build the Dataflow Subsystem block. This step generates the PIL block from Dataflow Subsystem.

Replace Dataflow Subsystem block in the original model with the generated PIL block.
Simulate the model and measure average execution time of the subsystem using the profiling results retrieved at the end of PIL simulation. Average execution time can be obtained by dividing the total execution time taken by the subsystem by the number of calls to the subsystem. This number is computed and shown below.
Average execution time of generated code for single-core = 5.6 ms
Specify Dataflow Execution Domain for Subsystem
Dataflow domains automatically partition your model and generates code with multiple threads for multicore targets. In Simulink, you specify dataflow as the execution domain for a subsystem by setting the Domain parameter to Dataflow using Property Inspector. You can view the Property Inspector for a subsystem, first by selecting the subsystem and then selecting View>Property Inspector. In the Property Inspector, you can set the domain to dataflow by selecting Set domain specification and then selecting "Dataflow" for Domain setting. You can also use the Dataflow Subsystem block from the Dataflow library of DSP System toolbox to get a subsystem that is preconfigured with the dataflow execution domain.

To increase the throughput of a system, it can be advantageous to increase the latency of a system. Specify the Latency value in the Execution tab of the Property Inspector. Setting a Latency value of 1 will add a pipeline delay to break dependency between the filter blocks and enable the dataflow domain to achieve concurrency.
Multi-Core Code Generation of Dataflow Subsystem
To enable multicore code generation, you must select the Allow tasks to execute concurrently on target parameter in the Solver pane of the Configuration Parameters under Solver details.
Rebuild the Dataflow Subsystem block to generate the multicore version of the PIL block.
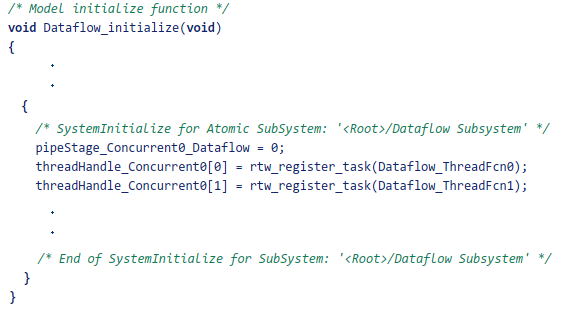
After code generation is completed for the subsystem, you can observe the generated functions for each concurrent thread created by the dataflow domain and how they are triggered during execution of the model step function.
The Dataflow Subsystem block generates two thread functions, Dataflow_ThreadFcn0 and Dataflow_ThreadFcn1.
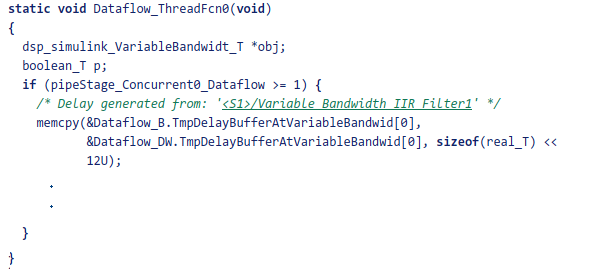

The thread functions are registered as POSIX threads at model initialization and triggered during each model step. The consecutive trigger and wait function calls implement the fork-join pattern for the dataflow threads.


Multicore Execution Performance
Simulate the model with the multicore version of the PIL block and repeat the measurement for the execution time of the subsystem.
Average execution time of generated code for multicore = 3.9 ms
Actual speedup with dataflow: 1.44x
Copyright 2020 The MathWorks, Inc.