trainAutoencoder
Train an autoencoder
Syntax
Description
autoenc = trainAutoencoder(X,hiddenSize)autoenc, with the hidden representation
size of hiddenSize.
autoenc = trainAutoencoder(___,Name,Value)autoenc, for any of the above
input arguments with additional options specified by one or more Name,Value pair
arguments.
For example, you can specify the sparsity proportion or the maximum number of training iterations.
Examples
Load the sample data.
X = abalone_dataset;
X is an 8-by-4177 matrix defining eight attributes for 4177 different abalone shells: sex (M, F, and I (for infant)), length, diameter, height, whole weight, shucked weight, viscera weight, shell weight. For more information on the dataset, type help abalone_dataset in the command line.
Train a sparse autoencoder with default settings.
autoenc = trainAutoencoder(X);
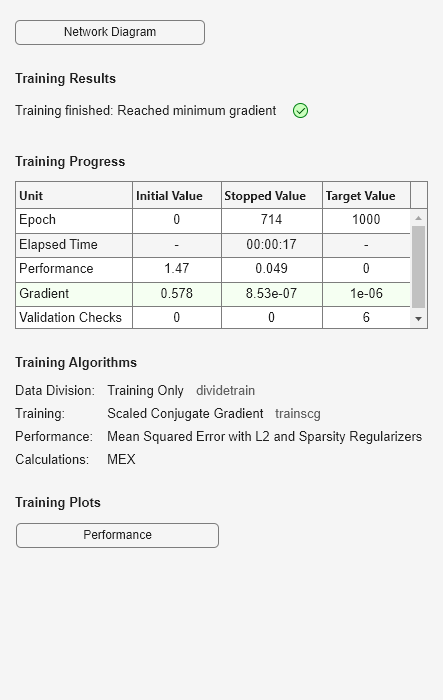
Reconstruct the abalone shell ring data using the trained autoencoder.
XReconstructed = predict(autoenc,X);
Compute the mean squared reconstruction error.
mseError = mse(X-XReconstructed)
mseError = 0.0167
Load the sample data.
X = abalone_dataset;
X is an 8-by-4177 matrix defining eight attributes for 4177 different abalone shells: sex (M, F, and I (for infant)), length, diameter, height, whole weight, shucked weight, viscera weight, shell weight. For more information on the dataset, type help abalone_dataset in the command line.
Train a sparse autoencoder with hidden size 4, 400 maximum epochs, and linear transfer function for the decoder.
autoenc = trainAutoencoder(X,4,'MaxEpochs',400,... 'DecoderTransferFunction','purelin');

Reconstruct the abalone shell ring data using the trained autoencoder.
XReconstructed = predict(autoenc,X);
Compute the mean squared reconstruction error.
mseError = mse(X-XReconstructed)
mseError = 0.0046
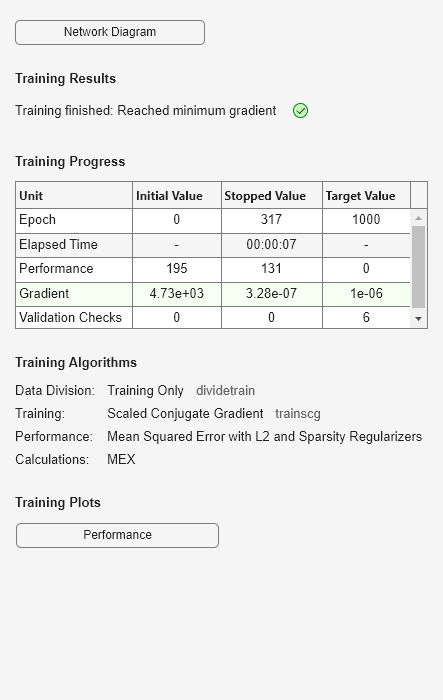
Generate the training data.
rng(0,'twister'); % For reproducibility n = 1000; r = linspace(-10,10,n)'; x = 1 + r*5e-2 + sin(r)./r + 0.2*randn(n,1);
Train autoencoder using the training data.
hiddenSize = 25; autoenc = trainAutoencoder(x',hiddenSize,... 'EncoderTransferFunction','satlin',... 'DecoderTransferFunction','purelin',... 'L2WeightRegularization',0.01,... 'SparsityRegularization',4,... 'SparsityProportion',0.10);
Generate the test data.
n = 1000; r = sort(-10 + 20*rand(n,1)); xtest = 1 + r*5e-2 + sin(r)./r + 0.4*randn(n,1);
Predict the test data using the trained autoencoder, autoenc.
xReconstructed = predict(autoenc,xtest');
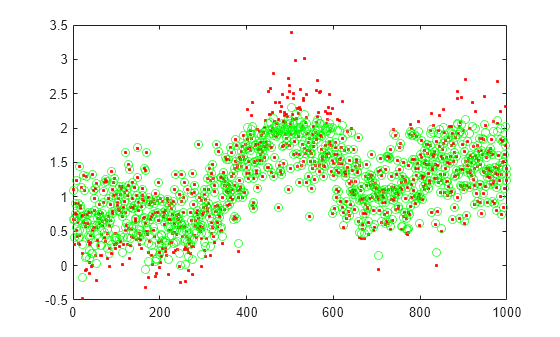
Plot the actual test data and the predictions.
figure; plot(xtest,'r.'); hold on plot(xReconstructed,'go');
Load the training data.
XTrain = digitTrainCellArrayData;
The training data is a 1-by-5000 cell array, where each cell containing a 28-by-28 matrix representing a synthetic image of a handwritten digit.
Train an autoencoder with a hidden layer containing 25 neurons.
hiddenSize = 25; autoenc = trainAutoencoder(XTrain,hiddenSize,... 'L2WeightRegularization',0.004,... 'SparsityRegularization',4,... 'SparsityProportion',0.15);
Load the test data.
XTest = digitTestCellArrayData;
The test data is a 1-by-5000 cell array, with each cell containing a 28-by-28 matrix representing a synthetic image of a handwritten digit.
Reconstruct the test image data using the trained autoencoder, autoenc.
xReconstructed = predict(autoenc,XTest);
View the actual test data.
figure; for i = 1:20 subplot(4,5,i); imshow(XTest{i}); end
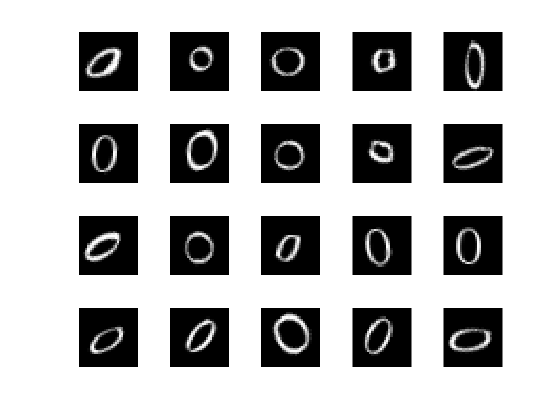
View the reconstructed test data.
figure; for i = 1:20 subplot(4,5,i); imshow(xReconstructed{i}); end
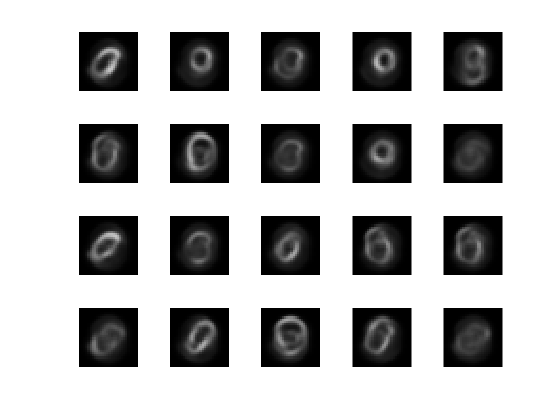
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] Moller, M. F. “A Scaled Conjugate Gradient Algorithm for Fast Supervised Learning”, Neural Networks, Vol. 6, 1993, pp. 525–533.
[2] Olshausen, B. A. and D. J. Field. “Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1.” Vision Research, Vol.37, 1997, pp.3311–3325.
Version History
Introduced in R2015b