Least-Squares (Model Fitting) Algorithms
Least Squares Definition
Least squares, in general, is the problem of finding a vector x that is a local minimizer to a function that is a sum of squares, possibly subject to some constraints:
such that A·x ≤ b, Aeq·x = beq, lb ≤ x ≤ ub, ineqnonlin(x) ≤ 0, eqnonlin(x) = 0.
The linear least squares problem is: given a matrix C and vector d, find x that minimizes ‖Cx – d‖2 subject to bounds and linear constraints.
There are several Optimization Toolbox™ solvers available for various types of F(x) and various types of constraints:
| Solver | F(x) | Constraints |
|---|---|---|
mldivide | C·x – d | None |
lsqnonneg | C·x – d | x ≥ 0 |
lsqlin | C·x – d | Bound, linear |
lsqnonlin | General F(x) | General linear and nonlinear |
lsqcurvefit | F(x, xdata) – ydata | General linear and nonlinear |
There are six least-squares algorithms in Optimization Toolbox solvers, in addition to the algorithms used in mldivide:
lsqlininterior-pointlsqlinactive-setTrust-region-reflective (nonlinear or linear least-squares, bound constraints)
Levenberg-Marquardt (nonlinear least-squares, bound constraints)
The
fmincon"interior-point"algorithm, modified for the nonlinear least-squares solverslsqnonlinandlsqcurvefit(general linear and nonlinear constraints).The algorithm used by
lsqnonneg
All the algorithms except lsqlin active-set can use sparse
data; see Sparsity in Optimization Algorithms. For a
general survey of nonlinear least-squares methods, see Dennis [8]. Specific details on the Levenberg-Marquardt method can be found
in Moré [28].
For linear least squares without constraints, the problem is to come up with a
least-squares solution to the problem Cx = d. You can solve this problem with mldivide or lsqminnorm. When the problem has linear or bound constraints, use
lsqlin. For general nonlinear
constraints, uses lsqnonlin.
Linear Least Squares: Interior-Point or Active-Set
The lsqlin
"interior-point" algorithm uses the interior-point-convex quadprog Algorithm, and the lsqlin
"active-set" algorithm uses the active-set
quadprog algorithm. The quadprog
problem definition is to minimize a quadratic function
subject to linear constraints and bound constraints. The
lsqlin function minimizes the squared 2-norm of the vector
Cx – d subject to linear constraints and bound
constraints. In other words, lsqlin minimizes
This fits into the quadprog framework by setting the
H matrix to
2CTC and the c
vector to (–2CTd). (The additive term
dTd has no effect on the location
of the minimum.) After this reformulation of the lsqlin
problem, quadprog calculates the solution.
Note
The quadprog
"interior-point-convex" algorithm has two code paths. It
takes one when the Hessian matrix H is an ordinary (full)
matrix of doubles, and it takes the other when H is a sparse
matrix. For details of the sparse data type, see Sparse Matrices.
Generally, the algorithm is faster for large problems that have relatively few
nonzero terms when you specify H as sparse. Similarly, the algorithm
is faster for small or relatively dense problems when you specify
H as full.
Trust-Region-Reflective Least Squares
Trust-Region-Reflective Least Squares Algorithm
Many of the methods used in Optimization Toolbox solvers are based on trust regions, a simple yet powerful concept in optimization.
To understand the trust-region approach to optimization, consider the unconstrained minimization problem, minimize f(x), where the function takes vector arguments and returns scalars. Suppose you are at a point x in n-space and you want to improve, i.e., move to a point with a lower function value. The basic idea is to approximate f with a simpler function q, which reasonably reflects the behavior of function f in a neighborhood N around the point x. This neighborhood is the trust region. A trial step s is computed by minimizing (or approximately minimizing) over N. This is the trust-region subproblem,
| (1) |
The current point is updated to be x + s if f(x + s) < f(x); otherwise, the current point remains unchanged and N, the region of trust, is shrunk and the trial step computation is repeated.
The key questions in defining a specific trust-region approach to minimizing f(x) are how to choose and compute the approximation q (defined at the current point x), how to choose and modify the trust region N, and how accurately to solve the trust-region subproblem. This section focuses on the unconstrained problem. Later sections discuss additional complications due to the presence of constraints on the variables.
In the standard trust-region method ([48]), the quadratic approximation q is defined by the first two terms of the Taylor approximation to F at x; the neighborhood N is usually spherical or ellipsoidal in shape. Mathematically the trust-region subproblem is typically stated
| (2) |
where g is the gradient of f at the current point x, H is the Hessian matrix (the symmetric matrix of second derivatives), D is a diagonal scaling matrix, Δ is a positive scalar, and ‖ . ‖ is the 2-norm. Good algorithms exist for solving Equation 2 (see [48]); such algorithms typically involve the computation of all eigenvalues of H and a Newton process applied to the secular equation
Such algorithms provide an accurate solution to Equation 2. However, they require time proportional to several factorizations of H. Therefore, for trust-region problems a different approach is needed. Several approximation and heuristic strategies, based on Equation 2, have been proposed in the literature ([42] and [50]). The approximation approach followed in Optimization Toolbox solvers is to restrict the trust-region subproblem to a two-dimensional subspace S ([39] and [42]). Once the subspace S has been computed, the work to solve Equation 2 is trivial even if full eigenvalue/eigenvector information is needed (since in the subspace, the problem is only two-dimensional). The dominant work has now shifted to the determination of the subspace.
The two-dimensional subspace S is determined with the aid of a preconditioned conjugate gradient process described below. The solver defines S as the linear space spanned by s1 and s2, where s1 is in the direction of the gradient g, and s2 is either an approximate Newton direction, i.e., a solution to
| (3) |
or a direction of negative curvature,
| (4) |
The philosophy behind this choice of S is to force global convergence (via the steepest descent direction or negative curvature direction) and achieve fast local convergence (via the Newton step, when it exists).
A sketch of unconstrained minimization using trust-region ideas is now easy to give:
Formulate the two-dimensional trust-region subproblem.
Solve Equation 2 to determine the trial step s.
If f(x + s) < f(x), then x = x + s.
Adjust Δ.
These four steps are repeated until convergence. The trust-region dimension Δ is adjusted according to standard rules. In particular, it is decreased if the trial step is not accepted, i.e., f(x + s) ≥ f(x). See [46] and [49] for a discussion of this aspect.
Optimization Toolbox solvers treat a few important special cases of f with specialized functions: nonlinear least-squares, quadratic functions, and linear least-squares. However, the underlying algorithmic ideas are the same as for the general case. These special cases are discussed in later sections.
Large Scale Nonlinear Least Squares
An important special case for f(x) is the nonlinear least-squares problem
| (5) |
where F(x) is a vector-valued function with component i of F(x) equal to fi(x). The basic method used to solve this problem is the same as in the general case described in Trust-Region Methods for Nonlinear Minimization. However, the structure of the nonlinear least-squares problem is exploited to enhance efficiency. In particular, an approximate Gauss-Newton direction, i.e., a solution s to
| (6) |
(where J is the Jacobian of F(x)) is used to help define the two-dimensional subspace S. Second derivatives of the component function fi(x) are not used.
In each iteration the method of preconditioned conjugate gradients is used to approximately solve the normal equations, i.e.,
although the normal equations are not explicitly formed.
Large Scale Linear Least Squares
In this case the function f(x) to be solved is
possibly subject to linear constraints. The algorithm generates strictly feasible iterates converging, in the limit, to a local solution. Each iteration involves the approximate solution of a large linear system (of order n, where n is the length of x). The iteration matrices have the structure of the matrix C. In particular, the method of preconditioned conjugate gradients is used to approximately solve the normal equations, i.e.,
although the normal equations are not explicitly formed.
The subspace trust-region method is used to determine a search direction. However, instead of restricting the step to (possibly) one reflection step, as in the nonlinear minimization case, a piecewise reflective line search is conducted at each iteration, as in the quadratic case. See [45] for details of the line search. Ultimately, the linear systems represent a Newton approach capturing the first-order optimality conditions at the solution, resulting in strong local convergence rates.
Jacobian Multiply Function. lsqlin can solve the
linearly-constrained least-squares problem without using the matrix
C explicitly. Instead, it uses a Jacobian multiply
function jmfun,
W = jmfun(Jinfo,Y,flag)
that you provide. The function must calculate the following products for a matrix Y:
If
flag == 0thenW = C'*(C*Y).If
flag > 0thenW = C*Y.If
flag < 0thenW = C'*Y.
This can be useful if C is large, but contains enough
structure that you can write jmfun without forming
C explicitly. For an example, see Jacobian Multiply Function with Linear Least Squares.
Levenberg-Marquardt Method
The least-squares problem minimizes a function f(x) that is a sum of squares.
| (7) |
Problems of this type occur in a large number of practical applications, especially those that involve fitting model functions to data, such as nonlinear parameter estimation. This problem type also appears in control systems, where the objective is for the output y(x,t) to follow a continuous model trajectory φ(t) for vector x and scalar t. This problem can be expressed as
| (8) |
where y(x,t) and φ(t) are scalar functions.
Discretize the integral to obtain an approximation
| (9) |
where the ti are evenly spaced. In this problem, the vector F(x) is
In this type of problem, the residual ‖F(x)‖ is likely to be small at the optimum, because the general practice is to set realistically achievable target trajectories. Although you can minimize the function in Equation 7 using a general, unconstrained minimization technique, as described in Basics of Unconstrained Optimization, certain characteristics of the problem can often be exploited to improve the iterative efficiency of the solution procedure. The gradient and Hessian matrix of Equation 7 have a special structure.
Denoting the m-by-n Jacobian matrix of F(x) as J(x), gradient vector of f(x) as G(x), Hessian matrix of f(x) as H(x), and Hessian matrix of each Fi(x) as Di(x),
| (10) |
where
A property of the matrix Q(x) is that when the residual ‖F(x)‖ tends towards zero as xk approaches the solution, then Q(x) also tends towards zero. So, when ‖F(x)‖ is small at the solution, an effective method is to use the Gauss-Newton direction as a basis for an optimization procedure.
At each major iteration k, the Gauss-Newton method obtains a search direction dk that is a solution of the linear least-squares problem
| (11) |
The direction derived from this method is equivalent to the Newton direction when the terms of Q(x) = 0. The algorithm can use the search direction dk as part of a line search strategy to ensure that the function f(x) decreases at each iteration.
The Gauss-Newton method often encounters problems when the second-order term Q(x) is nonnegligible. The Levenberg-Marquardt method overcomes this problem.
The Levenberg-Marquardt method (see [25] and [27]) uses a search direction that is a solution of the linear set of equations
| (12) |
or, optionally, of the equations
| (13) |
where the scalar λk controls both the
magnitude and direction of dk, and
diag(A) means the matrix of diagonal terms in
A. Set the option ScaleProblem to
"none" to choose Equation 12, or set ScaleProblem to
"Jacobian" to choose Equation 13.
You set the initial value of the parameter
λ0 using the
InitDamping option. Occasionally, the 0.01
default value of this option can be unsuitable. If you find that the
Levenberg-Marquardt algorithm makes little initial progress, try setting
InitDamping to a different value from the default, such as
1e2.
When λk is zero, the direction dk is identical to that of the Gauss-Newton method. As λk tends towards infinity, dk tends towards the steepest descent direction, with magnitude tending towards zero. Consequently, for some sufficiently large λk, the term ‖ F(xk + dk)‖ < ‖ F(xk)‖ holds true, where ‖ represents the Euclidean norm. Therefore, you can control the term λk to ensure descent even when the algorithm encounters second-order terms, which restrict the efficiency of the Gauss-Newton method. When the step is successful (gives a lower function value), the algorithm sets λk+1 = λk/10. When the step is unsuccessful, the algorithm sets λk+1 = λk*10.
Internally, the Levenberg-Marquardt algorithm uses an optimality tolerance
(stopping criterion) of 1e-4 times the function tolerance.
The Levenberg-Marquardt method, therefore, uses a search direction that is a cross between the Gauss-Newton direction and the steepest descent direction.
Another advantage to the Levenberg-Marquardt method is when the Jacobian J is rank-deficient. In this case, the Gauss-Newton method can have numerical issues because the minimization problem in Equation 11 is ill-posed. In contrast, the Levenberg-Marquardt method has full rank at each iteration, and, therefore, avoids these issues.
The following figure shows the iterations of the Levenberg-Marquardt method when minimizing Rosenbrock's function, a notoriously difficult minimization problem that is in least-squares form.
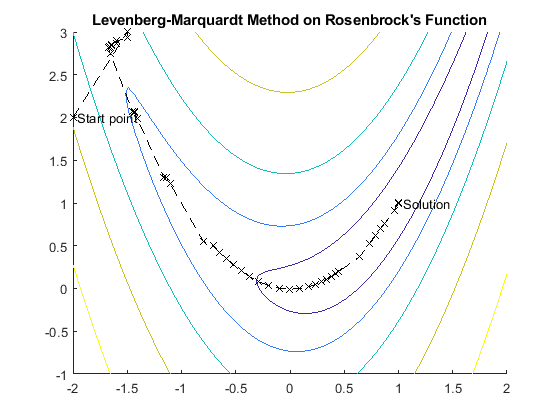
For a more complete description of this figure, see Banana Function Minimization.
Bound Constraints in Levenberg-Marquardt Method
When the problem contains bound constraints, lsqcurvefit
and lsqnonlin modify the Levenberg-Marquardt iterations. If
a proposed iterative point x lies outside of the bounds, the
algorithm projects the step onto the nearest feasible point. In other words,
with P defined as the projection
operator that projects infeasible points onto the feasible region, the algorithm
modifies the proposed point x to
P(x). By definition, the projection
operator P operates on each component
xi independently according
to
or, equivalently,
The algorithm modifies the stopping criterion for the first-order optimality measure. Let x be a proposed iterative point. In the unconstrained case, the stopping criterion is
| (14) |
where tol is the optimality tolerance value, which is
1e-4*FunctionTolerance. In the bounded case, the stopping
criterion is
| (15) |
To understand this criterion, first note that if x is in the interior of the feasible region, then the operator P has no effect. So, the stopping criterion becomes
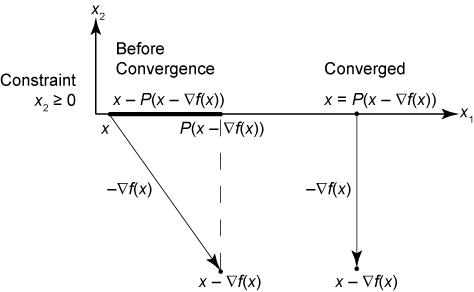
which is the same as the original unconstrained stopping criterion, . If the boundary constraint is active, meaning x – ∇f(x) is not feasible, then at a point where the algorithm should stop, the gradient at a point on the boundary is perpendicular to the boundary. Therefore, the point x is equal to P(x – ∇f(x)), the projection of the steepest descent step, as shown in the following figure.
Levenberg-Marquardt Stopping Condition
Modified fmincon Algorithm for Constrained Least Squares
To handle linear and nonlinear constraints, the
"interior-point" algorithm of the
lsqnonlin and lsqcurvefit solvers
internally calls a modified version of the fmincon
"interior-point" algorithm. The modified version uses a different
Hessian approximation than the approximation used when you run
fmincon. By default, fmincon uses the
BFGS Hessian approximation. Later in this section you can find the different Hessian
approximation that the least-squares solvers use. For details of the
fmincon
"interior-point" algorithm and its Hessian approximation, see
fmincon Interior Point Algorithm.
In the context of least squares, the objective function f(x) is a vector, not a scalar. The sum of squares to minimize is
fT(x)f(x).
The problem to solve is
such that
ineqnonlin(x) ≤ 0
eqnonlin(x) = 0.
The Lagrangian of this problem is
The gradient with respect to x of the Lagrangian is
Here, F is the Jacobian of the objective function
and AE and AI are the Jacobians of the equality constraint function eqnonlin(x) and the inequality constraint function ineqnonlin(x), respectively.
The Karush-Kuhn-Tucker (KKT) conditions for the problem are
Here, the variables s and λI are nonnegative, S = diag(s), μ is the barrier parameter that tends to zero as iterations increase, and e is a vector of ones.
To solve these equations, the software performs iterations. Call the iteration number k. The algorithm attempts to solve the equations by taking a step Δx, Δs, ΔλE, ΔλI using this update equation:
Here, H is the Hessian of the objective function. Using the BFGS Hessian approximation, the approximate Hessian Bk+1 at step k + 1 is
| (16) |
where
The initial value for this Hessian approximation is B0 = I.
For a discussion of this approach in fmincon, see Updating the Hessian Matrix.
The least-squares BFGS Hessian update has the following difference compared to the
fmincon Hessian update. The Hessian of the least-squares
objective function is
The least-squares Hessian update uses the first term, 2FTF, as a separate quantity, and updates the Hessian approximation using the BFGS formula without the 2FTF term. In other words, the BFGS Hessian update uses the Hessian update formula Equation 16 for Bk, where the Hessian approximation for the Lagrangian (objective function plus Lagrange multipliers times the constraints) is 2FTF + Bk, and the quantities sk and yk are
| (17) |
This modified Hessian approximation accounts for the difference between
fmincon iterations and lsqnonlin or
lsqcurvefit iterations for the same problem. Internally,
the least-squares solvers use this Hessian approximation, Equation 16 and Equation 17, as a custom
Hessian function in the fmincon solver.
See Also
quadprog | lsqlin | lsqcurvefit | lsqnonlin | lsqnonneg