Deploy Predictive Maintenance Algorithms
Deployment or integration of a predictive maintenance algorithm is typically the final stage of the algorithm-development workflow. How you ultimately deploy the algorithm can also be a consideration in earlier stages of algorithm design. For example, whether the algorithm runs on embedded hardware, as a stand-alone executable, or as a web application can have impact on requirements and other aspects of the complete predictive-maintenance system design. MathWorks® products support several phases of the process for developing, deploying, and validating predictive maintenance algorithms.
The design-V, a conceptual diagram often used in the context of Model-Based Design, is also relevant when considering the design and deployment of a predictive maintenance algorithm. The design-V highlights the key deployment and implementation phases:
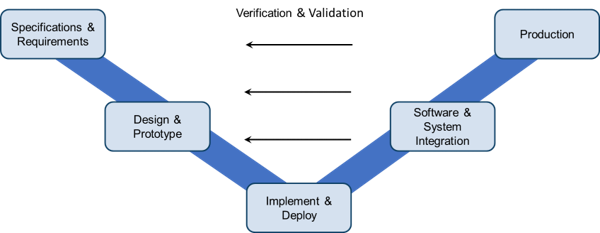
Specifications and Requirements
Developing specifications and requirements includes considerations both from the predictive maintenance algorithm perspective and the deployment perspective. Predictive maintenance algorithm requirements come from an understanding of the system coupled with mathematical analysis of the process, its signals, and expected faults. Deployment requirements can include requirements on:
Memory and computational power.
Operating mode. For instance, the algorithm might be a batch process that runs at some fixed time interval such as once a day. Or, it might be a streaming process that runs every time new data is available.
Maintenance or update of the algorithm. For example, the deployed algorithm might be fixed, changing only changes through occasional updates. Or, you might develop an algorithm that adapts and automatically updates as new data is available.
Where the algorithm runs, such as whether the algorithm must run in a cloud, or be offered as a web service.
Design and Prototype
This phase of the design-V includes data management, design of data preprocessing, identification of condition indicators, and training of a classification model for fault detection or a model for estimating remaining useful life. (See Designing Algorithms for Condition Monitoring and Predictive Maintenance, which provides an overview of the algorithm-design process.) In the design phase, you often use historic or synthesized data to test and tune the developed algorithm.
Implement and Deploy
Once you have developed a candidate algorithm, the next phase is to implement and deploy the algorithm. MathWorks products support many different application needs and resource constraints, ranging from standalone applications to web services.
MATLAB Coder and Simulink Coder
In some cases, you can use MATLAB® Coder™ and Simulink® Coder to generate C/C++ code from MATLAB or Simulink. For example:
You can generate code for estimating remaining useful life with all Predictive Maintenance Toolbox™ RUL model types using MATLAB Coder. For examples, see Generate Code for Predicting Remaining Useful Life and Generate Code That Preserves RUL Model State for System Restart.
Many System Identification Toolbox™ functions support code generation. For example, you can generate code from algorithms that use state estimation (such as
extendedKalmanFilter) and recursive parameter estimation (such asrecursiveAR).Many Signal Processing Toolbox™ and Statistics and Machine Learning Toolbox™ functions and objects also support MATLAB Coder.
For a more comprehensive list of MathWorks functionality with code-generation support, see Functions and Objects Supported for C/C++ Code Generation (MATLAB Coder).
MATLAB Compiler
Use MATLAB Compiler™ to create standalone applications or shared libraries to execute algorithms developed using Predictive Maintenance Toolbox. You can use MATLAB Compiler to deploy MATLAB code in many ways, including as a standalone Windows® application, a shared library, an Excel® add-in, a Microsoft® .NET assembly, or a generic COM component. Such applications or libraries run outside the MATLAB environment using the MATLAB Runtime, which is freely distributable. The MATLAB Runtime can be packaged and installed with your application, or downloaded during the installation process. For more information about deployment with MATLAB Compiler, see Get Started with MATLAB Compiler (MATLAB Compiler).
MATLAB Production Server
Use MATLAB Production Server™ to integrate your algorithms into web, database, and enterprise applications. MATLAB Production Server leverages the MATLAB Compiler to run your applications on dedicated servers or a cloud. You can package your predictive maintenance algorithms using MATLAB Compiler SDK™, which extends the functionality of MATLAB Compiler to let you build C/C++ shared libraries, Microsoft .NET assemblies, Java® classes, or Python® packages from MATLAB programs. Then, you can deploy the generated libraries to MATLAB Production Server without recoding or creating custom infrastructure.
ThingSpeak
The ThingSpeak™ Internet of Things (IoT) analytics platform service lets you aggregate, visualize, and analyze live data streams in the cloud. For diagnostics and prognostics algorithms that run at intervals of 5 minutes or longer, you can use the ThingSpeak IoT platform to visualize results and monitor the condition of your system. You can also use ThingSpeak as a quick and easy prototyping platform before deployment using the MATLAB Production Server. You can transfer diagnostic data using ThingSpeak web services and use its charting tools to create dashboards for monitoring progress and generating failure alarms. ThingSpeak can communicate directly with desktop MATLAB or MATLAB code embedded in target devices.
Where to Deploy
One choice you often have to make is to whether to deploy your algorithm on an embedded system or on the cloud.
A cloud implementation can be useful when you are gathering and storing large amounts of data on the cloud. Removing the need to transfer data between the cloud and local machines that are running the prognostics and health monitoring algorithm makes the maintenance process more effective. Results calculated on the cloud can be made available through tweets, email notifications, web apps, and dashboards. For cloud implementations, you can use ThingSpeak or MATLAB Production Server.
Alternatively, the algorithm can run on embedded devices that are closer to the actual equipment. The main benefits of doing this are that the amount of information sent is reduced as data is transmitted only when needed, and updates and notifications about equipment health are immediately available without any delay. For embedded implementations, you can use MATLAB Compiler, MATLAB Coder, or Simulink Coder to generate code that runs on a local machine.
A third option is to use a combination of the two. The preprocessing and feature extraction parts of the algorithm can be run on embedded devices, while the predictive model can run on the cloud and generate notifications as needed. In systems such as oil drills and aircraft engines that are run continuously and generate huge amounts of data, storing all the data on board or transmitting it is not always viable because of cellular bandwidth and cost limitations. Using an algorithm that operates on streaming data or on batches of data lets you store and send data only when needed.
Software and System Integration
After you have developed a deployment candidate, you test and validate algorithm performance under real-life conditions. This phase can include designing tests for verification, software-in-the-loop testing, or hardware-in-the-loop testing. This phase is critical to validate both the requirements and the developed algorithm. It often leads to revisions in the requirements, the algorithm, or the implementation, iterating on earlier phases in the design-V.
Production
Finally, you put the algorithm into the production environment. Often this phase includes performance monitoring and further iteration on the design requirements and algorithm as you gain operational experience.