Reinforcement Learning Environments
In a reinforcement learning scenario, where you train an agent to complete a task, the environment models the external system (that is the world) with which the agent interacts. A multiagent environment interacts with more than one agent at the same time.
In control systems applications, this external system is often referred to as the plant. Any reference signal that might need to be tracked by some of the environment variables is also included in the environment.
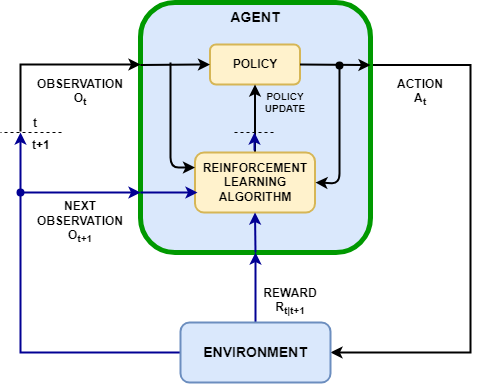
The agent and the environment interact at each of a sequence of discrete time steps:
At a given time step t, the environment is in a state S(t), which results in the observation O(t).
Based on O(t) and its internal policy function, the agent calculates an action A(t).
Based on both the state S(t) and the action A(t), and according to its internal dynamics, the environment updates its state to S(t+1), which results in the next observation O(t+1).
Based on S(t), A(t), and S(t+1), the environment also calculates a scalar reward R(t+1). The reward is an immediate measure of how good the action A(t) is. Note that neither the next observation O(t+1) not the reward R(t+1) depend on the next action A(t+1).
At the next time step t+1 the agent receives the observation O(t+1) and the reward R(t+1).
Based on the history of observations and rewards received, the learning algorithm updates the agent policy parameters in an attempt to improve the policy function. The parameter update may occur at each step or after a subsequence of steps.
Based on O(t+1) and on its policy function, the agent calculates the next action A(t+1), and the process is repeated.
Starting from time t=1 and using subscripts to indicate time, the causal sequence of events, often also called trajectory, can be summarized as O1,A1,R2,O2,A2. The interaction between the environment and the agent is also illustrated in the following figure, where the dashed lines represent a delay of one step.
By convention, the observation can be divided into one or more
channels, each of which carries a group of single elements all
belonging to either a numeric (infinite and continuous) set or a finite (discrete) set. Each
group can be organized according to any number of dimensions (for example a vector or a
matrix). Only one channel is allowed for the action; also, the reward must be a numeric
scalar. For more information on specification objects for actions and observations, see
rlFiniteSetSpec and
rlNumericSpec.
Environment Objects
Reinforcement Learning Toolbox™ represents environments with MATLAB® objects. Such objects interact with agents using object functions (methods)
such as step or reset. Specifically, at the
beginning of each training or simulation episode, the reset function is called (by a
training or simulation function) to set the environment initial condition. Then at each
training or simulation time step, the step function is called to update the state of the
environment and return the next state along with a reward.
After you create an environment object in the MATLAB workspace, you can extract observation and action specifications from the
variable. You can then use these specifications to create an agent that works within your
environment. You can then use both the environment and agent variables as arguments for the
built-in functions train and sim, which train or
simulate the agent within the environment, respectively. Alternatively, you can create your
custom training or simulation loop that calls the environment reset and
step functions directly.
The following sections summarize the different types of environment provided by the software.
Markov Decision Process (MDP) Environments
MDP environments are environments in which state and observation belong to finite spaces, and state transitions are in general governed by stochastic rules.
Grid world environments are a special case of MDP environments. Here, the state represents a position in a two-dimensional grid, while the action represents a move from the current position to the next, which an agent might attempt. Grid world environments are often used in many introductory reinforcement learning examples.
You can use three types of MDP environment.
Predefined grid world environments
Reinforcement Learning Toolbox provides three predefined grid world environment object types. For predefined environments, all states, actions, and rewards are already defined. You can use them to learn basic reinforcement learning concepts and gain familiarity with Reinforcement Learning Toolbox software features. For an introduction to predefined grid world environments, see Load Predefined Grid World Environments.
Custom grid world environments
You can create custom grid worlds of any size with your own custom rewards, state transitions, and obstacle configurations. Once you create a custom grid world environment, you can train and simulate agents with it as you do with a predefined environment.
For an introduction to custom grid worlds, see Create Custom Grid World Environments.
Custom Markov Decision Process (MDP) environments
You can also create custom generic MDP environments by supplying your own state and action sets. To create generic MDP environments, see
createMDPandrlMDPEnv.
Predefined Control System Environments
Control system environments are environments that represent dynamical systems in which state and observation typically belong to infinite (and uncountable) numerical vector spaces. Here, the state transition laws are deterministic and often derived by discretizing the dynamics of an underlying physical system that you want to model. Note that in these environments the action can still belong to a finite set.
Reinforcement Learning Toolbox provides several predefined control system environment objects that model dynamical systems such a double integrator or cart-pole system. In general each predefined environment comes in two versions, one with a discrete (finite) action space and the other with a continuous (infinite and uncountable) action space.
Environments that rely on an underlying Simulink® model for the calculation of the state transition, reward, and observation are called Simulink environments. Some of the predefined control system environments belong to this category.
Multiagent environments are environments in which you can train and simulate multiple agents together. Some of the predefined control system environments are multiagent environments.
You can use predefined control system environments to learn how to apply reinforcement learning to the control of physical systems, gain familiarity with Reinforcement Learning Toolbox software features, or test your own agents. For an introduction to predefined control system environments, see Load Predefined Control System Environments.
Custom Environments
You can create different types of custom environments. Once you create a custom environment, you can train and simulate agents as with any other environment.
For critical considerations on defining reward and observation signals in custom environments, see Define Reward and Observation Signals in Custom Environments.
You can create three different types of custom environment.
Custom function environments
Custom function environments rely (for the calculation of the state transition, reward, observation, and initial state) on custom
stepandresetMATLAB functions.For single-agent environments, once you define your action and observation specifications and write your custom step and reset functions, you use
rlFunctionEnvto return an environment object that can interact with your agent in the same way any other environment does.For an example on custom functions environments, see Create Custom Environment Using Step and Reset Functions.
You can also create two different kinds of custom multiagent function environments:
Multiagent environments with universal sample time, in which all agents execute in the same step.
Turn-based function environments, in which agents execute in turns. Specifically, the environment assigns execution to only one group of agents at a time, and the group executes when it is its turn to do so. For an example, see Train Agent to Play Turn-Based Game.
For both kinds of multiagent environments, the observation and action specifications are cell arrays of specification objects in which each element corresponds to one agent.
For custom multiagent function environments with universal sample time, use
rlMultiAgentFunctionEnvto return an environment object. For custom turn-based multiagent function environments, userlTurnBasedFunctionEnv.To specify options for training agents in multiagent environment, create and configure a
rlMultiAgentTrainingOptionsobject. Doing so allows you to specify, for example, whether different groups of agents are trained in a decentralized or centralized manner. In a group of agents subject to decentralized training, each agent collects its own set of experiences and learns from its own set of experiences. In a group of agents subject to centralized training, each agent shares its experiences with the other agents in the group and each agent in the group learns from the collective shared experiences.You can train and simulate your agents within a multiagent environment is using
trainandsim, respectively. You can visualize the training progress of all the agents using the Reinforcement Learning Training Manager.Custom template environments
Custom template environments are based on a modified class template.
To create a custom template environment, you use
rlCreateEnvTemplateto open a MATLAB script that contains a template class for an environment, then modify the template, specifying environment properties, required environment functions, and optional environment functions.While this process is more elaborate than just writing custom
stepandresetfunctions, it gives you more flexibility in adding properties or methods that might be needed for your application. For example, you can write a custom plot method to plot a visual representation of the environment at a given time.For an introduction to creating environments using a template, see Create Custom Environment from Class Template.
Custom Simulink environments
Custom Simulink environments are based on a Simulink model that you design.
You can also use Simulink to design multiagent environments. In particular, Simulink allows you to model environments with multi-rate execution, in which each agent may have its own execution rates.
For an introduction to creating custom Simulink environments, see Create Custom Simulink Environments.
Neural Network Environments
Neural network environments are custom environments that rely on a neural network for the calculation of the state transition. Here, state and observation belong to continuous spaces and the state transitions laws can be deterministic or stochastic.
Neural network environments can be used within model-based reinforcement learning agents, such as Model-Based Policy Optimization (MBPO) Agents.
For more information on how to create neural network environments, see rlNeuralNetworkEnvironment.
See Also
Functions
rlPredefinedEnv|getActionInfo|getObservationInfo|rlCreateEnvTemplate|validateEnvironment|rlSimulinkEnv|bus2RLSpec|createIntegratedEnv
Objects
rlNumericSpec|rlFiniteSetSpec|rlFunctionEnv|rlMultiAgentFunctionEnv|rlTurnBasedFunctionEnv|SimulinkEnvWithAgent|rlNeuralNetworkEnvironment
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)