sim
Simulate trained reinforcement learning agents within specified environment
Description
experience = sim(env,agents)
experience = sim(agents,env)
Examples
Simulate a reinforcement learning environment with an agent configured for that environment. For this example, load an environment and agent that are already configured. The environment is a discrete cart-pole environment created with rlPredefinedEnv. The agent is a policy gradient (rlPGAgent) agent. For more information about the environment and agent used in this example, see Train PG Agent with Custom Actor Network to Balance Discrete Cart-Pole.
rng(0) % for reproducibility load RLSimExample.mat env
env =
CartPoleDiscreteAction with properties:
Gravity: 9.8000
MassCart: 1
MassPole: 0.1000
Length: 0.5000
MaxForce: 10
Ts: 0.0200
ThetaThresholdRadians: 0.2094
XThreshold: 2.4000
RewardForNotFalling: 1
PenaltyForFalling: -5
State: [4×1 double]
agent
agent =
rlPGAgent with properties:
AgentOptions: [1×1 rl.option.rlPGAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlFiniteSetSpec]
SampleTime: 0.1000
UseGPUForLearning: 0
Typically, you train the agent using train and simulate the environment to test the performance of the trained agent. For this example, simulate the environment using the agent you loaded. Configure simulation options, specifying that the simulation run for 100 steps.
simOpts = rlSimulationOptions(MaxSteps=100);
For the predefined cart-pole environment used in this example, you can use plot to generate a visualization of the cart-pole system. When you simulate the environment, this plot updates automatically so that you can watch the system evolve during the simulation.
plot(env)
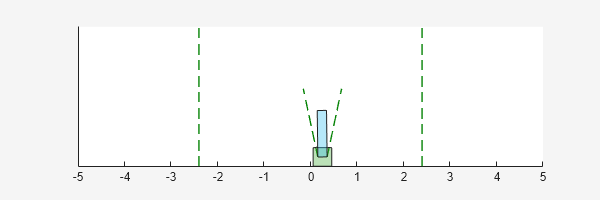
Simulate the environment.
experience = sim(env,agent,simOpts)
experience = struct with fields:
Observation: [1×1 struct]
Action: [1×1 struct]
Reward: [1×1 timeseries]
IsDone: [1×1 timeseries]
SimulationInfo: [1×1 rl.storage.SimulationStorage]
The output structure experience records the observations collected from the environment, the action and reward, and other data collected during the simulation. Each field contains a timeseries object or a structure of timeseries data objects. For instance, experience.Action is a timeseries containing the action imposed on the cart-pole system by the agent at each step of the simulation.
experience.Action
ans = struct with fields:
CartPoleAction: [1×1 timeseries]
Simulate an environment created for the Simulink® model used in the Train Multiple Agents to Perform Collaborative Task example.
Load the file containing the agents. For this example, load the agents that have been already trained using decentralized learning.
load decentralizedAgents.matCreate an environment for the rlCollaborativeTask Simulink model, which has two agent blocks. Because the agents used by the two blocks (agentA and agentB) are already in the workspace, you do not need to pass their observation and action specifications to create the environment.
env = rlSimulinkEnv( ... "rlCollaborativeTask", ... ["rlCollaborativeTask/Agent A","rlCollaborativeTask/Agent B"]);
It is good practice to specify a reset function for the environment such that agents start from random initial positions at the beginning of each episode. For an example, see the resetRobots function defined in Train Multiple Agents to Perform Collaborative Task. For this example, however, do not define a reset function.
Load the parameters that are needed by the rlCollaborativeTask Simulink model to run.
rlCollaborativeTaskParams
Simulate the agents against the environment, saving the experiences in xpr.
xpr = sim(env,[dcAgentA dcAgentB]);
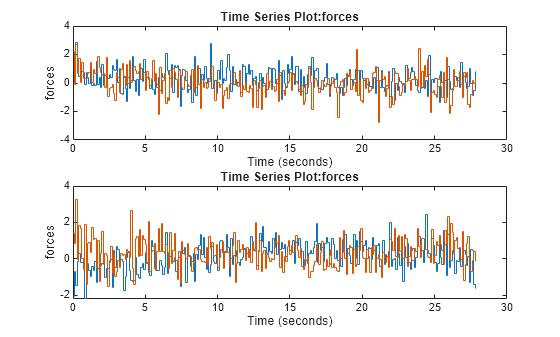
Plot actions of both agents.
subplot(2,1,1); plot(xpr(1).Action.forces) subplot(2,1,2); plot(xpr(2).Action.forces)
Input Arguments
Output Arguments
Version History
Introduced in R2019a