Implement an FFT on a Multicore Processor and an FPGA
This example shows you how to take advantage of a multicore processor target with FPGA acceleration by graphically partitioning a model. This example requires Simulink® Coder™ to generate multi-threaded code and HDL Coder™ to generate HDL code. You cannot generate HDL code on Macintosh systems.
Introduction
Several modern processors include multicore processors integrated with FPGA components to create high-performance applications. These require multicore and FPGA programming, including programming of parallel threads, HDL, and communication interfaces between the cores of the system. Simulink allows you to take advantage of these approaches by graphically partitioning your algorithms and by assigning the software generated from those partitions to threads on your processor and to modules on your FPGA. The example uses one application level model to generate one executable, consisting of multiple threads and HDL code, to take advantage of the hardware parallelism of the FPGA. This is illustrated in the figure below.
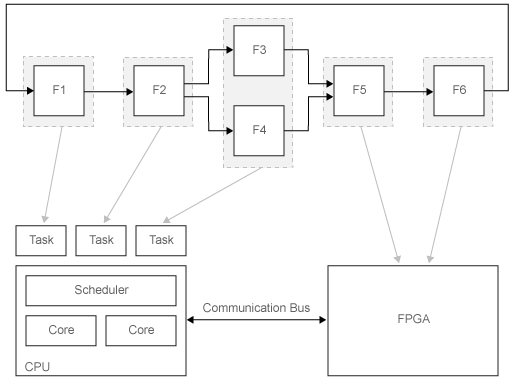
Example Model
Load the example model:
slexMulticoreFPGAExample

Architecture Definition
All concurrent execution settings for this model can be accessed in the Concurrent Execution dialog box (Configuration Parameters>Solvers>Configure Tasks).
The first step to implement our algorithm is to define structural elements of our target architecture. This includes structural elements of the hardware, such as the number and type of processing nodes (CPU, FPGA) and the communication channels (AXI, PCI).
This also includes software settings in the model's Configuration Parameters (e.g. System Target File, hardware Implementation, data transfer settings). In this example we have selected the pre-configured target architecture 'Sample architecture'. This architecture uses your desktop as a stand-in for the deployment process.

Partitioning and Mapping the Model
Partition the model to decide which functions run sequentially and which run concurrently.
The example model is partitioned explicitly, consisting of MATLAB System blocks, a Model block, an Atomic Subsystem and an Outport block. Explicit partitioning creates partitions based on these blocks at the root-level of the model. Implicit partitioning, on the other hand, creates partitions based on the block sample times and other scheduling constraints.
After partitioning the model, you can map partitions to CPU tasks and FPGA nodes. You can change the mapping for design space exploration, through the GUI or the API. During mapping, signals will be auto-mapped to channels.
You can change how the blocks are mapped to the threads and to the FPGA in the Concurrent Execution dialog box. For more information, see Optimize and Deploy on a Multicore Target.

Generate Multithreaded and HDL Code
Double-click on the 'Generate Code and Profile Report' button to generate multithreaded code. In this example, the host computer replaces the target environment. C code is generated for blocks mapped to processor tasks. This code is organized using threads native to the desktop machine. The code snippet shows how threads are created. In addition, HDL code is generated for blocks mapped to hardware nodes. The code snippet below illustrates how the module/entity is created in VHDL.
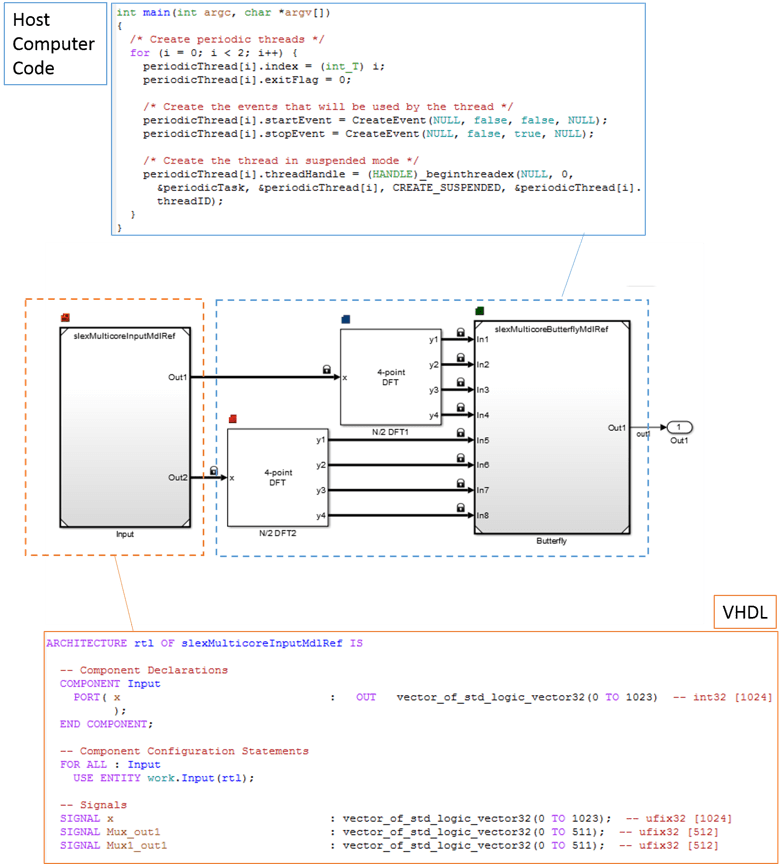
close_system('slexMulticoreFPGAExample',0);