fitcnb
Train multiclass naive Bayes model
Syntax
Description
Mdl = fitcnb(Tbl,ResponseVarName)Mdl), trained
by the predictors in table Tbl and class labels
in the variable Tbl.ResponseVarName.
Mdl = fitcnb(___,Name,Value)Name,Value pair arguments, using any
of the previous syntaxes. For example, you can specify a distribution
to model the data, prior probabilities for the classes, or the kernel
smoothing window bandwidth.
[
also returns Mdl,AggregateOptimizationResults] = fitcnb(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Note
For a list of supported syntaxes when the input variables are tall arrays, see Tall Arrays.
Examples
Load Fisher's iris data set.
load fisheriris
X = meas(:,3:4);
Y = species;
tabulate(Y) Value Count Percent
setosa 50 33.33%
versicolor 50 33.33%
virginica 50 33.33%
The software can classify data with more than two classes using naive Bayes methods.
Train a naive Bayes classifier. It is good practice to specify the class order.
Mdl = fitcnb(X,Y,'ClassNames',{'setosa','versicolor','virginica'})
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal'}
DistributionParameters: {3×2 cell}
Properties, Methods
Mdl is a trained ClassificationNaiveBayes classifier.
By default, the software models the predictor distribution within each class using a Gaussian distribution having some mean and standard deviation. Use dot notation to display the parameters of a particular Gaussian fit, e.g., display the fit for the first feature within setosa.
setosaIndex = strcmp(Mdl.ClassNames,'setosa');
estimates = Mdl.DistributionParameters{setosaIndex,1}estimates = 2×1
1.4620
0.1737
The mean is 1.4620 and the standard deviation is 0.1737.
Plot the Gaussian contours.
figure gscatter(X(:,1),X(:,2),Y); h = gca; cxlim = h.XLim; cylim = h.YLim; hold on Params = cell2mat(Mdl.DistributionParameters); Mu = Params(2*(1:3)-1,1:2); % Extract the means Sigma = zeros(2,2,3); for j = 1:3 Sigma(:,:,j) = diag(Params(2*j,:)).^2; % Create diagonal covariance matrix xlim = Mu(j,1) + 4*[-1 1]*sqrt(Sigma(1,1,j)); ylim = Mu(j,2) + 4*[-1 1]*sqrt(Sigma(2,2,j)); f = @(x,y) arrayfun(@(x0,y0) mvnpdf([x0 y0],Mu(j,:),Sigma(:,:,j)),x,y); fcontour(f,[xlim ylim]) % Draw contours for the multivariate normal distributions end h.XLim = cxlim; h.YLim = cylim; title('Naive Bayes Classifier -- Fisher''s Iris Data') xlabel('Petal Length (cm)') ylabel('Petal Width (cm)') legend('setosa','versicolor','virginica') hold off
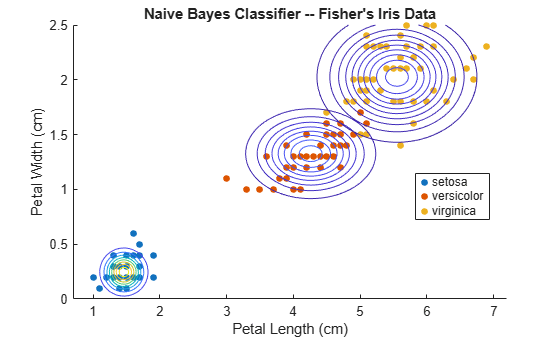
You can change the default distribution using the name-value pair argument 'DistributionNames'. For example, if some predictors are categorical, then you can specify that they are multivariate, multinomial random variables using 'DistributionNames','mvmn'.
Construct a naive Bayes classifier for Fisher's iris data set. Also, specify prior probabilities during training.
Load Fisher's iris data set.
load fisheriris X = meas; Y = species; classNames = {'setosa','versicolor','virginica'}; % Class order
X is a numeric matrix that contains four measurements for 150 irises. Y is a cell array of character vectors that contains the corresponding iris species.
By default, the prior class probability distribution is the relative frequency distribution of the classes in the data set. In this case the prior probability is 33% for each species. However, suppose you know that in the population 50% of the irises are setosa, 20% are versicolor, and 30% are virginica. You can incorporate this information by specifying this distribution as a prior probability during training.
Train a naive Bayes classifier. Specify the class order and prior class probability distribution.
prior = [0.5 0.2 0.3]; Mdl = fitcnb(X,Y,'ClassNames',classNames,'Prior',prior)
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl is a trained ClassificationNaiveBayes classifier, and some of its properties appear in the Command Window. The software treats the predictors as independent given a class, and, by default, fits them using normal distributions.
The naive Bayes algorithm does not use the prior class probabilities during training. Therefore, you can specify prior class probabilities after training using dot notation. For example, suppose that you want to see the difference in performance between a model that uses the default prior class probabilities and a model that uses different prior.
Create a new naive Bayes model based on Mdl, and specify that the prior class probability distribution is an empirical class distribution.
defaultPriorMdl = Mdl;
FreqDist = cell2table(tabulate(Y));
defaultPriorMdl.Prior = FreqDist{:,3};The software normalizes the prior class probabilities to sum to 1.
Estimate the cross-validation error for both models using 10-fold cross-validation.
rng(1); % For reproducibility
defaultCVMdl = crossval(defaultPriorMdl);
defaultLoss = kfoldLoss(defaultCVMdl)defaultLoss = 0.0533
CVMdl = crossval(Mdl); Loss = kfoldLoss(CVMdl)
Loss = 0.0340
Mdl performs better than defaultPriorMdl.
Load Fisher's iris data set.
load fisheriris
X = meas;
Y = species;Train a naive Bayes classifier using every predictor. It is good practice to specify the class order.
Mdl1 = fitcnb(X,Y,... 'ClassNames',{'setosa','versicolor','virginica'})
Mdl1 =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl1.DistributionParameters
ans=3×4 cell array
{2×1 double} {2×1 double} {2×1 double} {2×1 double}
{2×1 double} {2×1 double} {2×1 double} {2×1 double}
{2×1 double} {2×1 double} {2×1 double} {2×1 double}
Mdl1.DistributionParameters{1,2}ans = 2×1
3.4280
0.3791
By default, the software models the predictor distribution within each class as a Gaussian with some mean and standard deviation. There are four predictors and three class levels. Each cell in Mdl1.DistributionParameters corresponds to a numeric vector containing the mean and standard deviation of each distribution, e.g., the mean and standard deviation for setosa iris sepal widths are 3.4280 and 0.3791, respectively.
Estimate the confusion matrix for Mdl1.
isLabels1 = resubPredict(Mdl1); ConfusionMat1 = confusionchart(Y,isLabels1);
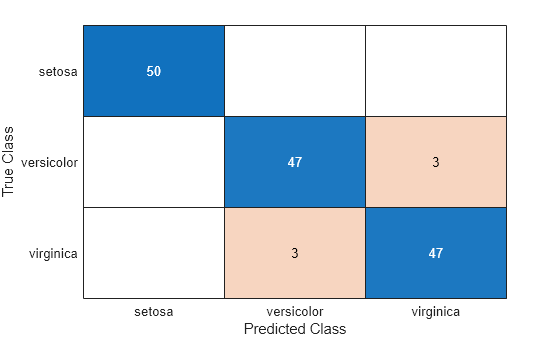
Element (j, k) of the confusion matrix chart represents the number of observations that the software classifies as k, but are truly in class j according to the data.
Retrain the classifier using the Gaussian distribution for predictors 1 and 2 (the sepal lengths and widths), and the default normal kernel density for predictors 3 and 4 (the petal lengths and widths).
Mdl2 = fitcnb(X,Y,... 'DistributionNames',{'normal','normal','kernel','kernel'},... 'ClassNames',{'setosa','versicolor','virginica'}); Mdl2.DistributionParameters{1,2}
ans = 2×1
3.4280
0.3791
The software does not train parameters to the kernel density. Rather, the software chooses an optimal width. However, you can specify a width using the 'Width' name-value pair argument.
Estimate the confusion matrix for Mdl2.
isLabels2 = resubPredict(Mdl2); ConfusionMat2 = confusionchart(Y,isLabels2);
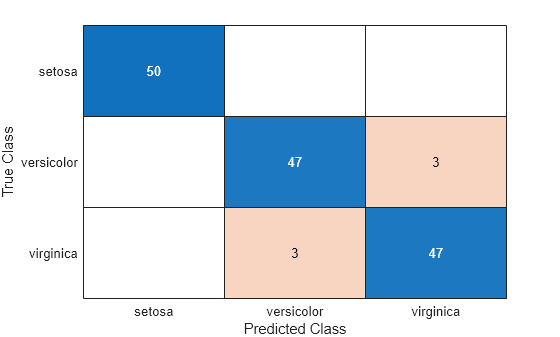
Based on the confusion matrices, the two classifiers perform similarly in the training sample.
Load Fisher's iris data set.
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
Train and cross-validate a naive Bayes classifier using the default options and k-fold cross-validation. It is good practice to specify the class order.
CVMdl1 = fitcnb(X,Y,... 'ClassNames',{'setosa','versicolor','virginica'},... 'CrossVal','on');
By default, the software models the predictor distribution within each class as a Gaussian with some mean and standard deviation. CVMdl1 is a ClassificationPartitionedModel model.
Create a default naive Bayes binary classifier template, and train an error-correcting, output codes multiclass model.
t = templateNaiveBayes(); CVMdl2 = fitcecoc(X,Y,'CrossVal','on','Learners',t);
CVMdl2 is a ClassificationPartitionedECOC model. You can specify options for the naive Bayes binary learners using the same name-value pair arguments as for fitcnb.
Compare the out-of-sample k-fold classification error (proportion of misclassified observations).
classErr1 = kfoldLoss(CVMdl1,'LossFun','ClassifErr')
classErr1 = 0.0533
classErr2 = kfoldLoss(CVMdl2,'LossFun','ClassifErr')
classErr2 = 0.0467
Mdl2 has a lower generalization error.
Some spam filters classify an incoming email as spam based on how many times a word or punctuation (called tokens) occurs in an email. The predictors are the frequencies of particular words or punctuations in an email. Therefore, the predictors compose multinomial random variables.
This example illustrates classification using naive Bayes and multinomial predictors.
Create Training Data
Suppose you observed 1000 emails and classified them as spam or not spam. Do this by randomly assigning -1 or 1 to y for each email.
n = 1000; % Sample size rng(1); % For reproducibility Y = randsample([-1 1],n,true); % Random labels
To build the predictor data, suppose that there are five tokens in the vocabulary, and 20 observed tokens per email. Generate predictor data from the five tokens by drawing random, multinomial deviates. The relative frequencies for tokens corresponding to spam emails should differ from emails that are not spam.
tokenProbs = [0.2 0.3 0.1 0.15 0.25;... 0.4 0.1 0.3 0.05 0.15]; % Token relative frequencies tokensPerEmail = 20; % Fixed for convenience X = zeros(n,5); X(Y == 1,:) = mnrnd(tokensPerEmail,tokenProbs(1,:),sum(Y == 1)); X(Y == -1,:) = mnrnd(tokensPerEmail,tokenProbs(2,:),sum(Y == -1));
Train the Classifier
Train a naive Bayes classifier. Specify that the predictors are multinomial.
Mdl = fitcnb(X,Y,'DistributionNames','mn');
Mdl is a trained ClassificationNaiveBayes classifier.
Assess the in-sample performance of Mdl by estimating the misclassification error.
isGenRate = resubLoss(Mdl,'LossFun','ClassifErr')
isGenRate = 0.0320
The in-sample misclassification rate is 2%.
Create New Data
Randomly generate deviates that represent a new batch of emails.
newN = 500; newY = randsample([-1 1],newN,true); newX = zeros(newN,5); newX(newY == 1,:) = mnrnd(tokensPerEmail,tokenProbs(1,:),... sum(newY == 1)); newX(newY == -1,:) = mnrnd(tokensPerEmail,tokenProbs(2,:),... sum(newY == -1));
Assess Classifier Performance
Classify the new emails using the trained naive Bayes classifier Mdl, and determine whether the algorithm generalizes.
oosGenRate = loss(Mdl,newX,newY)
oosGenRate = 0.0160
The out-of-sample misclassification rate is 2.6% indicating that the classifier generalizes fairly well.
This example shows how to use the OptimizeHyperparameters name-value pair to minimize cross-validation loss in a naive Bayes classifier using fitcnb. The example uses Fisher's iris data.
Load Fisher's iris data.
load fisheriris X = meas; Y = species; classNames = {'setosa','versicolor','virginica'};
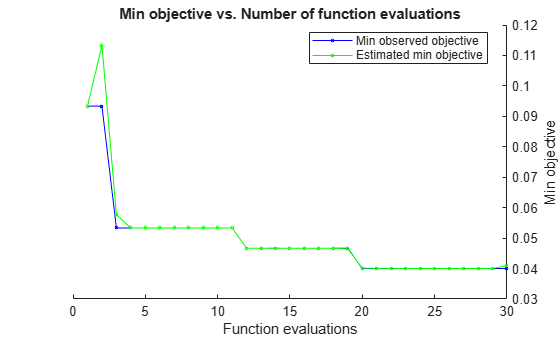
Optimize the classification using the 'auto' parameters.
For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
rng default Mdl = fitcnb(X,Y,'ClassNames',classNames,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName',... 'expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Distribution-| Width | Standardize |
| | result | | runtime | (observed) | (estim.) | Names | | |
|====================================================================================================================|
| 1 | Best | 0.093333 | 0.71489 | 0.093333 | 0.093333 | kernel | 5.6939 | false |
| 2 | Accept | 0.13333 | 0.19252 | 0.093333 | 0.11333 | kernel | 94.849 | true |
| 3 | Best | 0.053333 | 0.10109 | 0.053333 | 0.05765 | normal | - | - |
| 4 | Accept | 0.053333 | 0.036485 | 0.053333 | 0.053336 | normal | - | - |
| 5 | Accept | 0.26667 | 0.12204 | 0.053333 | 0.053338 | kernel | 0.001001 | true |
| 6 | Accept | 0.093333 | 0.12017 | 0.053333 | 0.053337 | kernel | 10.043 | false |
| 7 | Accept | 0.26667 | 0.10049 | 0.053333 | 0.05334 | kernel | 0.0010132 | false |
| 8 | Accept | 0.093333 | 0.095368 | 0.053333 | 0.053338 | kernel | 985.05 | false |
| 9 | Accept | 0.13333 | 0.10579 | 0.053333 | 0.053338 | kernel | 993.63 | true |
| 10 | Accept | 0.053333 | 0.041079 | 0.053333 | 0.053336 | normal | - | - |
| 11 | Accept | 0.053333 | 0.030628 | 0.053333 | 0.053336 | normal | - | - |
| 12 | Best | 0.046667 | 0.098326 | 0.046667 | 0.046679 | kernel | 0.30205 | true |
| 13 | Accept | 0.11333 | 0.10419 | 0.046667 | 0.046685 | kernel | 1.3021 | true |
| 14 | Accept | 0.053333 | 0.089902 | 0.046667 | 0.046695 | kernel | 0.10521 | true |
| 15 | Accept | 0.046667 | 0.091559 | 0.046667 | 0.046677 | kernel | 0.25016 | false |
| 16 | Accept | 0.06 | 0.099669 | 0.046667 | 0.046686 | kernel | 0.58328 | false |
| 17 | Accept | 0.046667 | 0.10086 | 0.046667 | 0.046656 | kernel | 0.07969 | false |
| 18 | Accept | 0.093333 | 0.090954 | 0.046667 | 0.046654 | kernel | 131.33 | false |
| 19 | Accept | 0.046667 | 0.091427 | 0.046667 | 0.04648 | kernel | 0.13384 | false |
| 20 | Best | 0.04 | 0.089659 | 0.04 | 0.040132 | kernel | 0.19525 | true |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Distribution-| Width | Standardize |
| | result | | runtime | (observed) | (estim.) | Names | | |
|====================================================================================================================|
| 21 | Accept | 0.04 | 0.092843 | 0.04 | 0.040066 | kernel | 0.19458 | true |
| 22 | Accept | 0.04 | 0.089218 | 0.04 | 0.040043 | kernel | 0.19601 | true |
| 23 | Accept | 0.04 | 0.15414 | 0.04 | 0.040031 | kernel | 0.19412 | true |
| 24 | Accept | 0.10667 | 0.1179 | 0.04 | 0.040018 | kernel | 0.0084391 | true |
| 25 | Accept | 0.073333 | 0.10541 | 0.04 | 0.040022 | kernel | 0.02769 | false |
| 26 | Accept | 0.04 | 0.096549 | 0.04 | 0.04002 | kernel | 0.2037 | true |
| 27 | Accept | 0.13333 | 0.087331 | 0.04 | 0.040021 | kernel | 12.501 | true |
| 28 | Accept | 0.11333 | 0.086757 | 0.04 | 0.040006 | kernel | 0.0048728 | false |
| 29 | Accept | 0.1 | 0.084907 | 0.04 | 0.039993 | kernel | 0.028653 | true |
| 30 | Accept | 0.046667 | 0.084372 | 0.04 | 0.041008 | kernel | 0.18725 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 11.3082 seconds
Total objective function evaluation time: 3.5165
Best observed feasible point:
DistributionNames Width Standardize
_________________ _______ ___________
kernel 0.19525 true
Observed objective function value = 0.04
Estimated objective function value = 0.041117
Function evaluation time = 0.089659
Best estimated feasible point (according to models):
DistributionNames Width Standardize
_________________ ______ ___________
kernel 0.2037 true
Estimated objective function value = 0.041008
Estimated function evaluation time = 0.099426
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
DistributionNames: {'kernel' 'kernel' 'kernel' 'kernel'}
DistributionParameters: {3×4 cell}
Kernel: {'normal' 'normal' 'normal' 'normal'}
Support: {'unbounded' 'unbounded' 'unbounded' 'unbounded'}
Width: [3×4 double]
Mu: [5.8433 3.0573 3.7580 1.1993]
Sigma: [0.8281 0.4359 1.7653 0.7622]
Properties, Methods
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
For classifying count-based data, such as the bag-of-tokens model, use the multinomial distribution (e.g., set
'DistributionNames','mn').After training a model, you can generate C/C++ code that predicts labels for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
If predictor variable
jhas a conditional normal distribution (see theDistributionNamesname-value argument), the software fits the distribution to the data by computing the class-specific weighted mean and the unbiased estimate of the weighted standard deviation. For each class k:The weighted mean of predictor j is
where wi is the weight for observation i. The software normalizes weights within a class such that they sum to the prior probability for that class.
The unbiased estimator of the weighted standard deviation of predictor j is
where z1|k is the sum of the weights within class k and z2|k is the sum of the squared weights within class k.
If all predictor variables compose a conditional multinomial distribution (you specify
'DistributionNames','mn'), the software fits the distribution using the bag-of-tokens model. The software stores the probability that tokenjappears in classkin the propertyDistributionParameters{. Using additive smoothing [2], the estimated probability isk,j}where:
which is the weighted number of occurrences of token j in class k.
nk is the number of observations in class k.
is the weight for observation i. The software normalizes weights within a class such that they sum to the prior probability for that class.
which is the total weighted number of occurrences of all tokens in class k.
If predictor variable
jhas a conditional multivariate multinomial distribution:The software collects a list of the unique levels, stores the sorted list in
CategoricalLevels, and considers each level a bin. Each predictor/class combination is a separate, independent multinomial random variable.For each class
k, the software counts instances of each categorical level using the list stored inCategoricalLevels{.j}The software stores the probability that predictor
j, in classk, has level L in the propertyDistributionParameters{, for all levels ink,j}CategoricalLevels{. Using additive smoothing [2], the estimated probability isj}where:
which is the weighted number of observations for which predictor j equals L in class k.
nk is the number of observations in class k.
if xij = L, 0 otherwise.
is the weight for observation i. The software normalizes weights within a class such that they sum to the prior probability for that class.
mj is the number of distinct levels in predictor j.
mk is the weighted number of observations in class k.
If you specify the
Cost,Prior, andWeightsname-value arguments, the output model object stores the specified values in theCost,Prior, andWproperties, respectively. TheCostproperty stores the user-specified cost matrix as is. ThePriorandWproperties store the prior probabilities and observation weights, respectively, after normalization. For details, see Misclassification Cost Matrix, Prior Probabilities, and Observation Weights.The software uses the
Costproperty for prediction, but not training. Therefore,Costis not read-only; you can change the property value by using dot notation after creating the trained model.
References
[1] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, Second Edition. NY: Springer, 2008.