manova
Description
A manova object contains the results of a one-, two-, or N-way
MANOVA. Use the properties of a manova object to determine if the vector of
means in a set of response data differs with respect to the values (levels) of a factor or
multiple factors. The object properties include information about the coefficient estimates,
MANOVA model fit to the response data, and factors used to perform the analysis. For more
information about MANOVA, see Multivariate Analysis of Variance for Repeated Measures.
Creation
Syntax
Description
maov = manova(tbl,ResponseVarNames)tbl as factors and response variables. The
ResponseVarNames argument specifies which variables contain the
response data.
maov = manova(tbl,formula)formula use only the variable names in
tbl.
maov = manova(___,Name=Value)
Input Arguments
Name-Value Arguments
Properties
Object Functions
barttest | Bartlett's test for multivariate analysis of variance (MANOVA) |
boxchart | Box chart (box plot) for multivariate analysis of variance (MANOVA) |
canonvars | Canonical variables |
coeftest | Linear hypothesis test on MANOVA model coefficients |
groupmeans | Mean response estimates for multivariate analysis of variance (MANOVA) |
multcompare | Multiple comparison of marginal means for multiple analysis of variance (MANOVA) |
plotprofile | Plot MANOVA response variable means with grouping |
stats | Multivariate analysis of variance (MANOVA) table |
Examples
Load the fisheriris data set.
load fisheririsThe column vector species contains three iris flower species: setosa, versicolor, and virginica. The matrix meas contains four types of measurements for the flower: the length and width of sepals and petals in centimeters.
Perform a one-way MANOVA to test the null hypothesis that the vector of means for the four measurements is the same across the three flower species.
maov = manova(species,meas)
maov =
1-way manova
Y1,Y2,Y3,Y4 ~ 1 + Factor1
Source DF TestStatistic Value F DFNumerator DFDenominator pValue
_______ ___ _____________ ______ ______ ___________ _____________ __________
Factor1 2 pillai 1.1919 53.466 8 290 9.7422e-53
Error 147
Total 149
Properties, Methods
maov is a one-way manova object that contains the results of the one-way MANOVA. The output displays the formula for the MANOVA model and a MANOVA table. In the formula, the flower measurements are represented by the terms Y1, Y2, Y3, and Y4. Factor1 represents the flower species. The MANOVA table contains the p-value for the Pillai's trace test statistic. The p-value indicates that enough evidence exists to reject the null hypothesis at the 95% confidence level, and that the iris species has an effect on at least one of the four measurements.
Load the carsmall data set.
load carsmallThe variable Model_Year contains data for the year a car was manufactured, and the variable Cylinders contains data for the number of engine cylinders in the car. The Acceleration and Displacement variables contain data for car acceleration and displacement.
Use the table function to create a table of factor values from the data in Model_Year and Cylinders.
tbl = table(Model_Year,Cylinders,VariableNames=["Year" "Cylinders"]);
Create a matrix of response variables from Acceleration and Displacement.
y = [Acceleration Displacement];
Perform a two-way MANOVA using the factor values in tbl and the response variables in y.
maov = manova(tbl,y)
maov =
2-way manova
Y1,Y2 ~ 1 + Year + Cylinders
Source DF TestStatistic Value F DFNumerator DFDenominator pValue
_________ __ _____________ ________ ______ ___________ _____________ __________
Year 2 pillai 0.084893 2.1056 4 190 0.081708
Cylinders 2 pillai 0.94174 42.27 4 190 2.5049e-25
Error 95
Total 99
Properties, Methods
maov is a two-way manova object that contains the results of the two-way MANOVA. The output displays the formula for the MANOVA model and a MANOVA table. In the formula, the car acceleration and displacement are represented by the variables Y1 and Y2, respectively. The MANOVA table contains a small p-value corresponding to the Cylinders term in the MANOVA model. The small p-value indicates that, at the 95% confidence level, enough evidence exists to conclude that Cylinders has a statistically significant effect on the mean response vector. Year has a p-value larger than 0.05, which indicates that not enough evidence exists to conclude that Year has a statistically significant effect on the mean response vector at the 95% confidence level.
Use the barttest function to determine the dimension of the space spanned by the mean response vectors corresponding to the factor Year.
barttest(maov,"Year")ans = 0
The output shows that the mean response vectors corresponding to Year span a point, indicating that they are not statistically different from each other. This result is consistent with the large p-value for Year.
Load the patients data set.
load patientsThe variables Systolic and Diastolic contain data for patient systolic and diastolic blood pressure. The variables Smoker and SelfAssessedHealthStatus contain data for patient smoking status and self-assessed heath status.
Use the table function to create a table of factor values from the data in Systolic, Diastolic, Smoker, and SelfAssessedHealthStatus.
tbl = table(Systolic,Diastolic,Smoker,SelfAssessedHealthStatus,VariableNames=["Systolic" "Diastolic" "Smoker" "SelfAssessed"]);
Perform a two-way MANOVA to test the null hypothesis that smoking status does not have a statistically significant effect on systolic and diastolic blood pressure, and the null hypothesis that self-assessed health status does not have an effect on systolic and diastolic blood pressure.
maov = manova(tbl,["Systolic" "Diastolic"])
maov =
2-way manova
Systolic,Diastolic ~ 1 + Smoker + SelfAssessed
Source DF TestStatistic Value F DFNumerator DFDenominator pValue
____________ __ _____________ ________ _______ ___________ _____________ __________
Smoker 1 pillai 0.67917 99.494 2 94 6.2384e-24
SelfAssessed 3 pillai 0.053808 0.87552 6 190 0.51392
Error 95
Total 99
Properties, Methods
maov is a manova object that contains the results of the two-way MANOVA. The small p-value for the Smoker term in the MANOVA model indicates that enough evidence exists to conclude that mean response vectors are statistically different across the factor values of Smoker. However, the large p-value for the SelfAssessed term indicates that not enough evidence exists to reject the null hypothesis that the mean response vectors are statistically the same across the values for SelfAssessed.
Calculate the marginal means for the values of the factor Smoker.
groupmeans(maov,"Smoker")ans=2×5 table
Smoker Mean SE Lower Upper
______ ______ _______ ______ ______
false 99.203 0.45685 98.296 100.11
true 109.45 0.62574 108.21 110.7
The output shows that the marginal mean for non-smokers is lower than the marginal mean for smokers.
Load the patients data set.
load patientsThe variables Systolic and Diastolic contain data for patient systolic and diastolic blood pressure. The variables Weight, Height, and Smoker contain data for patient weight, height, and smoking status.
Use the table function to create a table of factor values from the data in Systolic, Diastolic, Weight, Height, and Smoker.
tbl = table(Systolic,Diastolic,Smoker,Weight,Height,VariableNames=["Systolic" "Diastolic" "Smoker" "Weight" "Height"]);
Perform a three-way MANOVA to test the null hypothesis that smoking status does not have a statistically significant effect on systolic and diastolic blood pressure, and the null hypothesis that the interaction between weight and height does not have a statistically significant effect on systolic and diastolic blood pressure.
maov = manova(tbl,"Systolic,Diastolic ~ Smoker + Weight*Height",CategoricalFactors=["Smoker"])
maov =
N-way manova
Systolic,Diastolic ~ 1 + Smoker + Weight*Height
Source DF TestStatistic Value F DFNumerator DFDenominator pValue
_____________ __ _____________ ________ _______ ___________ _____________ __________
Smoker 1 pillai 0.66141 91.809 2 94 7.8511e-23
Weight 1 pillai 0.020516 0.98446 2 94 0.37746
Height 1 pillai 0.012788 0.6088 2 94 0.54613
Weight:Height 1 pillai 0.019438 0.93169 2 94 0.39749
Error 95
Total 99
Properties, Methods
maov is a manova object that contains the results of the three-way MANOVA. The small p-value for the Smoker term in the MANOVA model indicates that enough evidence exists to conclude that mean response vectors are statistically different across the factor values of Smoker. However, the large p-value for the Weight:Height term indicates that not enough evidence exists to reject the null hypothesis that the mean response vectors are not statistically different across the combinations of the values for weight and height.
Display a profile plot of the means for the values of Smoker.
plotprofile(maov,"Smoker")
legend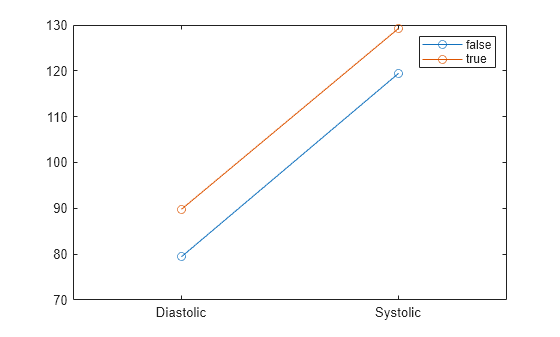
The plot shows that the mean systolic and diastolic blood pressure values are higher for smokers than non-smokers.
More About
Alternative Functionality
The manova1 function returns the output of the barttest object function, and a subset of the manova object properties. manova1 is limited to one-way MANOVA.
References
[1] Krzanowski, Wojtek. J. Principles of Multivariate Analysis: A User's Perspective. New York: Oxford University Press, 1988.
[2] Morrison, Donald F. Multivariate Statistical Methods. 2nd ed, McGraw-Hill, 1976.
Version History
Introduced in R2023b