RegressionGP
Gaussian process regression model
Description
RegressionGP is a Gaussian process regression (GPR) model.
You can train a GPR model, using fitrgp. Using the trained model,
you can
Predict responses for training data using
resubPredictor new predictor data usingpredict. You can also compute the prediction intervals.Compute the regression loss for training data using
resubLossor new data usingloss.
Creation
Create a RegressionGP object by using fitrgp.
Properties
Object Functions
compact | Reduce size of machine learning model |
crossval | Cross-validate machine learning model |
lime | Local interpretable model-agnostic explanations (LIME) |
loss | Regression error for Gaussian process regression model |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
postFitStatistics | Compute post-fit statistics for the exact Gaussian process regression model |
predict | Predict response of Gaussian process regression model |
resubLoss | Resubstitution regression loss |
resubPredict | Predict responses for training data using trained regression model |
shapley | Shapley values |
Examples
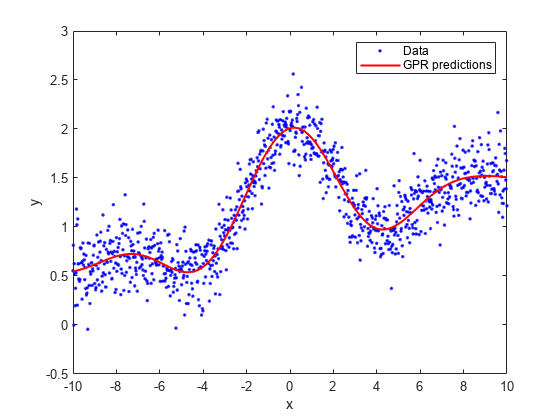
Train GPR Model and Plot Predictions
Generate sample data.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Fit a GPR model using a linear basis function and the exact fitting method to estimate the parameters. Also use the exact prediction method.
gprMdl = fitrgp(x,y,'Basis','linear',... 'FitMethod','exact','PredictMethod','exact');
Predict the response corresponding to the rows of x (resubstitution predictions) using the trained model.
ypred = resubPredict(gprMdl);
Plot the true response with the predicted values.
plot(x,y,'b.'); hold on; plot(x,ypred,'r','LineWidth',1.5); xlabel('x'); ylabel('y'); legend('Data','GPR predictions'); hold off
More About
Tips
You can access the properties of this class using dot notation. For example,
KernelInformationis a structure holding the kernel parameters and their names. Hence, to access the kernel function parameters of the trained modelgprMdl, usegprMdl.KernelInformation.KernelParameters.
Extended Capabilities
Version History
Introduced in R2015bSee Also
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)