plotPartialDependence
Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots
Syntax
Description
plotPartialDependence(
computes and plots the partial dependence between the predictor variables listed
in RegressionMdl,Vars)Vars and model predictions. In this syntax, the model
predictions are the responses predicted by using the regression model
RegressionMdl, which contains predictor data.
If you specify one variable in
Vars, the function creates a line plot of the partial dependence against the variable.If you specify two variables in
Vars, the function creates a surface plot of the partial dependence against the two variables.
plotPartialDependence(
computes and plots the partial dependence between the predictor variables listed
in ClassificationMdl,Vars,Labels)Vars and the scores for the classes specified in
Labels by using the classification model
ClassificationMdl, which contains predictor data.
If you specify one variable in
Vars, the function creates a line plot of the partial dependence against the variable for each class inLabels.If you specify two variables in
Vars, the function creates a surface plot of the partial dependence against the two variables. You must specify one class inLabels.
plotPartialDependence(
computes and plots the partial dependence between the predictor variables listed
in fun,Vars,Data)Vars and the outputs returned by the custom model
fun, using the predictor data Data.
If you specify one variable in
Vars, the function creates a line plot of the partial dependence against the variable for each column of the output returned byfun.If you specify two variables in
Vars, the function creates a surface plot of the partial dependence against the two variables. When you specify two variables,funmust return a column vector or you must specify which output column to use by setting theOutputColumnsname-value argument.
plotPartialDependence(___,
uses additional options specified by one or more name-value arguments. For
example, if you specify Name,Value)"Conditional","absolute", the
plotPartialDependence function creates a figure
including a PDP, a scatter plot of the selected predictor variable and predicted
responses or scores, and an ICE plot for each observation.
Examples
Train a regression tree using the carsmall data set, and create a PDP that shows the relationship between a feature and the predicted responses in the trained regression tree.
Load the carsmall data set.
load carsmallSpecify Weight, Cylinders, and Horsepower as the predictor variables (X), and MPG as the response variable (Y).
X = [Weight,Cylinders,Horsepower]; Y = MPG;
Train a regression tree using X and Y.
Mdl = fitrtree(X,Y);
View a graphical display of the trained regression tree.
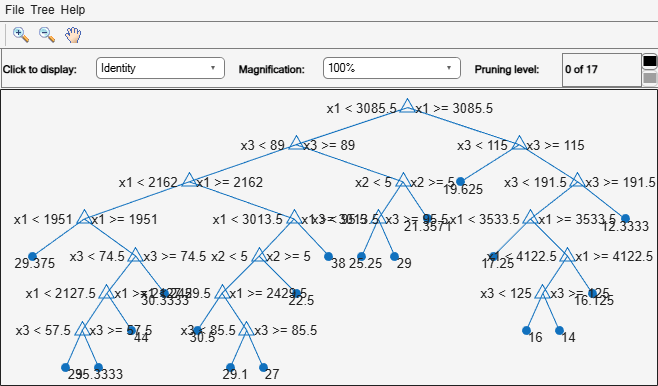
view(Mdl,"Mode","graph")
Create a PDP of the first predictor variable, Weight.
plotPartialDependence(Mdl,1)
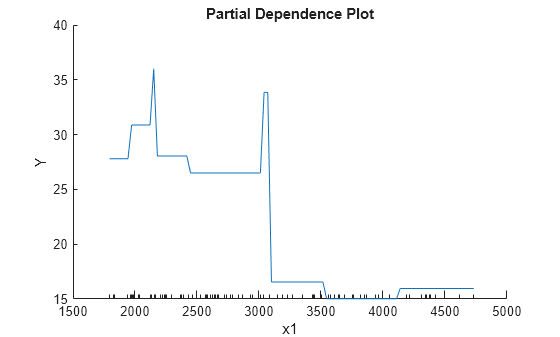
The plotted line represents averaged partial relationships between Weight (labeled as x1) and MPG (labeled as Y) in the trained regression tree Mdl. The x-axis minor ticks represent the unique values in x1.
The regression tree viewer shows that the first decision is whether x1 is smaller than 3085.5. The PDP also shows a large change near x1 = 3085.5. The tree viewer visualizes each decision at each node based on predictor variables. You can find several nodes split based on the values of x1, but determining the dependence of Y on x1 is not easy. However, the plotPartialDependence plots average predicted responses against x1, so you can clearly see the partial dependence of Y on x1.
The labels x1 and Y are the default values of the predictor names and the response name. You can modify these names by specifying the name-value arguments PredictorNames and ResponseName when you train Mdl using fitrtree. You can also modify axis labels by using the xlabel and ylabel functions.
Train a naive Bayes classification model with the fisheriris data set, and create a PDP that shows the relationship between the predictor variable and the predicted scores (posterior probabilities) for multiple classes.
Load the fisheriris data set, which contains species (species) and measurements (meas) on sepal length, sepal width, petal length, and petal width for 150 iris specimens. The data set contains 50 specimens from each of three species: setosa, versicolor, and virginica.
load fisheririsTrain a naive Bayes classification model with species as the response and meas as predictors.
Mdl = fitcnb(meas,species);
Create a PDP of the scores predicted by Mdl for all three classes of species against the third predictor variable x3. Specify the class labels by using the ClassNames property of Mdl.
plotPartialDependence(Mdl,3,Mdl.ClassNames);
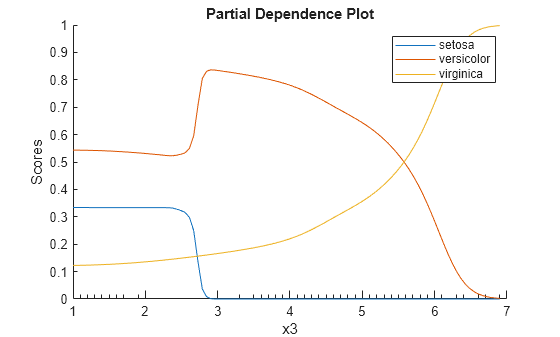
According to this model, the probability of virginica increases with x3. The probability of setosa is about 0.33, from where x3 is 0 to around 2.5, and then the probability drops to almost 0.
Train a Gaussian process regression model using generated sample data where a response variable includes interactions between predictor variables. Then, create ICE plots that show the relationship between a feature and the predicted responses for each observation.
Generate sample predictor data x1 and x2.
rng("default") % For reproducibility n = 200; x1 = rand(n,1)*2-1; x2 = rand(n,1)*2-1;
Generate response values that include interactions between x1 and x2.
Y = x1-2*x1.*(x2>0)+0.1*rand(n,1);
Create a Gaussian process regression model using [x1 x2] and Y.
Mdl = fitrgp([x1 x2],Y);
Create a figure including a PDP (red line) for the first predictor x1, a scatter plot (circle markers) of x1 and predicted responses, and a set of ICE plots (gray lines) by specifying Conditional as "centered".
plotPartialDependence(Mdl,1,"Conditional","centered")
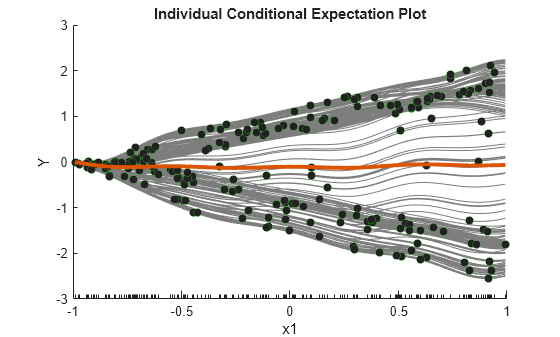
When Conditional is "centered", plotPartialDependence offsets plots so that all plots start from zero, which is helpful in examining the cumulative effect of the selected feature.
A PDP finds averaged relationships, so it does not reveal hidden dependencies especially when responses include interactions between features. However, the ICE plots clearly show two different dependencies of responses on x1.
Train an ensemble of classification models and create two PDPs, one using the training data set and the other using a new data set.
Load the census1994 data set, which contains US yearly salary data, categorized as <=50K or >50K, and several demographic variables.
load census1994Extract a subset of variables to analyze from the tables adultdata and adulttest.
X = adultdata(:,["age","workClass","education_num","marital_status","race", ... "sex","capital_gain","capital_loss","hours_per_week","salary"]); Xnew = adulttest(:,["age","workClass","education_num","marital_status","race", ... "sex","capital_gain","capital_loss","hours_per_week","salary"]);
Train an ensemble of classifiers with salary as the response and the remaining variables as predictors by using the function fitcensemble. For binary classification, fitcensemble aggregates 100 classification trees using the LogitBoost method.
Mdl = fitcensemble(X,"salary");Inspect the class names in Mdl.
Mdl.ClassNames
ans = 2×1 categorical
<=50K
>50K
Create a partial dependence plot of the scores predicted by Mdl for the second class of salary (>50K) against the predictor age using the training data.
plotPartialDependence(Mdl,"age",Mdl.ClassNames(2))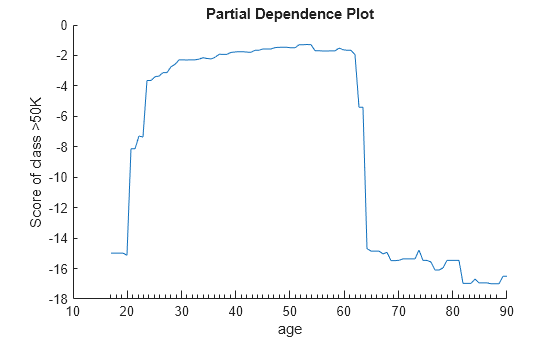
Create a PDP of the scores for class >50K against age using new predictor data from the table Xnew.
plotPartialDependence(Mdl,"age",Mdl.ClassNames(2),Xnew)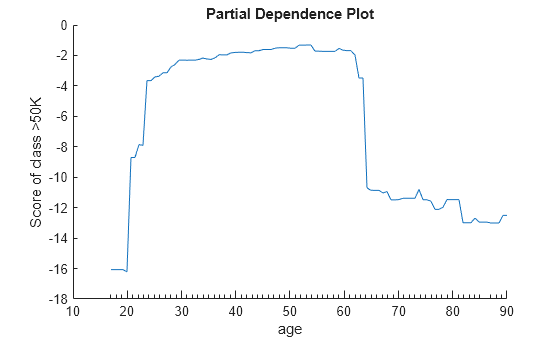
The two plots show similar shapes for the partial dependence of the predicted score of high salary (>50K) on age. Both plots indicate that the predicted score of high salary rises fast until the age of 30, then stays almost flat until the age of 60, and then drops fast. However, the plot based on the new data produces slightly higher scores for ages over 65.
Create a PDP to analyze relationships between predictors and anomaly scores for an isolationForest object. You cannot pass an isolationForest object directly to the plotPartialDependence function. Instead, define a custom function that returns anomaly scores for the object, and then pass the function to plotPartialDependence.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau.
load census1994census1994 contains the two data sets adultdata and adulttest.
Train an isolation forest model for adulttest. The function iforest returns an IsolationForest object.
rng("default") % For reproducibility Mdl = iforest(adulttest);
Define the custom function myAnomalyScores, which returns anomaly scores computed by the isanomaly function of IsolationForest; the custom function definition appears at the end of this example.
Create a PDP of the anomaly scores against the variable age for the adulttest data set. plotPartialDependence accepts a custom model in the form of a function handle. The function represented by the function handle must accept predictor data and return a column vector or matrix with one row for each observation. Specify the custom model as @(tbl)myAnomalyScores(Mdl,tbl) so that the custom function uses the trained model Mdl and accepts predictor data.
plotPartialDependence(@(tbl)myAnomalyScores(Mdl,tbl),"age",adulttest) xlabel("Age") ylabel("Anomaly Score")
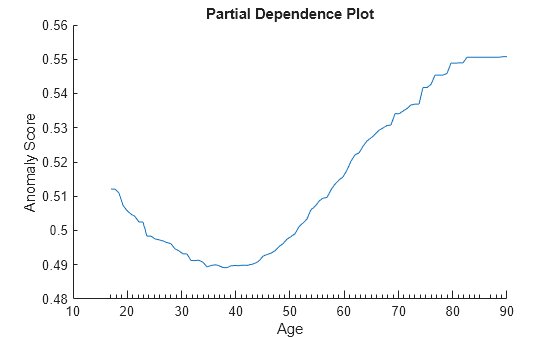
Custom Function myAnomalyScores
function scores = myAnomalyScores(Mdl,tbl) [~,scores] = isanomaly(Mdl,tbl); end
Train a regression ensemble using the carsmall data set, and create a PDP plot and ICE plots for each predictor variable using a new data set, carbig. Then, compare the figures to analyze the importance of predictor variables. Also, compare the results with the estimates of predictor importance returned by the predictorImportance function.
Load the carsmall data set.
load carsmallSpecify Weight, Cylinders, Horsepower, and Model_Year as the predictor variables (X), and MPG as the response variable (Y).
X = [Weight,Cylinders,Horsepower,Model_Year]; Y = MPG;
Train a regression ensemble using X and Y.
Mdl = fitrensemble(X,Y, ... "PredictorNames",["Weight","Cylinders","Horsepower","Model Year"], ... "ResponseName","MPG");
Determine the importance of the predictor variables by using the plotPartialDependence and predictorImportance functions. The plotPartialDependence function visualizes the relationships between a selected predictor and predicted responses. predictorImportance summarizes the importance of a predictor with a single value.
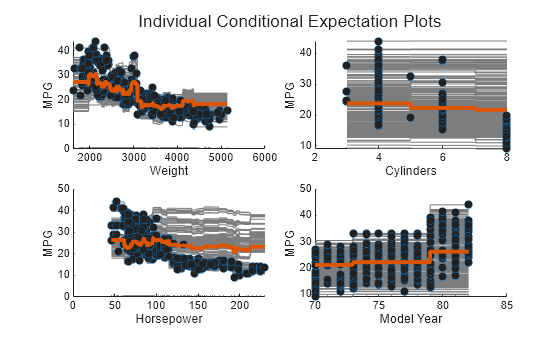
Create a figure including a PDP plot (red line) and ICE plots (gray lines) for each predictor by using plotPartialDependence and specifying "Conditional","absolute". Each figure also includes a scatter plot (circle markers) of the selected predictor and predicted responses. Also, load the carbig data set and use it as new predictor data, Xnew. When you provide Xnew, the plotPartialDependence function uses Xnew instead of the predictor data in Mdl.
load carbig Xnew = [Weight,Cylinders,Horsepower,Model_Year]; figure t = tiledlayout(2,2,"TileSpacing","compact"); title(t,"Individual Conditional Expectation Plots") for i = 1 : 4 nexttile plotPartialDependence(Mdl,i,Xnew,"Conditional","absolute") title("") end
Compute estimates of predictor importance by using predictorImportance. This function sums changes in the mean squared error (MSE) due to splits on every predictor, and then divides the sum by the number of branch nodes.
imp = predictorImportance(Mdl); figure bar(imp) title("Predictor Importance Estimates") ylabel("Estimates") xlabel("Predictors") ax = gca; ax.XTickLabel = Mdl.PredictorNames;
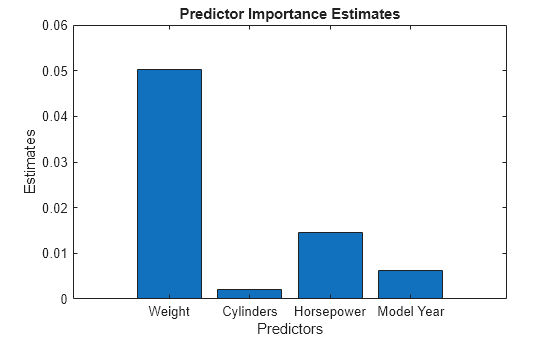
The variable Weight has the most impact on MPG according to predictor importance. The PDP of Weight also shows that MPG has high partial dependence on Weight. The variable Cylinders has the least impact on MPG according to predictor importance. The PDP of Cylinders also shows that MPG does not change much depending on Cylinders.
Train a generalized additive model (GAM) with both linear and interaction terms for predictors. Then, create a PDP with both linear and interaction terms and a PDP with only linear terms. Specify whether to include interaction terms when creating the PDPs.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereTrain a GAM using the predictors X and class labels Y. A recommended practice is to specify the class names. Specify to include the 10 most important interaction terms.
Mdl = fitcgam(X,Y,"ClassNames",{'b','g'},"Interactions",10);
Mdl is a ClassificationGAM model object.
List the interaction terms in Mdl.
Mdl.Interactions
ans = 10×2
1 5
7 8
6 7
5 6
5 7
5 8
3 5
4 7
1 7
4 5
Each row of Interactions represents one interaction term and contains the column indexes of the predictor variables for the interaction term.
Find the most frequent predictor in the interaction terms.
mode(Mdl.Interactions,"all")ans = 5
The most frequent predictor in the interaction terms is the 5th predictor (x5). Create PDPs for the 5th predictor. To exclude interaction terms from the computation, specify "IncludeInteractions",false for the second PDP.
plotPartialDependence(Mdl,5,Mdl.ClassNames(1)) hold on plotPartialDependence(Mdl,5,Mdl.ClassNames(1),"IncludeInteractions",false) grid on legend("Linear and interaction terms","Linear terms only") title("PDPs of Posterior Probabilities for 5th Predictor") hold off
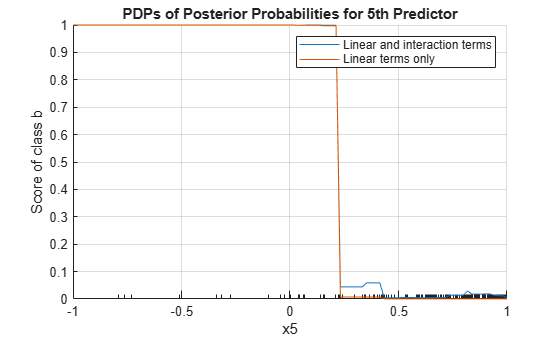
The plot shows that the partial dependence of the scores (posterior probabilities) on x5 varies depending on whether the model includes the interaction terms, especially where x5 is between 0.2 and 0.45.
Train a support vector machine (SVM) regression model using the carsmall data set, and create a PDP for two predictor variables. Then, extract partial dependence estimates from the output of plotPartialDependence. Alternatively, you can get the partial dependence values by using the partialDependence function.
Load the carsmall data set.
load carsmallSpecify Weight, Cylinders, Displacement, and Horsepower as the predictor variables (Tbl).
Tbl = table(Weight,Cylinders,Displacement,Horsepower);
Construct an SVM regression model using Tbl and the response variable MPG. Use a Gaussian kernel function with an automatic kernel scale.
Mdl = fitrsvm(Tbl,MPG,"ResponseName","MPG", ... "CategoricalPredictors","Cylinders","Standardize",true, ... "KernelFunction","gaussian","KernelScale","auto");
Create a PDP that visualizes partial dependence of predicted responses (MPG) on the predictor variables Weight and Cylinders. Specify query points to compute the partial dependence for Weight by using the QueryPoints name-value argument. You cannot specify the QueryPoints value for Cylinders because it is a categorical variable. plotPartialDependence uses all categorical values.
pt = linspace(min(Weight),max(Weight),50)'; ax = plotPartialDependence(Mdl,["Weight","Cylinders"],"QueryPoints",{pt,[]}); view(140,30) % Modify the viewing angle
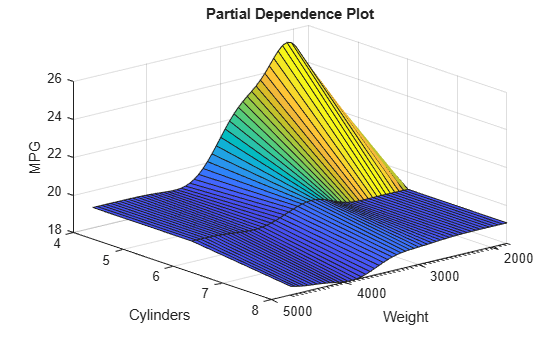
The PDP shows an interaction effect between Weight and Cylinders. The partial dependence of MPG on Weight changes depending on the value of Cylinders.
Extract the estimated partial dependence of MPG on Weight and Cylinders. The XData, YData, and ZData values of ax.Children are x-axis values (the first selected predictor values), y-axis values (the second selected predictor values), and z-axis values (the corresponding partial dependence values), respectively.
xval = ax.Children.XData; yval = ax.Children.YData; zval = ax.Children.ZData;
Alternatively, you can get the partial dependence values by using the partialDependence function.
[pd,x,y] = partialDependence(Mdl,["Weight","Cylinders"],"QueryPoints",{pt,[]});
pd contains the partial dependence values for the query points x and y.
If you specify Conditional as "absolute", plotPartialDependence creates a figure including a PDP, a scatter plot, and a set of ICE plots. ax.Children(1) and ax.Children(2) correspond to the PDP and scatter plot, respectively. The remaining elements of ax.Children correspond to the ICE plots. The XData and YData values of ax.Children(i) are x-axis values (the selected predictor values) and y-axis values (the corresponding partial dependence values), respectively.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
For both a regression model (RegressionMdl) and a classification
model (ClassificationMdl),
plotPartialDependence uses a predict
function to predict responses or scores. plotPartialDependence
chooses the proper predict function according to the model and runs
predict with its default settings. For details about each
predict function, see the predict functions in
the following two tables. If the specified model is a tree-based model (not including a
boosted ensemble of trees) and Conditional is
"none", then plotPartialDependence uses the
weighted traversal algorithm instead of the predict function. For
details, see Weighted Traversal Algorithm.
Regression Model Object
Classification Model Object
Alternative Functionality
partialDependencecomputes partial dependence without visualization. The function can compute partial dependence for two variables and multiple classes in one function call.
References
[3] Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. New York, NY: Springer New York, 2001.