MultinomialRegression
Description
MultinomialRegression is a fitted multinomial regression model
object. A multinomial regression model describes the relationship between predictors and a
response that has a finite set of values.
Use the properties of a MultinomialRegression object to investigate a
fitted multinomial regression model. The object properties include information about
coefficient estimates, summary statistics, and the data used to fit the model. Use the object
functions to predict responses, and to evaluate and visualize the multinomial regression
model.
Creation
Create a MultinomialRegression model object with specified parameter
values by using fitmnr.
Properties
Object Functions
coefCI | Confidence intervals for coefficient estimates of multinomial regression model |
coefTest | Linear hypothesis test on multinomial regression model coefficients |
feval | Predict responses of multinomial regression model using one input for each predictor |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
plotResiduals | Plot residuals of multinomial regression model |
plotSlice | Plot of slices through fitted multinomial regression surface |
predict | Predict responses of multinomial regression model |
random | Generate random responses from fitted multinomial regression model |
testDeviance | Deviance test for multinomial regression model |
Examples
Load the fisheriris sample data set.
load fisheririsThe column vector species contains iris flowers of three different species: setosa, versicolor, virginica. The matrix meas contains four types of measurements for the flower: the length and width of sepals and petals in centimeters.
Fit a multinomial regression model to predict the iris flower species using the measurements. Display the results of the fit using the Coefficients property of the fitted model.
MnrModel = fitmnr(meas,species); MnrModel.Coefficients
ans=10×4 table
Value SE tStat pValue
_______ ______ _______ __________
(Intercept_setosa) 2018.4 12.404 162.72 0
x1_setosa 673.85 3.5783 188.32 0
x2_setosa -568.2 3.176 -178.9 0
x3_setosa -516.44 3.5403 -145.87 0
x4_setosa -2760.9 7.1203 -387.75 0
(Intercept_versicolor) 42.638 5.2719 8.0878 6.0776e-16
x1_versicolor 2.4652 1.1228 2.1956 0.028124
x2_versicolor 6.6809 1.4789 4.5176 6.2559e-06
x3_versicolor -9.4294 1.2934 -7.2906 3.086e-13
x4_versicolor -18.286 2.0967 -8.7214 2.7476e-18
MnrModel is a multinomial regression model object that contains the results of fitting a nominal multinomial regression model to the data. The Coefficients property contains coefficient statistics for each predictor in meas. The small p-values in the column pValue indicate that all coefficients are statistically significant at the 95% confidence level. fitmnr sorts the categories in species in order of their first appearance. The last category is the default reference category.
To display the sorted names of the response variable categories, use the ClassNames property of MnrModel.
MnrModel.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
The output shows that the last category, 'virginica', is the reference category by default.
To get 95% confidence intervals for the fitted coefficient estimates, call the object function coefCI.
coefCI(MnrModel)
ans = 10×2
103 ×
1.9940 2.0428
0.6668 0.6809
-0.5745 -0.5620
-0.5234 -0.5095
-2.7749 -2.7469
0.0323 0.0530
0.0003 0.0047
0.0038 0.0096
-0.0120 -0.0069
-0.0224 -0.0142
The output shows 95% confidence intervals for the 10 coefficients in the Value column of the Coefficients table. None of the confidence intervals cross zero, confirming that all coefficients affect the log odds at the 95% confidence level.
Load the fisheriris sample data set.
load fisheririsThe column vector species contains three iris flowers species: setosa, versicolor, and virginica. The matrix meas contains four types of measurements for the flower: the length and width of sepals and petals in centimeters.
Divide the species and measurement data into training and test data by using the cvpartition function. Get the indices of the training data rows by using the training function.
n = length(species);
partition = cvpartition(n,'Holdout',0.05);
idx_train = training(partition);Create training data by using the indices of the training data rows to create a matrix of measurements and a vector of species labels.
meastrain = meas(idx_train,:); speciestrain = species(idx_train,:);
Fit a multinomial regression model using the training data.
mdl = fitmnr(meastrain,speciestrain)
mdl =
Multinomial regression with nominal responses
Value SE tStat pValue
_______ ______ ________ __________
(Intercept_setosa) 86.297 12.541 6.881 5.9436e-12
x1_setosa -1.0653 3.5795 -0.29761 0.766
x2_setosa 23.849 3.1238 7.6347 2.2637e-14
x3_setosa -27.273 3.5009 -7.7903 6.6846e-15
x4_setosa -59.644 7.0214 -8.4947 1.9852e-17
(Intercept_versicolor) 42.637 5.2214 8.1659 3.1906e-16
x1_versicolor 2.4652 1.1263 2.1887 0.028619
x2_versicolor 6.6808 1.474 4.5325 5.829e-06
x3_versicolor -9.4292 1.2946 -7.2837 3.248e-13
x4_versicolor -18.286 2.0833 -8.7775 1.671e-18
143 observations, 276 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 302.0378, p-value = 1.5168e-60
mdl is a multinomial regression model object that contains the results of fitting a nominal multinomial regression model to the data. The table output shows coefficient statistics for each predictor in meas. By default, fitmnr uses virginica as the reference category.
Get the indices of the test data rows by using the test function. Create test data by using the indices of the test data rows to create a matrix of measurements and a vector of species labels.
idx_test = test(partition); meastest = meas(idx_test,:); speciestest = species(idx_test,:);
Predict the iris species for the measurements in meastest.
speciespredict = predict(mdl,meastest)
speciespredict = 7×1 cell
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'versicolor'}
{'versicolor'}
Compare the predictions in speciespredict with the category names in speciestest.
speciestest
speciestest = 7×1 cell
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'setosa' }
{'versicolor'}
{'versicolor'}
The output shows that the model accurately predicts the iris species for the measurements in meastest.
Load the carbig sample data set.
load carbig;The vectors Acceleration and Displacement contain data for car acceleration and displacement, respectively. The vector Cylinders contains data for the number of cylinders in each car engine.
Fit an ordinal multinomial regression model using Acceleration and Displacement as predictor variables and Cylinders as the response variable.
MnrModel = fitmnr([Acceleration,Displacement],Cylinders,Model="ordinal",... PredictorNames=["Acceleration" "Displacement"])
MnrModel =
Multinomial regression with ordinal responses
Value SE tStat pValue
_________ ________ _______ __________
(Intercept_3) 11.949 3.1817 3.7555 0.00017299
(Intercept_4) 27.08 4.9481 5.4727 4.4321e-08
(Intercept_5) 27.528 4.9738 5.5346 3.1195e-08
(Intercept_6) 45.346 7.8292 5.7919 6.9593e-09
Acceleration -0.063533 0.1041 -0.6103 0.54167
Displacement -0.16731 0.027885 -6 1.9726e-09
406 observations, 1618 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 786.5846, p-value = 1.5679e-171
MnrModel is a multinomial regression model object that contains the results of fitting an ordinal multinomial regression model to the data. The table output shows coefficient statistics for each predictor variable. The p-values in the column pValue indicate that there is not enough evidence to conclude that the coefficient for the Acceleration term is statistically significant. However, enough evidence exists to conclude that Displacement has a statistically significant effect at the 99% confidence level.
Display the possible quantities for car engine cylinders using the ClassNames property.
MnrModel.ClassNames
ans = 5×1
3
4
5
6
8
The last category in the output is the default reference category. The output shows that the reference category corresponds to cars with eight-cylinder engines.
Use plotSlice to plot stacked histograms of the probabilities of a car having each number of cylinders as the value of the predictor variable Displacement changes. By default, plotSlice fixes the value of Acceleration at its training data mean.
plotSlice(MnrModel,"stackedhist",PredictorToVary="Displacement") hold on lgd = legend; title(lgd, "Number of cylinders");
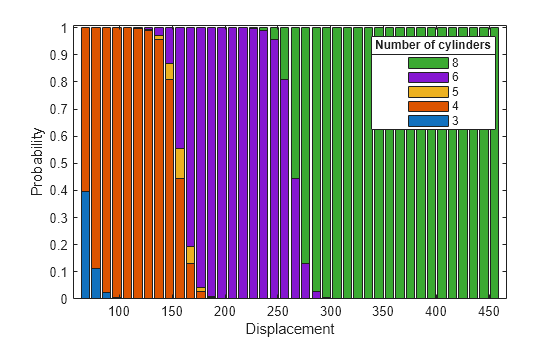
The plot shows that the probability of a car having more cylinders increases as the car displacement increases, which is consistent with the small p-value for the Displacement model term.
Load the carbig sample data set.
load carbig;The vectors Acceleration and Displacement contain data for car acceleration and displacement, respectively. The vector Cylinders contains data for the number of cylinders in each car engine.
Fit an ordinal multinomial regression model using Acceleration and Displacement as predictor variables and Cylinders as the response variable.
MnrModel = fitmnr([Acceleration,Displacement],Cylinders,Model="ordinal",... PredictorNames=["Acceleration" "Displacement"])
MnrModel =
Multinomial regression with ordinal responses
Value SE tStat pValue
_________ ________ _______ __________
(Intercept_3) 11.949 3.1817 3.7555 0.00017299
(Intercept_4) 27.08 4.9481 5.4727 4.4321e-08
(Intercept_5) 27.528 4.9738 5.5346 3.1195e-08
(Intercept_6) 45.346 7.8292 5.7919 6.9593e-09
Acceleration -0.063533 0.1041 -0.6103 0.54167
Displacement -0.16731 0.027885 -6 1.9726e-09
406 observations, 1618 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 786.5846, p-value = 1.5679e-171
MnrModel is a multinomial regression model object that contains the results of fitting an ordinal multinomial regression model to the data. The table output shows coefficient statistics for each of the predictor variable. The p-values in the column pValue indicate that there is not enough evidence to conclude that the coefficient for the Acceleration term is statistically significant. However, enough evidence exists to conclude that Displacement has a statistically significant effect at the 99% confidence level.
Display the possible quantities for car engine cylinders using the ClassNames property.
MnrModel.ClassNames
ans = 5×1
3
4
5
6
8
The reference category corresponds to cars with eight-cylinder engines.
Plot the partial dependence of the reference category probability on the Displacement predictor by using the plotPartialDependence object function.
plotPartialDependence(MnrModel,2,8)
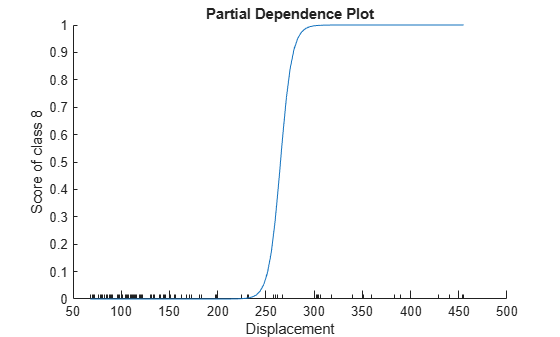
The plot shows that the probability of a car being in the reference category increases sharply when the value of Displacement reaches approximately 250.
More About
References
[1] Allison, P. D. "Measures of Fit for Logistic Regression." Statistical Horizons LLC and the University of Pennsylvania, 2014.
[2] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.
[3] Long, J. S. Regression Models for Categorical and Limited Dependent Variables. Sage Publications, 1997.
[4] Dobson, A. J., and A. G. Barnett. An Introduction to Generalized Linear Models. Chapman and Hall/CRC. Taylor & Francis Group, 2008.
Version History
Introduced in R2023a