ClassificationGAM
Generalized additive model (GAM) for binary classification
Description
A ClassificationGAM object is a
generalized additive model (GAM) object for binary classification. It is an
interpretable model that explains class scores (the logit of class probabilities) using a sum
of univariate and bivariate shape functions.
You can classify new observations by using the predict function,
and plot the effect of each shape function on the prediction (class score) for an observation
by using the plotLocalEffects
function. For the full list of object functions for ClassificationGAM, see
Object Functions.
Creation
Create a ClassificationGAM object by using fitcgam. You can
specify both linear terms and interaction terms for predictors to include univariate shape
functions (predictor trees) and bivariate shape functions (interaction trees) in a trained
model, respectively.
You can update a trained model by using resume or addInteractions.
The
resumefunction resumes training for the existing terms in a model.The
addInteractionsfunction adds interaction terms to a model that contains only linear terms.
Properties
Object Functions
Examples
Train a univariate generalized additive model, which contains linear terms for predictors. Then, interpret the prediction for a specified data instance by using the plotLocalEffects function.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereTrain a univariate GAM that identifies whether the radar return is bad ('b') or good ('g').
Mdl = fitcgam(X,Y)
Mdl =
ClassificationGAM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'logit'
Intercept: 2.2715
NumObservations: 351
Properties, Methods
Mdl is a ClassificationGAM model object. The model display shows a partial list of the model properties. To view the full list of properties, double-click the variable name Mdl in the Workspace. The Variables editor opens for Mdl. Alternatively, you can display the properties in the Command Window by using dot notation. For example, display the class order of Mdl.
classOrder = Mdl.ClassNames
classOrder = 2×1 cell
{'b'}
{'g'}
Classify the first observation of the training data, and plot the local effects of the terms in Mdl on the prediction.
label = predict(Mdl,X(1,:))
label = 1×1 cell array
{'g'}
plotLocalEffects(Mdl,X(1,:))
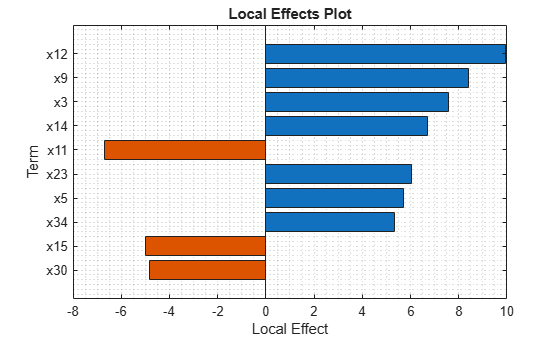
The predict function classifies the first observation X(1,:) as 'g'. The plotLocalEffects function creates a horizontal bar graph that shows the local effects of the 10 most important terms on the prediction. Each local effect value shows the contribution of each term to the classification score for 'g', which is the logit of the posterior probability that the classification is 'g' for the observation.
Train a generalized additive model that contains linear and interaction terms for predictors in three different ways:
Specify the interaction terms using the
formulainput argument.Specify the
'Interactions'name-value argument.Build a model with linear terms first and add interaction terms to the model by using the
addInteractionsfunction.
Load Fisher's iris data set. Create a table that contains observations for versicolor and virginica.
load fisheriris inds = strcmp(species,'versicolor') | strcmp(species,'virginica'); tbl = array2table(meas(inds,:),'VariableNames',["x1","x2","x3","x4"]); tbl.Y = species(inds,:);
Specify formula
Train a GAM that contains the four linear terms (x1, x2, x3, and x4) and two interaction terms (x1*x2 and x2*x3). Specify the terms using a formula in the form 'Y ~ terms'.
Mdl1 = fitcgam(tbl,'Y ~ x1 + x2 + x3 + x4 + x1:x2 + x2:x3');The function adds interaction terms to the model in the order of importance. You can use the Interactions property to check the interaction terms in the model and the order in which fitcgam adds them to the model. Display the Interactions property.
Mdl1.Interactions
ans = 2×2
2 3
1 2
Each row of Interactions represents one interaction term and contains the column indexes of the predictor variables for the interaction term.
Specify 'Interactions'
Pass the training data (tbl) and the name of the response variable in tbl to fitcgam, so that the function includes the linear terms for all the other variables as predictors. Specify the 'Interactions' name-value argument using a logical matrix to include the two interaction terms, x1*x2 and x2*x3.
Mdl2 = fitcgam(tbl,'Y','Interactions',logical([1 1 0 0; 0 1 1 0])); Mdl2.Interactions
ans = 2×2
2 3
1 2
You can also specify 'Interactions' as the number of interaction terms or as 'all' to include all available interaction terms. Among the specified interaction terms, fitcgam identifies those whose p-values are not greater than the 'MaxPValue' value and adds them to the model. The default 'MaxPValue' is 1 so that the function adds all specified interaction terms to the model.
Specify 'Interactions','all' and set the 'MaxPValue' name-value argument to 0.01.
Mdl3 = fitcgam(tbl,'Y','Interactions','all','MaxPValue',0.01); Mdl3.Interactions
ans = 5×2
3 4
2 4
1 4
2 3
1 3
Mdl3 includes five of the six available pairs of interaction terms.
Use addInteractions Function
Train a univariate GAM that contains linear terms for predictors, and then add interaction terms to the trained model by using the addInteractions function. Specify the second input argument of addInteractions in the same way you specify the 'Interactions' name-value argument of fitcgam. You can specify the list of interaction terms using a logical matrix, the number of interaction terms, or 'all'.
Specify the number of interaction terms as 5 to add the five most important interaction terms to the trained model.
Mdl4 = fitcgam(tbl,'Y');
UpdatedMdl4 = addInteractions(Mdl4,5);
UpdatedMdl4.Interactionsans = 5×2
3 4
2 4
1 4
2 3
1 3
Mdl4 is a univariate GAM, and UpdatedMdl4 is an updated GAM that contains all the terms in Mdl4 and five additional interaction terms.
Train a univariate classification GAM (which contains only linear terms) for a small number of iterations. After training the model for more iterations, compare the resubstitution loss.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereTrain a univariate GAM that identifies whether the radar return is bad ('b') or good ('g'). Specify the number of trees per linear term as 2. fitcgam iterates the boosting algorithm for the specified number of iterations. For each boosting iteration, the function adds one tree per linear term. Specify 'Verbose' as 2 to display diagnostic messages at every iteration.
Mdl = fitcgam(X,Y,'NumTreesPerPredictor',2,'Verbose',2);
|========================================================| | Type | NumTrees | Deviance | RelTol | LearnRate | |========================================================| | 1D| 0| 486.59| - | - | | 1D| 1| 166.71| Inf| 1| | 1D| 2| 78.336| 0.58205| 1|
To check whether fitcgam trains the specified number of trees, display the ReasonForTermination property of the trained model and view the displayed message.
Mdl.ReasonForTermination
ans = struct with fields:
PredictorTrees: 'Terminated after training the requested number of trees.'
InteractionTrees: ''
Compute the classification loss for the training data.
resubLoss(Mdl)
ans = 0.0142
Resume training the model for another 100 iterations. Because Mdl contains only linear terms, the resume function resumes training for the linear terms and adds more trees for them (predictor trees). Specify 'Verbose' and 'NumPrint' to display diagnostic messages at every 10 iterations.
UpdatedMdl = resume(Mdl,100,'Verbose',1,'NumPrint',10);
|========================================================| | Type | NumTrees | Deviance | RelTol | LearnRate | |========================================================| | 1D| 0| 78.336| - | - | | 1D| 1| 38.364| 0.17429| 1| | 1D| 10| 0.16311| 0.011894| 1| | 1D| 20| 0.00035693| 0.0025178| 1| | 1D| 30| 8.1191e-07| 0.0011006| 1| | 1D| 40| 1.7978e-09| 0.00074607| 1| | 1D| 50| 3.6113e-12| 0.00034404| 1| | 1D| 60| 1.7497e-13| 0.00016541| 1|
UpdatedMdl.ReasonForTermination
ans = struct with fields:
PredictorTrees: 'Unable to improve the model fit.'
InteractionTrees: ''
resume terminates training when adding more trees does not improve the deviance of the model fit.
Compute the classification loss using the updated model.
resubLoss(UpdatedMdl)
ans = 0
The classification loss decreases after resume updates the model with more iterations.