Choose Number of Topics for LDA Model
This example shows how to decide on a suitable number of topics for a latent Dirichlet allocation (LDA) model.
To decide on a suitable number of topics, you can compare the goodness-of-fit of LDA models fit with varying numbers of topics. You can evaluate the goodness-of-fit of an LDA model by calculating the perplexity of a held-out set of documents. The perplexity indicates how well the model describes a set of documents. A lower perplexity suggests a better fit.
Extract and Preprocess Text Data
Load the example data. The file factoryReports.csv contains factory reports, including a text description and categorical labels for each event. Extract the text data from the field Description.
filename = "factoryReports.csv"; data = readtable(filename,TextType="string"); textData = data.Description;
Tokenize and preprocess the text data using the function preprocessText which is listed at the end of this example.
documents = preprocessText(textData); documents(1:5)
ans =
5×1 tokenizedDocument:
6 tokens: item occasionally get stuck scanner spool
7 tokens: loud rattling bang sound come assembler piston
4 tokens: cut power start plant
3 tokens: fry capacitor assembler
3 tokens: mixer trip fuse
Set aside 10% of the documents at random for validation.
numDocuments = numel(documents); cvp = cvpartition(numDocuments,HoldOut=0.1); documentsTrain = documents(cvp.training); documentsValidation = documents(cvp.test);
Create a bag-of-words model from the training documents. Remove the words that do not appear more than two times in total. Remove any documents containing no words.
bag = bagOfWords(documentsTrain); bag = removeInfrequentWords(bag,2); bag = removeEmptyDocuments(bag);
Choose Number of Topics
The goal is to choose a number of topics that minimize the perplexity compared to other numbers of topics. This is not the only consideration: models fit with larger numbers of topics may take longer to converge. To see the effects of the tradeoff, calculate both goodness-of-fit and the fitting time. If the optimal number of topics is high, then you might want to choose a lower value to speed up the fitting process.
Fit some LDA models for a range of values for the number of topics. Compare the fitting time and the perplexity of each model on the held-out set of test documents. The perplexity is the second output to the logp function. To obtain the second output without assigning the first output to anything, use the ~ symbol. The fitting time is the TimeSinceStart value for the last iteration. This value is in the History struct of the FitInfo property of the LDA model.
For a quicker fit, specify 'Solver' to be 'savb'. To suppress verbose output, set 'Verbose' to 0. This may take a few minutes to run.
numTopicsRange = [5 10 15 20 40]; for i = 1:numel(numTopicsRange) numTopics = numTopicsRange(i); mdl = fitlda(bag,numTopics, ... Solver="savb", ... Verbose=0); [~,validationPerplexity(i)] = logp(mdl,documentsValidation); timeElapsed(i) = mdl.FitInfo.History.TimeSinceStart(end); end
Show the perplexity and elapsed time for each number of topics in a plot. Plot the perplexity on the left axis and the time elapsed on the right axis.
figure yyaxis left plot(numTopicsRange,validationPerplexity,"+-") ylabel("Validation Perplexity") yyaxis right plot(numTopicsRange,timeElapsed,"o-") ylabel("Time Elapsed (s)") legend(["Validation Perplexity" "Time Elapsed (s)"],Location="southeast") xlabel("Number of Topics")
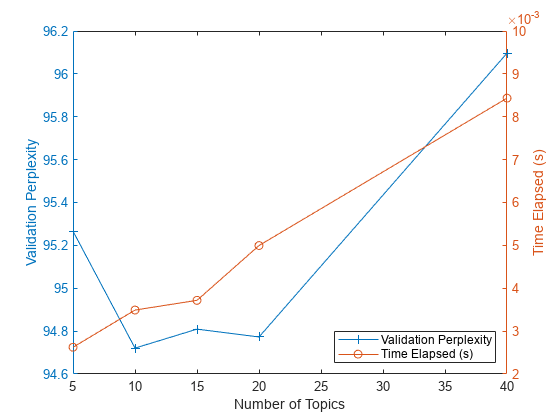
The plot suggests that fitting a model with 10–20 topics may be a good choice. The perplexity is low compared with the models with different numbers of topics. With this solver, the elapsed time for this many topics is also reasonable. With different solvers, you may find that increasing the number of topics can lead to a better fit, but fitting the model takes longer to converge.
Example Preprocessing Function
The function preprocessText, performs the following steps in order:
Tokenize the text using
tokenizedDocument.To improve lemmatization, add part-of-speech details using
addPartOfSpeechDetails.Lemmatize the words using
normalizeWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Erase punctuation using
erasePunctuation.
For an example showing how to interactively explore text preprocessing options, see Preprocess Text Data in Live Editor.
function documents = preprocessText(textData) % Tokenize. documents = tokenizedDocument(textData); % Lemmatize. documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,Style="lemma"); % Remove short and long words. documents = removeShortWords(documents,2); documents = removeLongWords(documents,15); % Remove stop words. documents = removeStopWords(documents,IgnoreCase=false); % Erase punctuation. documents = erasePunctuation(documents); end
See Also
tokenizedDocument | bagOfWords | removeStopWords | logp | bagOfWords | fitlda | ldaModel | erasePunctuation | removeShortWords | removeLongWords | normalizeWords | addPartOfSpeechDetails | removeInfrequentWords | removeEmptyDocuments