Regression Strategies for Large Datasets
By James C. Cross III, MathWorks
Plant operators and engineers use archival data to gain insight into the relationships between process parameters and product attributes. This study explains the creation of a predictive model and its use for plant profitability improvement, for the case where the dataset is larger than machine memory.
Dataset
An ammonia production process was modeled using MATLAB®. In this process, nitrogen and hydrogen are mixed, preheated, and fed to a catalytic reactor under pressure; the reactor outlet mixture is then chilled to condense the ammonia product, which is extracted; unreacted gases are recycled. The plant configuration and its primary control setpoints are shown in Figure 1.
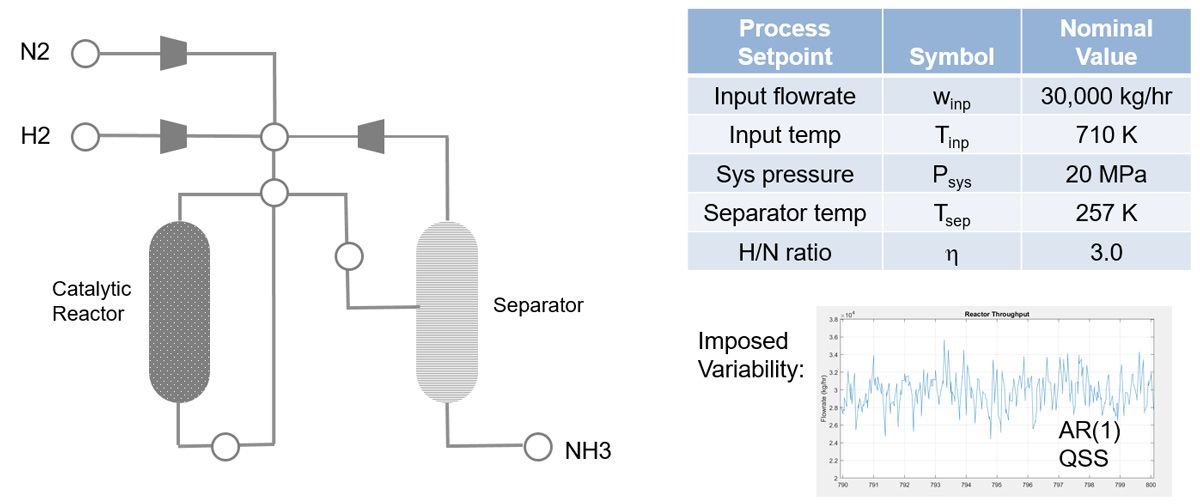
Figure 1. Process configuration and primary control setpoints.
Plant state variability was imposed by modeling the temporal progression of each control setpoint as an independent, first-order autoregressive process. In the simulation, at each 30-second time step the plant was assumed to be in a steady-state condition consistent with the setpoint values.
The simulation recorded ~300 distinct process/plant quantities: control setpoints, stream and spatially resolved reactor conditions (flowrates, compositions, temperatures, pressures), unit operations characteristics (duties, fuel and electricity consumption), and economic parameters (costs of feedstocks and energy, value of product) at 30-second intervals over a 6-year period.
The data file for each year is 4.7 GB in size; the entire data collection is ~28 GB.
Production Rate Modeling
As an initial exercise, the ammonia production rate was considered as a response and the five control setpoints as predictors. A standard multivariate regression model was created using the MATLAB fitlm function. A time window of data with a 300-hour duration (36,000 time records) was arbitrarily selected for model development. 70% of the data was used for training the model, and 30% was reserved for model validation.
Because of known nonlinearities within the process, it was expected that a simple linear regression model would perform less well than one that included feature interactions, and this expectation was borne out: The normalized root-mean-square errors for the linear (first-order) and second-order cases were 2.17% and 0.36%, respectively. The results for the second-order case are shown on the left in Figure 2.
A time-dependent, real-world effect was included in the simulation, namely, aging of the reaction catalyst, which results in a decline in reactor performance and ammonia production rate over time. Applying the model at a later time (60 days) leads to overprediction of production rate, as can be seen on the right in Figure 2. This model fails to account for the catalyst aging phenomenon.

Figure 2. Production model results (predicted vs. actual).
To create a model that could be used at any time during the catalyst life cycle, a new feature (predictor) indicating the catalyst age state needed to be introduced (details not discussed here).
Computing Infrastructure
To illustrate specific enabling methodologies for analyzing large datasets, this study undertook the regression analysis using the entire 28 GB dataset. Specifically, MATLAB big data utilities and an Apache Spark™-enabled Hadoop® cluster were used.
The process data set was created, stored, and accessed from within the Hadoop Distributed File System (HDFS) framework. Spark was invoked from within a live MATLAB session and used to distribute the process simulation (initially) and the regression calculations (subsequently), over the available computing cluster resources (11 nodes in this case).
The MATLAB data management functionality used included:
datastore, which enables definition of a data repository consisting of multiple filestall, which assigns variable names to arrays, optionally of mixed data types, which can be larger than available machine memorygather, which initiates and manages the evaluation of commands on tall objects
Financial Modeling
This study next sought to build a model for real-time plant operating profit—a very complex function of the control setpoints and catalyst age parameters. In this case, third-degree cross-interactions were required to achieve reasonable accuracy. The results are shown in Figure 3.

Figure 3. Profit model results (predicted vs. actual).
Charts are shown for two adjacent time periods: catalyst Lot 3 end of service and catalyst Lot 4 beginning of service. Unlike the two results shown in Figure 2, these charts demonstrate the value of the added catalyst age feature—predictions at two very different ages exhibit comparable accuracy.
Process Optimization
As shown in Figure 1, the control setpoints in the status quo case are (naively) held at constant values over the catalyst age life cycle. With a model of operating profit now created, a natural question arises: What combination of control setpoints, as a function of catalyst age, is predicted to yield maximum profit?
There are two approaches to calculating profit: real-time, which neglects catalyst degradation consequences associated with selected process conditions, and life-cycle, which imputes a real-time cost penalty (based on replacement costs) to the profit to account for catalyst aging effects.
The operating schedules predicted to generate maximum profits were computed using the regression model for plant profit. The results are shown in Figure 4.

Figure 4. Plant operating schedules (profit-maximizing vs. status quo).
Process simulations were subsequently conducted to quantify the actual plant profit associated with the predicted profit-maximizing operating schedules shown in Figure 4. The scheme for imposing plant state temporal variability was kept the same as in the status quo case. In all cases, plant operation was suspended, and the catalyst was replaced when its effectiveness reached 60% of its initial value. The results are summarized in Figure 5.

Figure 5. Bottom-line comparisons of plant operating strategies.
Both profit-maximizing strategies are more aggressive than the status quo with regard to catalyst degradation rate—the times between replacement interventions are roughly half as long.
The net catalyst-lot cycle profit for all three approaches is within 13% of the mean value.
However, the net profit per unit time for the optimized schedules is considerably (1.8–1.9x) higher than the status quo case, spotlighting a substantial opportunity for performance improvement. The value of the data analysis effort is immediately apparent.
Summary
In this paper, classical regression methods were used with contemporary big data utilities to analyze a 28 GB dataset and create predictive models for production rate, catalyst age, and operating profit. The model was subsequently used to compute optimal control setpoint schedules as a function of catalyst age state, which revealed an opportunity for increasing operating profits by ~90%.
This extended abstract was presented at the AIChE Spring Meeting (San Antonio, Texas) in March 2017.
Published 2017 - 93168v00