CREPE
Libraries:
Audio Toolbox /
Deep Learning
Description
The CREPE block leverages a pretrained convolutional neural model to estimate pitch from an audio signal. This block requires Deep Learning Toolbox™.
Examples
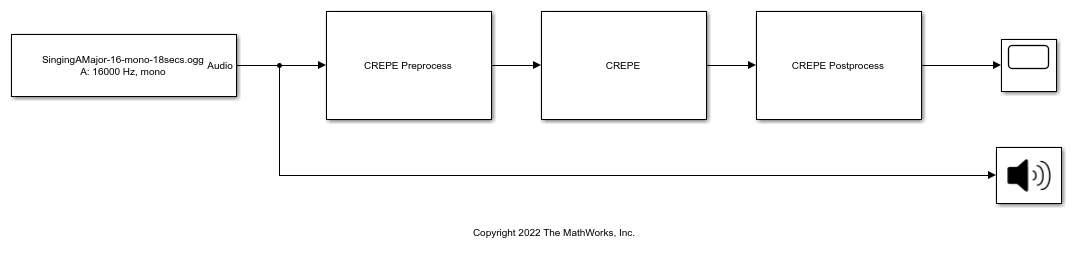
This example shows how to use the CREPE blocks to combine preprocessing, network inference, and postprocessing and obtain pitch estimations from an audio signal. See Estimate Pitch Using Deep Pitch Estimator Block for an example that uses the Deep Pitch Estimator block to perform the same task.
Adjust the parameters of the blocks to speed up computation and see the pitch estimations in real time as the audio plays.
Set the Overlap percentage (%) of the CREPE Preprocess block to
50. With a lower overlap percentage, the system processes frames less frequently.Set the Number of output frames of the CREPE Preprocess block to
5. This causes the CREPE Preprocess block to buffer audio frames and pass them to the CREPE block in batches. Passing batches to the CREPE block improves computational efficiency by allowing it to process multiple frames in parallel. However, it also increases latency because the system outputs pitch estimations in batches instead of one at a time.Set the Model capacity of the CREPE block to
Large. This model has fewer parameters than the full-size model, leading to faster computation at the cost of slightly lower accuracy.
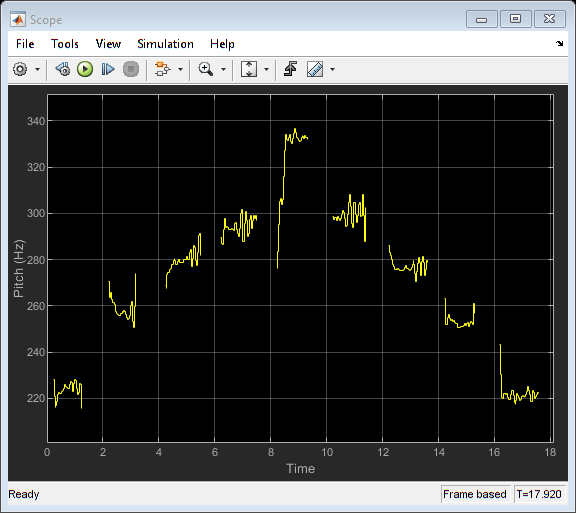
Run the model to listen to a singing voice and view the estimated pitch in real time.
Ports
Input
Output
Parameters
Block Characteristics
Data Types |
|
Direct Feedthrough |
|
Multidimensional Signals |
|
Variable-Size Signals |
|
Zero-Crossing Detection |
|
References
[1] Kim, Jong Wook, Justin Salamon, Peter Li, and Juan Pablo Bello. “Crepe: A Convolutional Representation for Pitch Estimation.” In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 161–65. Calgary, AB: IEEE, 2018. https://doi.org/10.1109/ICASSP.2018.8461329.
Extended Capabilities
Version History
Introduced in R2023a