pitchnn
Estimate pitch with deep learning neural network
Syntax
Description
f0 = pitchnn(audioIn,fs,Name,Value)Name,Value arguments. For
example, f0 = pitchnn(audioIn,fs,'ConfidenceThreshold',0.5) sets the
confidence threshold for each value of f0 to
0.5.
[
returns the activations of a CREPE pretrained network.f0,loc,activations] = pitchnn(___)
pitchnn(___) with no output arguments plots the
estimated fundamental frequency over time.
Examples
Download and unzip the Audio Toolbox™ model for CREPE to use pitchnn.
Type pitchnn at the Command Window. If the Audio Toolbox model for CREPE is not installed, then the function provides a link to the location of the network weights. To download the model, click the link and unzip the file to a location on the MATLAB® path.
Alternatively, execute these commands to download and unzip the CREPE model to your temporary directory.
downloadFolder = fullfile(tempdir,'crepeDownload'); loc = websave(downloadFolder,'https://ssd.mathworks.com/supportfiles/audio/crepe.zip'); crepeLocation = tempdir; unzip(loc,crepeLocation) addpath(fullfile(crepeLocation,'crepe'))
The CREPE network requires you to preprocess your audio signals to generate buffered, overlapped, and normalized audio frames that can be used as input to the network. This example demonstrates the pitchnn function performing all of these steps for you.
Read in an audio signal for pitch estimation. Visualize and listen to the audio. There are nine vocal utterances in the audio clip.
[audioIn,fs] = audioread('SingingAMajor-16-mono-18secs.ogg'); soundsc(audioIn,fs) T = 1/fs; t = 0:T:(length(audioIn)*T) - T; plot(t,audioIn); grid on axis tight xlabel('Time (s)') ylabel('Ampltiude') title('Singing in A Major')

Use the pitchnn function to produce the pitch estimate using a CREPE network with ModelCapacity set to tiny and ConfidenceThreshold disabled. Calling pitchnn with no output arguments plots the pitch estimation over time. If you call pitchnn before downloading the model, an error is printed to the Command Window with a download link.
pitchnn(audioIn,fs,'ModelCapacity','tiny','ConfidenceThreshold',0)

With confidence thresholding disabled, pitchnn provides a pitch estimate for every frame. Increase the ConfidenceThreshold to 0.8.
pitchnn(audioIn,fs,'ModelCapacity','tiny','ConfidenceThreshold',0.8)

Call pitchnn with ModelCapacity set to full. There are nine primary pitch estimation groupings, each group corresponding with one of the nine vocal utterances.
pitchnn(audioIn,fs,'ModelCapacity','full','ConfidenceThreshold',0.8)
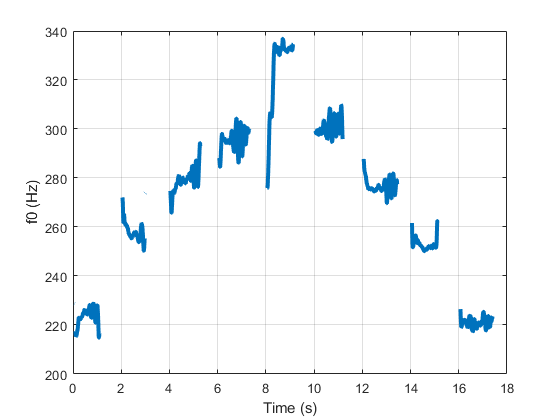
Call spectrogram and compare the frequency content of the signal with the pitch estimates from pitchnn. Use a frame size of 250 samples and an overlap of 225 samples or 90%. Use 4096 DFT points for the transform.
spectrogram(audioIn,250,225,4096,fs,'yaxis')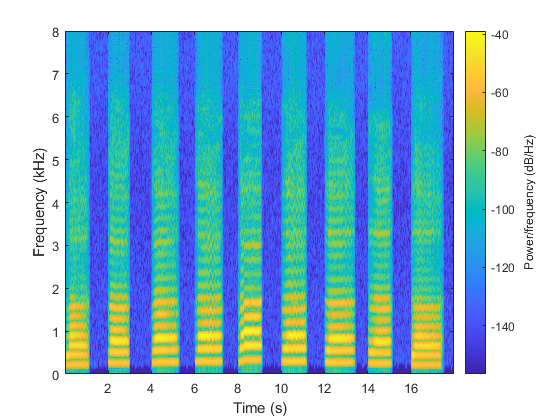
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Kim, Jong Wook, Justin Salamon, Peter Li, and Juan Pablo Bello. “Crepe: A Convolutional Representation for Pitch Estimation.” In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 161–65. Calgary, AB: IEEE, 2018. https://doi.org/10.1109/ICASSP.2018.8461329.
Extended Capabilities
Version History
Introduced in R2021a