samplealign
Align peaks in signal to reference peaks
Description
Examples
Create two signals with noisy Gaussian peaks.
rng('default')
peakLoc = [30 60 90 130 150 200 230 300 380 430];
peakInt = [7 1 3 10 3 6 1 8 3 10];
time = 1:450;
comp = exp(-(bsxfun(@minus,time,peakLoc')./5).^2);
sig_1 = (peakInt + rand(1,10)) * comp + rand(1,450);
sig_2 = (peakInt + rand(1,10)) * comp + rand(1,450);Define a nonlinear warping function.
wf = @(t) 1 + (t<=100).*0.01.*(t.^2) + (t>100).*...
(310+150*tanh(t./100-3));Warp the second signal to distort it.
sig_2 = interp1(time,sig_2,wf(time),'pchip');Align the observations between the two signals by introducing gaps.
[i,j] = samplealign([time;sig_1]',[time;sig_2]',... 'weights',[0,1],'band',35,'quantile',.5);
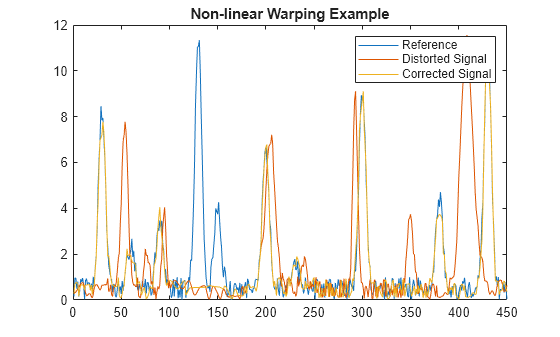
Plot the reference signal, distorted signal, and warped (corrected) signal.
figure sig_3 = interp1(time,sig_2,interp1(i,j,time,'pchip'),'pchip'); plot(time,sig_1,time,sig_2,time,sig_3) legend('Reference','Distorted Signal','Corrected Signal') title('Non-linear Warping Example')
Plot the real and the estimated warping functions.
figure plot(time,wf(time),time,interp1(j,i,time,'pchip')) legend('Distorting Function','Estimated Warping')

Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
samplealign uses a dynamic programming algorithm to minimize the
sum of positive scores resulting from pairs of observations that are potential matches
and the penalties resulting from the insertion of gaps. Return values
I and J are column vectors containing
indices that indicate the matches for each row (observation) in X
and Y respectively. For the algorithmic complexity, see
Band.
If you do not specify the return values I and
J, samplealign does not run the dynamic
programming algorithm. Running samplealign without return values, but
setting the ShowConstraints, ShowNetwork, or
ShowAlignment name-value arguments to true,
lets you explore the constrained search space, the dynamic programming network, or the
aligned observations, without running into potential memory problems.
References
[1] Myers, C.S. and Rabiner, L.R. (1981). A comparative study of several dynamic time-warping algorithms for connected word recognition. The Bell System Technical Journal 60:7, 1389–1409.
[2] Sakoe, H. and Chiba, S. (1978). Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoustics, Speech and Signal Processing ASSP-26(1), 43–49.
Version History
Introduced in R2007b