Linear Regression with One Predictor Variable
Simple linear regression describes the relationship between a single predictor variable and a response variable. A linear regression model is useful for understanding how changes in the predictor influence the response.
This example shows how to fit, visualize, and validate simple linear regression models of varying degrees using the polyfit and polyval functions. For information about fitting and visualizing a model using the Basic Fitting tool instead, see Interactively Fit Data and Visualize Model.
Use simple linear regression when:
You have one predictor variable.
The relationship between the predictor and response is linear in the coefficients.
You want to quantify the effect of the predictor on the response.
Plot Data
Start by plotting your data to identify possible degrees for your polynomial fit.
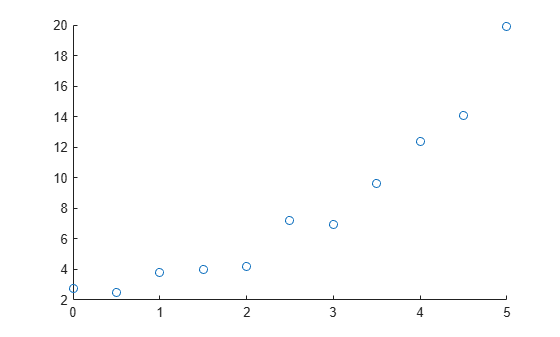
For example, create and visualize a sample predictor variable x and a sample response variable y. This visualization suggests that a linear or quadratic fit might describe the relationship between the predictor and response variables.
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
Fit First-Degree Model
Fit a first-degree (linear) model to the data by using the polyfit function. Specify two output arguments to return the polynomial coefficients as well as the error estimation structure.
[pLinear,SLinear] = polyfit(x,y,1)
pLinear = 1×2
3.1316 0.1155
SLinear = struct with fields:
R: [2×2 double]
df: 9
normr: 6.3071
rsquared: 0.8715
Display the fitted model.
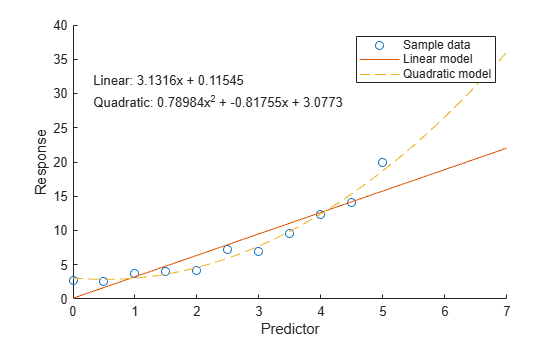
eqLinear = "Linear: " + pLinear(1) + "x + " + pLinear(2)
eqLinear = "Linear: 3.1316x + 0.11545"
Fit Higher-Degree Model
If a first-degree model does not adequately describe the relationship between the predictor and response variables, you can fit a higher-degree model. For example, fit a second-degree (quadratic) model to the data by using the polyfit function. Specify two output arguments to return the polynomial coefficients as well as the error estimation structure.
[pQuad,SQuad] = polyfit(x,y,2)
pQuad = 1×3
0.7898 -0.8175 3.0773
SQuad = struct with fields:
R: [3×3 double]
df: 8
normr: 2.5152
rsquared: 0.9796
Display the fitted model.
eqQuad = "Quadratic: " + pQuad(1) + "x^2 + " + pQuad(2) + "x + " + pQuad(3)
eqQuad = "Quadratic: 0.78984x^2 + -0.81755x + 3.0773"
Compare Models
To compare models using a plot, first evaluate each model at query points and return the predicted response values using the polyval function. Then visualize the data and both models.
For example, get the response values for the linear model and the quadratic model over a finer range of x values.
xQuery = [0:0.05:7]'; yLinear = polyval(pLinear,xQuery); yQuad = polyval(pQuad,xQuery);
If the higher-degree model does not predict the response values well, this might indicate overfitting. For information about validating your model and selecting the appropriate model complexity, see the Validate Model section.
Then plot the sample data and the model data.
scatter(x,y) hold on plot(xQuery,yLinear,"-") plot(xQuery,yQuad,"--") hold off xlabel("Predictor") ylabel("Response") legend(["Sample data" "Linear model" "Quadratic model"]) text(0.3,30,[eqLinear eqQuad])
Validate Models
To validate a model, compute the coefficient of determination (R-squared) or adjusted coefficient of determination (adjusted R-squared). A value close to 1 indicates a good fit.
Validate Linear Model with R-Squared
For a first-degree model, you can access the R-squared value using the error estimation structure returned by the polyfit function. For example, query the rsquared field in SLinear.
linearR2 = SLinear.rsquared
linearR2 = 0.8715
Validate Higher-Degree Model with Adjusted R-Squared
For higher-degree models with more terms, the R-squared value typically increases, indicating a closer fit to the observed data. However, these models have a higher risk of overfitting.
Overfitting happens when a model describes your original data (including noise) too closely and is not a good predictor of new data.
To balance prediction quality and model complexity, consider validating the model using the adjusted R-squared value, which includes a penalty for the number of predictors. You can calculate the adjusted R-squared value by using this equation, where is the value of the rsquared field in the error estimation structure, is the number of observations in your data, and is the degree of your model.
For example, compute the adjusted R-squared value for the quadratic model.
quadAdjRsq = 1 - (1 - SQuad.rsquared) * (numel(y) - 1) / (numel(y) - 2 - 1)
quadAdjRsq = 0.9744
Compute Maximum Prediction Error for Each Model
You can also validate a model by computing the largest error between the model predictions and the sample data. A small maximum error relative to the data values indicates a good fit.
For example, compute the maximum error for both the linear model and the quadratic model.
Lia = ismember(xQuery,x); linearMaxError = max(abs(yLinear(Lia) - y))
linearMaxError = 4.1564
quadMaxError = max(abs(yQuad(Lia) - y))
quadMaxError = 1.2926
See Also
Functions
Topics
- Interactively Fit Data and Visualize Model
- Linear Regression with Nonpolynomial Terms
- Linear Regression with Multiple Predictor Variables
- Create and Evaluate Polynomials
- Linear Regression Workflow (Statistics and Machine Learning Toolbox)
- Fit Polynomial Models (Curve Fitting Toolbox)