Analyze Text Data with String Arrays
This example shows how to store text from a file as a string array, sort the words by their frequency, plot the result, and collect basic statistics for the words found in the file.
Import Text File to String Array
Read text from Shakespeare's Sonnets with the fileread function. fileread returns the text as a 1-by-100266 character vector.
sonnets = fileread('sonnets.txt');
sonnets(1:35)ans =
'THE SONNETS
by William Shakespeare'
Convert the text to a string using the string function. Then, split it on newline characters using the splitlines function. sonnets becomes a 2625-by-1 string array, where each string contains one line from the poems. Display the first five lines of sonnets.
sonnets = string(sonnets); sonnets = splitlines(sonnets); sonnets(1:5)
ans = 5×1 string
"THE SONNETS"
""
"by William Shakespeare"
""
""
Clean String Array
To calculate the frequency of the words in sonnets, first clean it by removing empty strings and punctuation marks. Then reshape it into a string array that contains individual words as elements.
Remove the strings with zero characters ("") from the string array. Compare each element of sonnets to "", the empty string. You can create strings, including an empty string, using double quotes. TF is a logical vector that contains a true value wherever sonnets contains a string with zero characters. Index into sonnets with TF and delete all strings with zero characters.
TF = (sonnets == "");
sonnets(TF) = [];
sonnets(1:10)ans = 10×1 string
"THE SONNETS"
"by William Shakespeare"
" I"
" From fairest creatures we desire increase,"
" That thereby beauty's rose might never die,"
" But as the riper should by time decease,"
" His tender heir might bear his memory:"
" But thou, contracted to thine own bright eyes,"
" Feed'st thy light's flame with self-substantial fuel,"
" Making a famine where abundance lies,"
Replace some punctuation marks with space characters. For example, replace periods, commas, and semi-colons. Keep apostrophes because they can be part of some words in the Sonnets, such as light's.
p = [".","?","!",",",";",":"]; sonnets = replace(sonnets,p," "); sonnets(1:10)
ans = 10×1 string
"THE SONNETS"
"by William Shakespeare"
" I"
" From fairest creatures we desire increase "
" That thereby beauty's rose might never die "
" But as the riper should by time decease "
" His tender heir might bear his memory "
" But thou contracted to thine own bright eyes "
" Feed'st thy light's flame with self-substantial fuel "
" Making a famine where abundance lies "
Strip leading and trailing space characters from each element of sonnets.
sonnets = strip(sonnets); sonnets(1:10)
ans = 10×1 string
"THE SONNETS"
"by William Shakespeare"
"I"
"From fairest creatures we desire increase"
"That thereby beauty's rose might never die"
"But as the riper should by time decease"
"His tender heir might bear his memory"
"But thou contracted to thine own bright eyes"
"Feed'st thy light's flame with self-substantial fuel"
"Making a famine where abundance lies"
Split sonnets into a string array whose elements are individual words. You can use the split function to split elements of a string array on whitespace characters, or on delimiters that you specify. However, split requires that every element of a string array must be divisible into an equal number of new strings. The elements of sonnets have different numbers of spaces, and therefore are not divisible into equal numbers of strings. To use the split function on sonnets, write a for-loop that calls split on one element at a time.
Create the empty string array sonnetWords using the strings function. Write a for-loop that splits each element of sonnets using the split function. Concatenate the output from split onto sonnetWords. Each element of sonnetWords is an individual word from sonnets.
sonnetWords = strings(0); for i = 1:length(sonnets) sonnetWords = [sonnetWords ; split(sonnets(i))]; end sonnetWords(1:10)
ans = 10×1 string
"THE"
"SONNETS"
"by"
"William"
"Shakespeare"
"I"
"From"
"fairest"
"creatures"
"we"
Sort Words Based on Frequency
Find the unique words in sonnetWords. Count them and sort them based on their frequency.
To count words that differ only by case as the same word, convert sonnetWords to lowercase. For example, The and the count as the same word. Find the unique words using the unique function. Then, count the number of times each unique word occurs using the histcounts function.
sonnetWords = lower(sonnetWords); [words,~,idx] = unique(sonnetWords); numOccurrences = histcounts(idx,numel(words));
Sort the words in sonnetWords by number of occurrences, from most to least common.
[rankOfOccurrences,rankIndex] = sort(numOccurrences,'descend');
wordsByFrequency = words(rankIndex);Plot Word Frequency
Plot the occurrences of words in the Sonnets from the most to least common words. Zipf's Law states that the distribution of occurrences of words in a large body text follows a power-law distribution.
loglog(rankOfOccurrences); xlabel('Rank of word (most to least common)'); ylabel('Number of Occurrences');
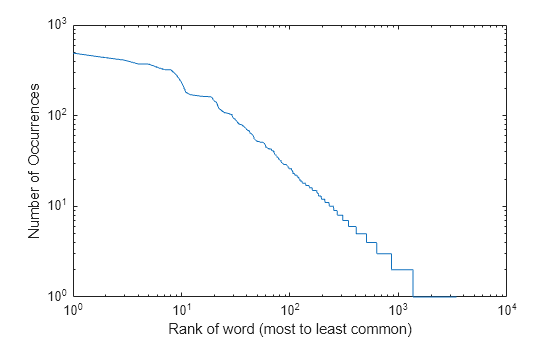
Display the ten most common words in the Sonnets.
wordsByFrequency(1:10)
ans = 10×1 string
"and"
"the"
"to"
"my"
"of"
"i"
"in"
"that"
"thy"
"thou"
Collect Basic Statistics in Table
Calculate the total number of occurrences of each word in sonnetWords. Calculate the number of occurrences as a percentage of the total number of words, and calculate the cumulative percentage from most to least common. Write the words and the basic statistics for them to a table.
numOccurrences = numOccurrences(rankIndex); numOccurrences = numOccurrences'; numWords = length(sonnetWords); T = table; T.Words = wordsByFrequency; T.NumOccurrences = numOccurrences; T.PercentOfText = numOccurrences / numWords * 100.0; T.CumulativePercentOfText = cumsum(numOccurrences) / numWords * 100.0;
Display the statistics for the ten most common words.
T(1:10,:)
ans=10×4 table
Words NumOccurrences PercentOfText CumulativePercentOfText
______ ______________ _____________ _______________________
"and" 490 2.7666 2.7666
"the" 436 2.4617 5.2284
"to" 409 2.3093 7.5377
"my" 371 2.0947 9.6324
"of" 370 2.0891 11.722
"i" 341 1.9254 13.647
"in" 321 1.8124 15.459
"that" 320 1.8068 17.266
"thy" 280 1.5809 18.847
"thou" 233 1.3156 20.163
The most common word in the Sonnets, and, occurs 490 times. Together, the ten most common words account for 20.163% of the text.
See Also
string | split | join | unique | replace | lower | splitlines | histcounts | strip | sort | table