lscov
Least-squares solution in presence of known covariance
Syntax
Description
x = lscov(A,b,C,alg)lscov uses the Cholesky decomposition of C to
compute x. Specify alg as
"orth" to use an orthogonal decomposition of C. If
C is not invertible, lscov uses an orthogonal
decomposition regardless of the value of alg.
Examples
Create a matrix A and vector b for the linear system A*x = b. Compute the least-squares solution of the linear system using lscov. Specify three output arguments to return the solution, its estimated standard errors, and its mean squared error.
a1 = [0.2; 0.5; 0.6; 0.8; 1.0; 1.1]; a2 = [0.1; 0.3; 0.4; 0.9; 1.1; 1.4]; A = [ones(size(a1)) a1 a2]; b = [0.17; 0.26; 0.28; 0.23; 0.27; 0.24]; [x,stdx,mse] = lscov(A,b)
x = 3×1
0.1018
0.4844
-0.2847
stdx = 3×1
0.0058
0.0206
0.0135
mse = 1.2774e-05
Add noise to b to create a matrix of samples and compute the least-squares estimate of the matrix using the backslash operator (\). Calculate the standard error for each row of the result.
B = b + randn(6,1e5); X = A\B; s1 = std(X,0,2)
s1 = 3×1
1.6311
5.7609
3.7838
Compare the standard errors obtained using backslash with the standard errors obtained using lscov. Rescale the standard errors stdx by the square root of mse to account for scaling performed by lscov. The standard errors over X generally match the standard errors computed by lscov. The rescaled standard errors indicate that if b has uniform noise across its elements, the second element of x is affected much more than the first element.
s2 = stdx/sqrt(mse)
s2 = 3×1
1.6349
5.7661
3.7845
Create a matrix A and vector b for the problem A*x = b. Create a vector of relative observational weights, and compute the weighted least-squares solution.
a1 = [0.2; 0.5; 0.6; 0.8; 1.0; 1.1]; a2 = [0.1; 0.3; 0.4; 0.9; 1.1; 1.4]; A = [ones(size(a1)) a1 a2]; b = [0.17; 0.26; 0.28; 0.23; 0.27; 0.34]; w = [1 1 1 1 1 0.1]'; [x1,stdx1,mse1] = lscov(A,b,w)
x1 = 3×1
0.1046
0.4614
-0.2621
stdx1 = 3×1
0.0309
0.1152
0.0814
mse1 = 3.4741e-04
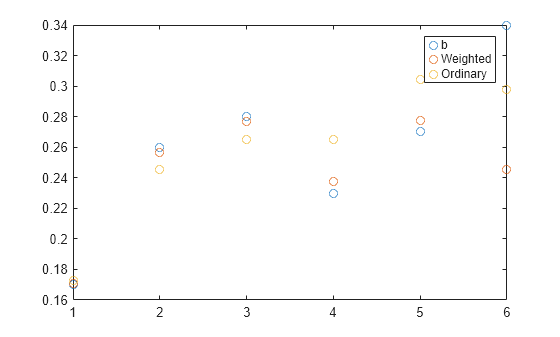
Compute the ordinary least-squares solution of the same problem and plot both solutions. For the first five points, the weighted least-squares solution is closer to b than the ordinary least-squares solution is. Because the sixth element of the weighted least-squares solution was weighted down, the sixth point of its solution is farther from b.
[x2,stdx2,mse2] = lscov(A,b); x = 1:6; plot(x,b,"o",x,A*x1,"o",x,A*x2,"o") legend("b","Weighted","Ordinary")
Create a matrix A and vector b for the problem A*x = b. Create a matrix of covariance scales, and compute a generalized least-squares solution.
a1 = [0.2; 0.5; 0.6; 0.8; 1.0; 1.1]; a2 = [0.1; 0.3; 0.4; 0.9; 1.1; 1.4]; A = [ones(size(a1)) a1 a2]; b = [0.17; 0.26; 0.28; 0.23; 0.27; 0.24]; C = 0.2*ones(size(a1)) + 0.8*diag(ones(size(a1))); [x,stdx,mse] = lscov(A,b,C)
x = 3×1
0.1018
0.4844
-0.2847
stdx = 3×1
0.0061
0.0206
0.0135
mse = 1.5967e-05
Create a matrix A and vector b for the problem A*x = b. Compute an estimate of the covariance matrix of x.
a1 = [0.2; 0.5; 0.6; 0.8; 1.0; 1.1]; a2 = [0.1; 0.3; 0.4; 0.9; 1.1; 1.4]; A = [ones(size(a1)) a1 a2]; b = [0.17; 0.26; 0.28; 0.23; 0.27; 0.24]; [x,stdx,mse,S] = lscov(A,b)
x = 3×1
0.1018
0.4844
-0.2847
stdx = 3×1
0.0058
0.0206
0.0135
mse = 1.2774e-05
S = 3×3
10-3 ×
0.0341 -0.1075 0.0617
-0.1075 0.4247 -0.2712
0.0617 -0.2712 0.1829
The coefficient standard errors are equal to the square roots of the values on the diagonal of this covariance matrix.
sqrt(diag(S))
ans = 3×1
0.0058
0.0206
0.0135
Input Arguments
Output Arguments
Algorithms
When m-by-n matrix A and
m-by-m matrix C are full rank in
a generalized least-squares problem, these standard formulas represent the outputs of
lscov when m is greater than or equal to
n.
x = inv(A'*inv(C)*A)*A'*inv(C)*b mse = (b - A*x)'*inv(C)*(b - A*x)./(m-n) S = inv(A'*inv(C)*A)*mse stdx = sqrt(diag(S))
When m is less than n, the mean squared error is 0.
For weighted least squares, the standard formulas apply when substituting
diag(1./w) for C. For ordinary least squares,
substitute the identity matrix for C.
The lscov function uses methods that are faster and more stable than
the standard formulas, and are applicable to rank-deficient cases. For instance,
lscov computes the Cholesky decomposition C = R'*R
and then solves the least-squares problem (R'\A)*x = (R'\b) instead, using
the same algorithm that is used in mldivide for A\b to
solve a least-squares problem.
References
[1] Paige, Christopher C. "Computer Solution and Perturbation Analysis of Generalized Linear Least Squares Problems." Mathematics of Computation 33, no. 145 (1979): 171–83. https://doi.org/10.2307/2006034.
[2] Golub, Gene H., and Charles F. Van Loan. Matrix Computations. Baltimore, MD: Johns Hopkins University Press, 1996.
[3] Goodall, Colin R. "Computation using the QR decomposition." Handbook of Statistics 9 (1993): 467–508. https://doi.org/10.1016/S0169-7161(05)80137-3.
[4] Strang, Gilbert. Introduction to Applied Mathematics. Wellesley, MA: Wellesley-Cambridge Press, 1986.
Extended Capabilities
Version History
Introduced before R2006a