ncread
Read data from variable in netCDF data source
Syntax
Description
Examples
Read and plot a variable named peaks from the netCDF file example.nc.
peaksData = ncread("example.nc","peaks"); whos peaksData
Name Size Bytes Class Attributes peaksData 50x50 5000 int16
Plot peaksData and add a title.
surf(peaksData)
title("Peaks Data")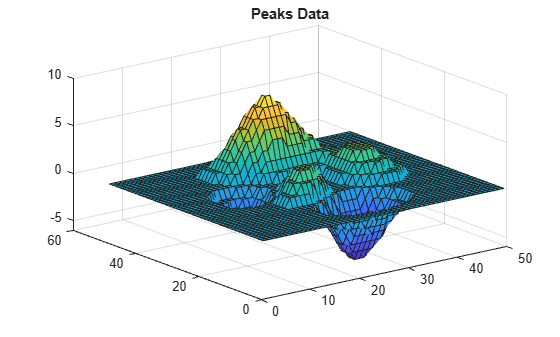
Read and plot only a subset of the peaks variable data starting from the location [25 17] until the end of each dimension.
start = [25 17]; % Start location along each coordinate count = [Inf Inf]; % Read until the end of each dimension peaksData = ncread("example.nc","peaks",start,count); whos peaksData
Name Size Bytes Class Attributes peaksData 26x34 1768 int16
Plot the data.
surf(peaksData)
title("Peaks Data Starting at [25 17]")![Figure contains an axes object. The axes object with title Peaks Data Starting at [25 17] contains an object of type surface.](../../examples/matlab/win64/ReadVariableStartingAtSpecifiedCoordinatesExample_01.png)
Read and plot data, where the data is sampled at a specified spacing between variable indices along each dimension. Read variable data at intervals specified in stride, starting from the location in start. A value of 1 in stride accesses adjacent values in the corresponding dimension, a value of 2 accesses every other value in the corresponding dimension, and so on.
start = [1 1]; count = [10 15]; stride = [2 3]; sampledPeaksData = ncread("example.nc","peaks",start,count,stride); whos sampledPeaksData
Name Size Bytes Class Attributes sampledPeaksData 10x15 300 int16
Plot the data.
surf(sampledPeaksData)
title("Peaks Data Subsampled by [2 3]")![Figure contains an axes object. The axes object with title Peaks Data Subsampled by [2 3] contains an object of type surface.](../../examples/matlab/win64/SubsampleVariableDataExample_01.png)
Input Arguments
Output Arguments
More About
Tips
MATLAB interprets data as column major, but the netCDF C API interprets data as row major. Multidimensional data in the netCDF C API shows dimensions in the reverse of the order shown by MATLAB and consequently appears transposed.