Big Data Processing
mapreduce, on Spark® and Hadoop® clustersYou can use Parallel Computing Toolbox™ to distribute large arrays in parallel across multiple MATLAB® workers, so that you can run big-data applications that use the
combined memory of your cluster. You operate on the entire array as a single entity,
however, workers operate only on their part of the array, and automatically transfer
data between themselves when necessary. Parallel Computing Toolbox also enables you to execute MATLAB tall array and datastore calculations in
parallel, so that you can analyze big data sets that do not fit in the memory of
your cluster. You can use MATLAB
Parallel Server™ to run tall array and datastore calculations in
parallel on Spark enabled Hadoop clusters. Doing so significantly reduces
the execution time of very large data calculations.
Categories
- Distributed Arrays
Analyze big data sets in parallel using distributed arrays and simultaneous execution
- Tall Arrays and mapreduce
Analyze big data sets in parallel using MATLAB tall arrays and datastores ormapreduceon Spark and Hadoop clusters, and parallel pools
Featured Examples
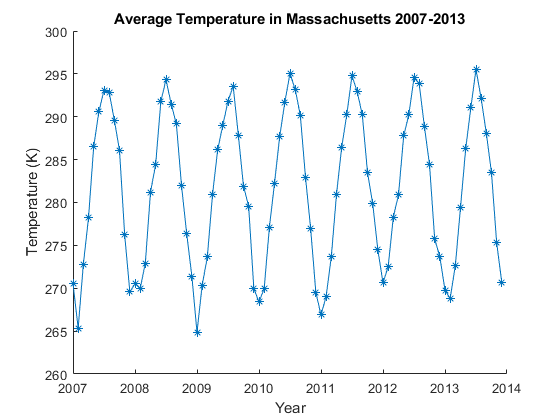
Process Big Data in the Cloud
Access a large data set in the cloud and process it in a cloud cluster using MATLAB® capabilities for big data.
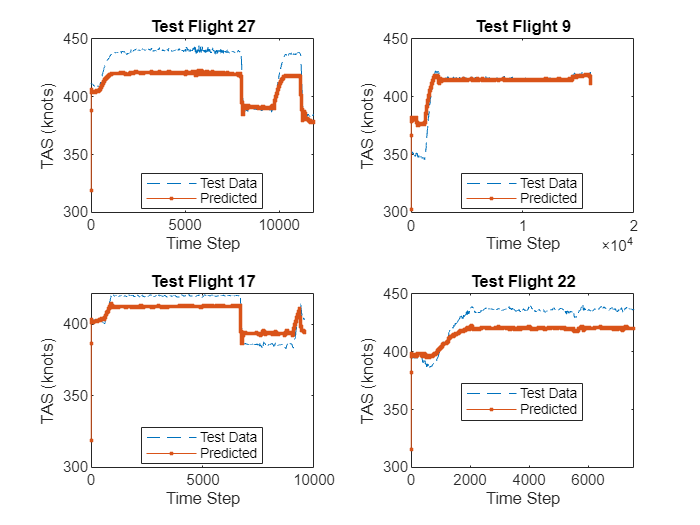
Use Parallel Computing to Optimize Big Data Set for Analysis
Optimize data preprocessing for analysis using parallel computing.