Organize System Data for Diagnostic Feature Designer
The Diagnostic Feature Designer app allows you to interactively analyze data and develop features that can distinguish between data from healthy systems and degraded systems. The app operates on a collection of measurement data and information from set of similar systems such as machines. To use the app, you must first organize your data into a form that the app can import. One way to organize your data is with numerical matrices, which can capture all your measurement data. However, you can also use more flexible formats such as tables, which allow you to incorporate additional information such as health condition and operating conditions. With this information, you can explore features within the app and assess feature ability to distinguish between different specific conditions.
Data Ensembles
Data analysis is the heart of any condition monitoring and predictive maintenance activity.
The data can come from measurements on systems using sensors such as accelerometers, pressure gauges, thermometers, altimeters, voltmeters, and tachometers. For instance, you might have access to measured data from:
Normal system operation
The system operating in a faulty condition
Lifetime record of system operation (run-to-failure data)
For algorithm design, you can also use simulated data generated by running a Simulink® model of your system under various operating and fault conditions.
Whether using measured data, generated data, or both, you frequently have many signals, ranging over a time span or multiple time spans. You might also have signals from many machines (for example, measurements from a number of separate engines all manufactured to the same specifications). And you might have data representing both healthy operation and fault conditions. Evaluating effective features for predictive maintenance requires organizing and analyzing this data while keeping track of the systems and conditions the data represents.
Data Ensembles
The main unit for organizing and managing multifaceted data sets in Predictive Maintenance Toolbox™ is the data ensemble. An ensemble is a collection of data sets, created by measuring or simulating a system under varying conditions.
For example, consider a transmission gear box system in which you have an accelerometer to measure vibration and a tachometer to measure the engine shaft rotation. Suppose that you run the engine for five minutes and record the measured signals as a function of time. You also record the engine age, measured in miles driven. Those measurements yield the following data set.
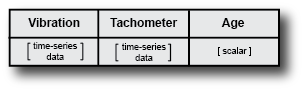
Now suppose that you have a fleet of many identical engines, and you record data from all of them. Doing so yields a family of data sets.
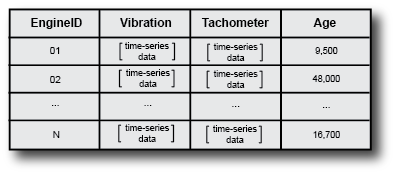
This family of data sets is an ensemble, and each row in the ensemble is a member of the ensemble.
The members in an ensemble are related in that they contain the same data variables. For instance, in the illustrated ensemble, all members include the same four variables: an engine identifier, the vibration and tachometer signals, and the engine age. In that example, each member corresponds to a different machine. Your ensemble might also include that set of data variables recorded from the same machine at different times. For instance, the following illustration shows an ensemble that includes multiple data sets from the same engine recorded as the engine ages.
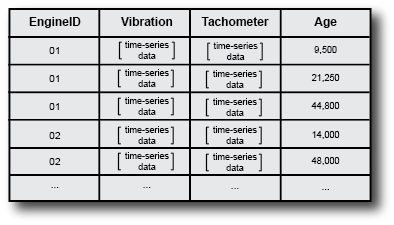
In practice, the data for each ensemble member is typically stored in a separate data file. Thus, for instance, you might have one file containing the data for engine 01 at 9,500 miles, another file containing the data for engine 01 at 21,250 miles, and so on.
Ensemble Variables
The variables in your ensemble serve different purposes, and accordingly can be grouped into several types:
Data variables (DV) — The main content of the ensemble members, including measured data and derived data that you use for analysis and development of predictive maintenance algorithms. For example, in the illustrated gear-box ensembles,
VibrationandTachometerare the data variables. Data variables can also include derived values, such as the mean value of a signal, or the frequency of the peak magnitude in a signal spectrum.Independent variables (IV) — The variables that identify or order the members in an ensemble, such as timestamps, number of operating hours, or machine identifiers. In the ensemble of measured gear-box data,
Ageis an independent variable.Condition variables (CV) — The variables that describe the fault condition or operating condition of the ensemble member. Condition variables can record the presence or absence of a fault state, or other operating conditions such as ambient temperature. In the ensemble gear-box data,
sensor healthmight be a condition variable whose state is known for each engine. Condition variables can also be derived values, such as a single scalar value that encodes multiple fault and operating conditions.
Data variables and independent variables typically have many elements. Condition variables are often scalars. In the app, condition variables must be scalars.
Representing Ensemble Data for the App
You can use one of three general approaches to combine your ensemble data and import it into the app. All these approaches require that your ensemble members all contain the same variables.

Create Individual Member Data Sets
Import your data in the form of individual data sets — one for each member — and let the app combine these data sets into an ensemble. When you select one of the member data sets in during the import process, the app displays all the data sets in the workspace that have the same variables, and are therefore compatible.
This approach requires the least setup before importing the data. If you want to update the ensemble with new members, you must import all members again.
Create an Ensemble Data Set
Import a single ensemble data set that you create from your member data sets. Each row of your ensemble data set represents one of your members.
This approach requires more setup before importing the data. It can be more practical than the individual approach when you have larger member sets. If you want to update the ensemble with new members, you can do so outside of the app by adding to your existing table. Then import the updated table.
For an example on creating an ensemble data set from individual member matrices, see Prepare Matrix Data for Diagnostic Feature Designer.
Create an Ensemble Datastore Object
Import an ensemble datastore object that contains only the names and paths of member files rather than importing the data itself. This object also includes the information needed for the app to interact with the external files.
This approach is best when you have large amounts of data and variables. Ensemble datastores can help you work with such data, whether it is stored locally or in a remote location such as cloud storage using Amazon S3™ (Simple Storage Service), Windows Azure® Blob Storage, or Hadoop® Distributed File System (HDFS™).
Typically, when you begin exploring your data in the app, you want to import a relatively small number of members and variables. However, later, you might want to test your conclusions on feature effectiveness by bringing in a larger sample size. The ensemble datastore is one method for handling the larger amount of data, especially if the data size exceeds memory limitations for MATLAB®.
For more information on ensemble datastore objects, see Data Ensembles for Condition Monitoring and Predictive Maintenance.
Data Types and Constraints for Data Set Import
The app accepts various data types, including numerical matrices and tables that contain condition-variable scalars and embedded measurement timetables.
Before importing your data, it must already be clean, with preprocessing such as outlier and missing-value removal. For more information, see Data Preprocessing for Condition Monitoring and Predictive Maintenance.
For detailed information on data types and constraints, and on the actual data import, see Import Data into Diagnostic Feature Designer.
See Also
table | timetable | fileEnsembleDatastore | simulationEnsembleDatastore